MTCNN论文
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Senior Member, IEEE, and Yu Qiao, Senior Member, IEEE 联合 人脸 检测 与 对齐 使用 多任务 discrete 英/dɪˈskriːt/ 美/dɪˈskriːt/ adj. 离散的;分离的;各别的;互不相连的 也可以理解为串联,所串的事物是不相关的 物体检测:类别,概率,框, - 类别:有哪些种类的物体 - 概率:每类的概率多少 - 框:两个框的offset 人脸对齐:眼睛,鼻子,嘴角 五点定位 二分类器解决多类别的问题
一个模型判断一个事物,有多少类别,就训练多少个模型
模型1,输入一张图像数据,判断是否含有事物A,
模型2,输入一张图像数据,判断是否含有事物B,
...
...
...
机器学习要求很强的数学能力,
深度学习要求灵活解决问题的能力
重在思想,思想可以联接二者,思想可以联接一切...学科
物体检测多分类
MTCNN,或者说物体检测,是一次分出多个物体类别,并且还可以给物体加上框
|
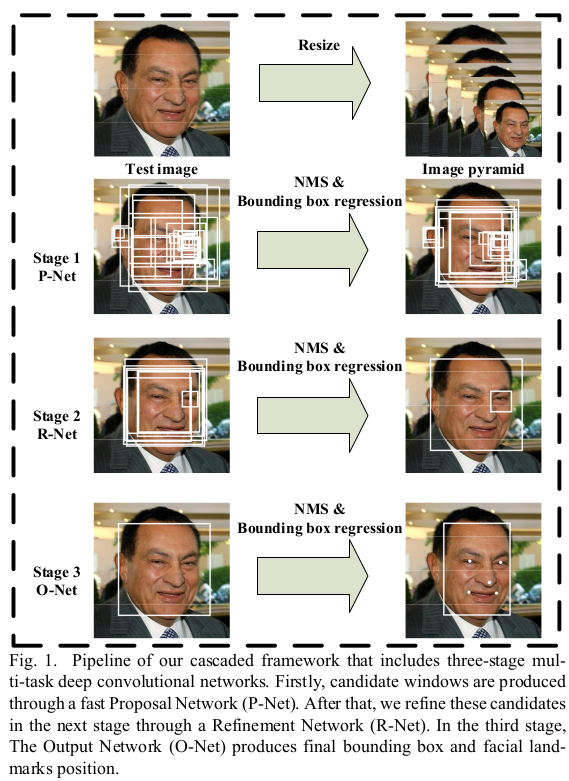
resize的目的
模型输入固定,图像resize成一系列比例的图片
- 因为不知道图像上哪些地方有人脸
- 也不知道人脸的大小,是小脸还是大脸
- 因此,将输入的图片resize成一系列大小的图片
- 如果整个图片都是人脸,那么它只有resize成小图片,即与框差不多的大小的图片时,才能被检测出来
- 如果人脸是图片上的一小块,那么它只有resize成大图片,然后切片出的小图片,与框匹配才能检测出来
小图检测大脸
大图检测小脸
切图之P-Net
P-Net对切图后的小图片进行判断
- 这些小图片从原始图片resize后的图片上切
P-Net的判断非常简单
- 切图后生成了大量的图片,大部分是背景,背景与人脸的区别还是比较大的
- P-Net 就是用简单的办法,去除哪些不怎么像人脸的背景
- 处理后的结果,包含了人脸,也包含了有点像人脸的图片
可以认为第1阶段排除了那些根本不可能的数据,且是用非常简单的方法进行的排除
|
P-Net 切图+初筛 先宁可错选也要多选,然后 初步筛选 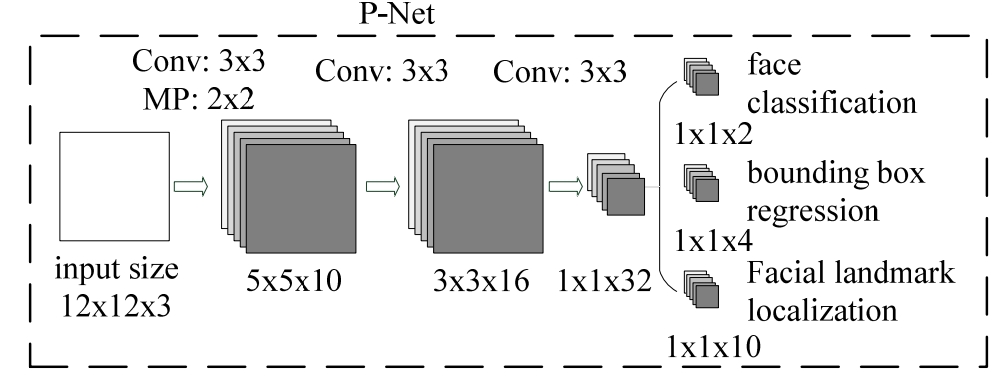
NMS: 非极大值抑制,抑制的是得分低的预测框,涉及到两个指标, IOU(交并比:两个框的重叠区域面积与两个框并集面积的比值)和预测框得分, 若有多个预测框预测的是同一个物体,若两个框的IOU值大于阈值(一般阈值取0.5和0.7), 那么NMS算法将会把得分低的预测框丢弃。 参考 【深度学习】——物体检测细节处理(NMS、样本不均衡、遮挡物体) 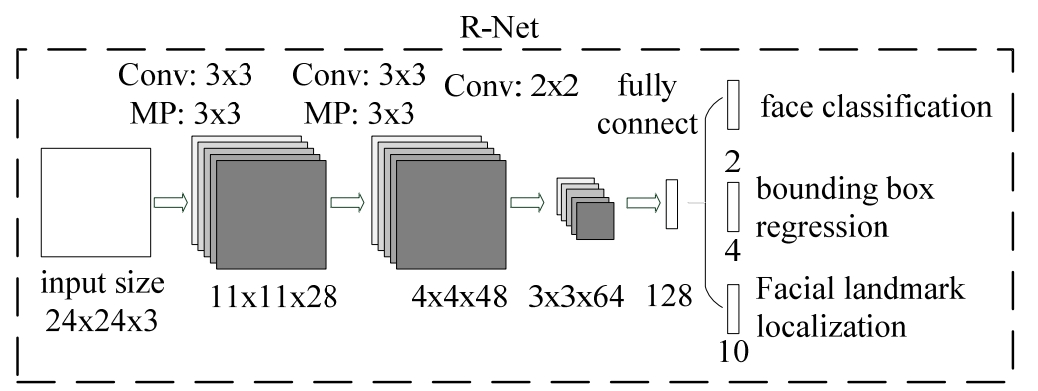
R-Net 精修 - 不同于PNet用使用卷积,RNet最后使用了全连接 O-Net 精修+五点定位 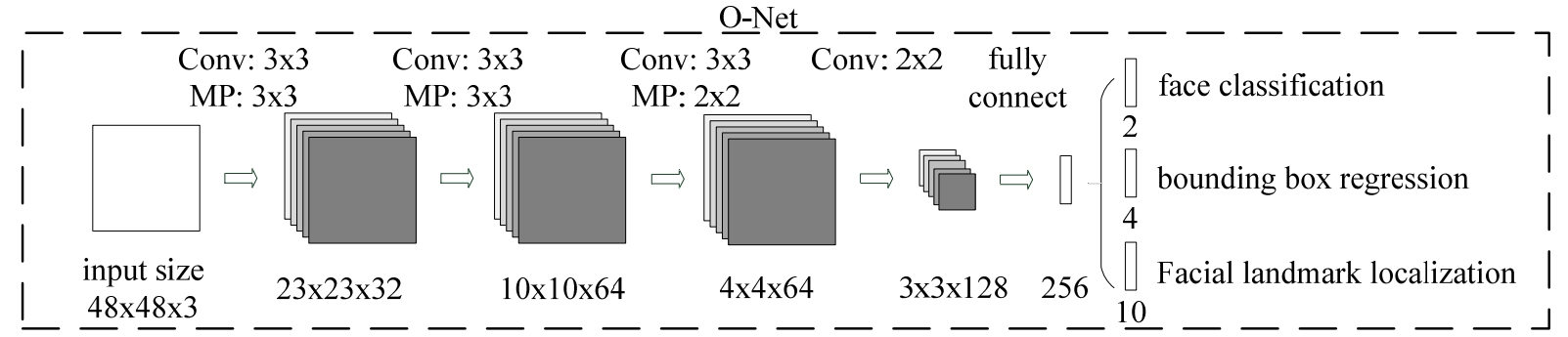
|
|
框的设计 模型设计一个固定大小的框,12*12 图片按固定的比例,比如0.9开始缩放,至到最小的框接近12*12 - 如果该图片上只有一个人脸,且人脸挤满整个图片的话,这张图片收缩至12*12后,刚好与模型框匹配 - 如果该图片上的人脸比较小,收缩到12*12后,人脸特征几乎消失,将被模型判断为非人脸 - 这就是小图匹配大脸 - 然后是比12*12稍微大点的,按12*12的尺寸切图,必定能切中人脸, - 因为该图片就比12*12大了一圈,可是切出了多个12*12尺寸的图片 - 再大点,再大点...一点点增大,但切图全是12*12,这样逐渐增大,必定能切中所有的人脸 如此切图逻辑,所有的图片都在12*12的图片上,只是不同图片的缩放比例不同 切图大小是12*12,那后面的24*24,48*48是怎么回事? 图片是经过缩放的,即所有数据计算的是比例,这意味着同样可以应用到原图上 原始图片上的标注框对应的是原图的坐标位置,中间处理全部转化为比例 - 比如,x/宽度,y/高度 12*12大小的图片进入模型之后,输出概率与框的偏移率 - 确定该图片为人脸,转换后比例后, - 实际上确定的是图片上某个比例处,比如图片左上角宽30%,高40%的位置有个人脸 - 24*24是以这个位置为中心,稍微扩大一点范围,取的图片 - 48*48的图片也是如此,只是多了五个位置偏移率的计算 |
|
|
MTCNN总体思路
任务分析 -------------------------------- 1. 判断一张图片是否为人脸 2. 在图片人脸部分画上一个框 3. 标注眼睛,鼻子,嘴角 数据集采集与构建 -------------------------------- 针对任务1: 将任务简化为判断一张图片是不是正面人脸, 故,数据集的正样本要采集人的正脸图片 针对任务2: 提前在人脸图片上,在人脸部位画个框 针对任务3: 在人脸图片上眼睛,鼻子,嘴角部分 标注个点 数据集采集 由以上条件,真实采集的数据集是这样的: N张图片,每张图片都是包含人脸的, 并且是人的正脸,就是面向镜头的正脸, 可以是头像,或上半身图像,或全身图像, 关键是每张图片的脸都是正脸,正脸,正脸... 为什么非要是正脸? AI还不知道什么是人脸呢,你就拿一个侧脸让它判断,这不是为难它,是为难自己了... 每张图片上没有画框,但都对应一个标注文件, 里面记录人的正脸部分的框的坐标,以及眼睛,鼻子,嘴角的坐标 由 模型需要 决定的数据处理及损失函数设计 -------------------------------- 任务1: 判断是否为人脸, 根据标注文件中人正脸的坐标, 去原图片上把图片扣下来, 再抖一下,就有人脸的正负样本了 任务2: 由任务1得到一张人脸的图片,这实际上就是当初的标注框内的图片 怎么让程序框学习这个框呢? 不做处理是没办法了,因为现在的人脸就是当初的框,100%的正脸 要处理就得将一个问题再细化一些 当初的人脸标注框,实际上大多框的人的头像,把耳朵,头发,脖子也给框进去部分 除了这个外,有的框还把背景框进去一部分, 也就是说,得到的人脸图片,虽然一眼看过去是个人脸,但又不完全是人脸 于是新的任务就出来了:找到这张图片上,真正人脸的位置,记为box1 将原来标注框按一定比例收缩一圈,这样得到的图片为新任务的正样本, 这基于数据采集的一个标框前提,框的中心,就是真实的人脸 再科一下,得到的图片为新任务的负样本box2 这里负样本计算的是抖动后的图片box2相对box1的偏移率, 偏移率 = (box2 - box1)/box1的最大边长 损失函数设计为让这个偏移率逼近0 - 这就是一个学习过程,让AI认识到什么是正脸 - 同时,对于接近正脸的事物也进行学习,比如侧了10%的样子是什么,侧20%的样子又是什么 - 对于周边事物的认识也有利于AI判断真正的正脸 任务3: 由任务2得到了box2, 损失函数设计为让 原五点坐标相对box2的偏移率2 逼近 原五坐标相对box1的偏移率1 |
|
原始数据集 原始图片上做人脸框标注,并记录框的坐标 数据转化 正负样本生成 - 取标注框,收缩10%为正样本, - 抖动一下,重叠度低于一定阈值为负样本 框的偏移率 - 转化为框的四个点x,y坐标的偏移率 - (x1-x2)/x1 - 如此,生成的每个图片都带了一个偏移率 - 因为图片是按不同比例缩放的,偏移率也是使用比例计算,与切图在原图片上的偏移率一致 新的数据集是标注框附近的切图+框的偏移率 |
|
训练 训练是并行的,得同时准备一堆12×12,24×24,48×48的图像, 让模型学习什么是人脸 及 偏差多少以内仍算人脸 并在此基础上进一步确定 眼睛,鼻子,嘴角 这个觉得耳朵也是一个很好的边界,添加一下耳朵效果可能会更好 预测 预测是串行的,先PNet,后Rnet,最后Onet,前一个网络的输出,是后一个网络的输入 |
|
|
|
|
单图多分类
使用卷积网络进行单图多类任务
卷积提取图像特征 全连接分类 最后一层全连接输出的维度是总类别个数,每个元素值为 输入图像对应类别的概率 针对异常处理,比如你输入了一张从未训练过的图像类别进行预测, 这个类别不在已有的任何类别当中, 针对此类异常情况,可以在训练的时候在类别中加入一个others类别, 将无法识别的,异常的定位到others
切图技巧
|
框的形状与大小占比
模型框的形状与物体的形状越接近越好
模型框的大小转化为模型框占图像的比例
- 一个思路是图像不变,调整模型框的占比
- 一个是模型框大小不变,对图像的大小进行resize
- 如果一个图像收缩,那么框不变的情况下,可以对大物体分类
- 如果图像不收缩,框不变的情况下,可以对小物体分类
模型输入图像大小与切图大小的转换
模型输入规定 24*24
实际切出的人脸为11*13,其中一种做法如下:
- 以11*13图像的中心点为中心
- 11两边各扩展1,形成13*13像素的图片,中心点不变
- 再resize为24*24的图像
- 如此,图像不会变形,同比扩大
|
|
模型输入图片大小固定且统一,故事物图像从原图上取下来后要resize 第一次:图片派生 ---------------------------------------------------- 将图像按比例缩小,在这个过程中取一系列图片 原来有N张图片,假如一个图片缩小10次,最后得到10N张图片 通常下一次是这一次的70%,直到图像缩小到特定的尺寸; 如果不怕速度慢,以速度换精度,收缩比例可以一次90% 因为大图在缩小过程中,小物体消失了,所以 由缩小得到的小图 只能检测出有没有大物体 滑动取框 第二次:窗口切图 --------------------------------------------------- 窗口设计: 正方形,横/竖长方形,三个,每个设计多个尺寸,得到一系列窗口 当然了,也可以只用方框 ,这取决于要判断的事物的形状 切图: 使用设计的窗口得到一系列图片,划动切图,得到一系列图片 在原图上使用窗口划动,只要窗口设计合适,每次步长不大,必定能圈住小物体 经过这两次操作,大物体转移到小图片了, 小物体存在于一堆由窗口划动切割的小图片中, 所以最终不管是大物体还是小物体, 都存在于最后得到的一堆小图片中了 如果等差数列的方式切框的问题 - 优点是框的数量少 - 问题是会出现框切不到完整物体的情况 卷积切框 - 优点是可以切中物体 - 缺点是切一个框移动一点点,最后出现大量的无用的框 切框的本质 - 将连续的无限的信息转化为离散的有限的信息, - 这是模拟信号转化为数字信息的基本方法,就是短时傅立叶变换的思想
切图得到一张张固定大小的图片,开始学习,学习的内容主要有
- 是不是人脸
- offset是多少
- 一个人脸图片,由于切图原因的不完整(提前是拍摄角度是正脸且无遮挡...)
- 不管什么原因,通过offset来衡量这张人脸的完整度
- offset越小,那么该人脸图像就越接近原图像,它就越完整
核心思想
--------------------------------
会切出很多的图,宁可错选1000,绝不遗漏1个;逐窗切图,暴力计算...
MTCNN切图的框只有一种,所以切出来的图的大小,也只有一种12*12,
MTCNN没有设计矩形的框,即那些长条形的框,
因为MTCNN是针对人脸,人脸大部分是正方形,
这是由具体的任务-人脸识别决定的
如果检测的物体不只一种,形状各异,那就得正方形,横竖矩形都有,
甚至你检测的物体是个类三角形,你就得设计一个三角形的框
虽然都叫MTCNN,但不同的业务调整过的MTCNN设计的细节是不一样的:
框的形状
速度与性能的平衡
|
|
|
|
|
|
|
P-Net
|
一张图片上有大量的背景,按前面的切图法,会切出大图的背景图片 Stage1 P-Net: 切图+粗选 输入:12×12×3,实际可以输入任意大小的图片,因为P-Net没有要求输出的shape 第1层:3×3卷积+maxpool提取特征 第2层:3×3卷积 第3层:3×3卷积 图片分类:是否人脸 偏差计算:如果是人脸,则计算标签人脸的框 与 模型输入的切割后的小图片,在原图上位置的 偏移率
现在深度学习网络层数较多,三层卷积就能提特征的情况还是比较少
关键是效果要好才行
输入:12*12的图像,大部分都不是人脸 输出: - 是否人脸及偏移量 - 在是人脸的情况下,再加一个偏移量 - 一个12*12的图像是人脸,但可能不是100%与原人脸的图像重合 - 需要在原图像上,上下左右移动一下,这就是偏移量 - 如果完全重合,那么偏移量为0 - 输出的人脸图片+偏移处理,这样得到的图片, - 就去除了大部分非人脸图片,同样向着完全的人脸靠近了一些 - 框+偏移量之后,得到的框就不再是正方形了,所以后面RNet处理时,重新resize
|
import torch
from torch import nn
class PNet(nn.Module):
def __init__(self):
super(PNet, self).__init__()
self.pre_layer = nn.Sequential(
# 第1层卷积
nn.Conv2d(in_channels=3,
out_channels=10,
kernel_size=3,
stride=1,
padding=0),
nn.BatchNorm2d(num_features=10),
nn.PReLU(num_parameters=10, init=0.25),
# 最大池化
nn.MaxPool2d(kernel_size=2, stride=2),
# 第2层卷积
nn.Conv2d(in_channels=10,
out_channels=16,
kernel_size=3,
stride=1,
padding=0),
nn.BatchNorm2d(num_features=16),
nn.PReLU(num_parameters=16, init=0.25),
# 第3层卷积
nn.Conv2d(in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=0),
nn.BatchNorm2d(num_features=32),
nn.PReLU(num_parameters=32, init=0.25)
)
# 输出人脸的概率 bce
self.conv4_1 = nn.Conv2d(in_channels=32,
out_channels=1,
kernel_size=1,
stride=1,
padding=0)
# 输出人脸的定位框的偏移量(误差)
self.conv4_2 = nn.Conv2d(in_channels=32,
out_channels=4,
kernel_size=1,
stride=1,
padding=0)
def forward(self, x):
x = self.pre_layer(x)
cls = torch.sigmoid(self.conv4_1(x))
offset = self.conv4_2(x)
return cls, offset
输出有二:一个分类,一个回归,回归是一个数 face classification :2分类,1*1*2 ,使用sigmoid映射到[0,1] bounding box offset regression :1*1*4,一个框4个顶点,4个回归值 |
|
核心代码
# 输出人脸的概率 bce
self.conv4_1 = nn.Conv2d(in_channels=32,
out_channels=1,
kernel_size=1,
stride=1,
padding=0)
# 输出人脸的定位框的偏移量(误差)
self.conv4_2 = nn.Conv2d(in_channels=32,
out_channels=4,
kernel_size=1,
stride=1,
padding=0)
凭什么conv4_1就是概率,conv4_2是偏移率 ? 它们最初是随机初始化的,一开始的时候的确什么也不是 - 计算之始,它们确定了一个输出的形式 - 概率输出一个数值 - 偏移率是框四个点的偏移率,所以输出4个值 它们将来会具有什么样的业务含义,完全是由损失函数设计决定的 - 使用损失函数衡量它们与标签之间的差异 - 梯度下降法不断修改模型参数,使模型的输出不断向标签靠近 - 如此,模型的输出才慢慢具有了业务含义 ,才是概率,才是偏移率... kernel_size=1, stride=1, padding=0 每次计算一个元素,然后计算下一个元素,这就是全连接的功能 但如果换成全连接,在API上就必须填写输入的维度, 卷积就不需要填写这个,只填写通道数就可以了, 这意味着最后一层的特征图的维度可以是随意的, 即意味着输出的图形的形状也不固定,是随意的 更具体地说,是可以随着输入的不同而变化的, 而不是像最后一层加全连接的网络那样,输出的格式是固定的 |
|
|
|
|
R-Net
Stage1 P-Net处理过的图片先按其最长边长 resize为正方形, 再resize为24*24*3的图片 输入:24×24×3 第1层:3×3卷积+maxpool提取特征 第2层:3×3卷积+maxpool提取特征 第3层:2×2卷积 第4层:全连接 图片分类:是否人脸 偏差计算: - 如果是人脸,则计算标签人脸的框 与 模型输入的切割后的小图片,在原图上位置的 偏移率 - 不是人脸的,就不用计算偏移率了,节省了计算资源 - 前一步的误判,即不是人脸的图片被判定为人脸时,在偏移率计算时会被处理掉
O-Net
一系列卷积操作后 图片分类:是否人脸 偏差计算: 如果是人脸,则计算标签人脸的框 与 模型输入的切割后的小图片,在原图上位置的 偏移率 五点定位: 眼睛,鼻子,两个嘴角,在定位的过程中,也会消除一系列R-Net产生的错误框 计算五点相对模型框左上角的偏移率 对于一个人脸识别任务,只需要判定是否为人脸就可以了 但该算法有更高的追求,还要判断出眼睛鼻子, 虽然任务本身没要求,但却在这一过程中提高了人脸识别的精度 这也为精度的提高提供了一条思路 - 当某个层面上事情无法精进时,可以去比它更高的一层上探索 - 好像...很多事就是如此,这也算理论转算法的一个实践了...
|
Stage1 R-Net处理过的图片先按其最长边长 resize为正方形,再resize为48*48*3的图片 |
|
|
|
|
|
|
设计思路
1. 找正脸图片, 因为人脸识别的时候都要求你正对镜头,所以数据集要收集正方向的人脸, 要找的人脸图片是人的半身或全身图片,然后让程序去学习什么是人脸 2. 人脸图片坐标标注 2.1 在原图上用正方形框 框住人脸,记录的是框左上角与右下角的坐标 2.2 五点标注,两个眼睛,鼻子,两个嘴角,记录的是这五个点的坐标 2.3 图像左上角的坐标是(x,y)=(0,0),横/宽方向是x轴,竖/高方向是y 2.4 在图像收缩到12*12大小时,(x,y)坐标同比收缩,这样所有标记坐标就统一了尺度 2.5 也就是说,最终的入模型的数据是百分比,范围正常情况下0-1 3. 分类任务 取人脸部位图像的小正方形,得到一堆小正形人脸图片,单个小正方形的主体内容就是一张人脸, 让AI从整张图片上学习哪些特征是人脸,所以要先告诉AI哪些特征是人脸, AI学习之后就能分辨一个小图片是不是人脸, 这一步就是让AI拥有识别人脸的能力 这是人脸分类任务,判断一张图片是不是人脸 这里只有正面人脸,即正样本,即只有一个类别,分类任务至少要两个类别 我们对本任务进行分析: 我们要的w人正脸图片,这是正样本, 如果镜头偏了一点,或者人稍微偏了一点,那算不算人脸? 这里我们定下一个标准,本任务是人脸识别,就定下重叠50%的算,其他的都不算 这个其他的也包括了背景图,即不是人的部分 分类任务不涉及坐标计算,单纯的就是判断一张图是不是人脸 4. 框的误差 输入一张图片,是一个人的全身图片,我们期望它能把人脸的位置框出来, 程序从原图取下来的一系列小图片,同时记录了它在原图的位置, 然后对每个小图片进行是否人脸判断, 如是人脸,就能根据位置记录,回溯到原图,然后画个框... 这个框就是告诉人们,看,我找到你了... 但有点偏... 于是就有了第二个任务,框的误差计算 标注的时候记录过人脸框的左上右下坐标,后来转为了图像的百分比,即0-1之间的数, 由人脸分类任务,判断出这是一张人脸,这张图片也记录了左上右下坐标,也转成了0-1的数, 标注框与得到有人脸的框 坐标误差越小,框的越准, 设计一个损失函数计算框的误差,随着不断迭代,框的准确度就会不断提高 5. 模型输入进一步分析 P-Net 输入的12*12的图片 将切图后的图片全部转为12×12的图片,然后输入P-Net模型, 12×12图片很小,比芝麻大点,比绿豆小点,差不多就这样 , 这些小图有是人脸,有不是的,有一部分是的, 前面我们定了个重叠大于50%的就是人脸这么一个标准, 所以P-Net判断出的人脸的图片,有一些图片只是人脸的一部分, 另一部分超出了当前图片12×12的范围, 这些小图片都是带着原图的坐标的, P-Net下一步是R-Net,它的输入是24×24 R-Net输入的24×24是根据P-Net在原图上的坐标,直接从原图上取的24*24 P-Net只有三层卷积,12×12又是很小的图片, 粗粒度的计算又加上图片的高度收缩,信息丢失很多, 但由于定位是人脸的标准很低,重叠50%就算,宁可错选1000,也不遗漏1个, 也就是说,P-Net把图片上看上去稍微像点人脸的区域坐标都给取下来了, 而R-Net是从原图上取的坐标,这样取到的图片就弥补了P-Net信息丢失的缺陷, 这么一来,信息就丢失就很少了, R-Net对这些包含一些人脸的图片以稍微高点的标准判断一下是不是人脸, 得到的图片就比较迫近标签标注的人脸图片了 根据R-Net得到的比较接近人脸的区域坐标, 再扩大四倍范围,从原图上取48×48区域,就是O-Net的输入, O-Net不仅定位了人脸的框,还进行了更加细化的五点定位, 6. 坚持至简 我们知道有些问题本层面方法是无法很好解决的,怎么搞就只能解决90%的问题, 但若你再上升一个层面,虽然更高层层面的方法解决更高层面的问题只能解决80%, 但对来对付低一个层面的问题,却能解决其95%, 并且是轻松解决,不是当初费了九牛二虎之力才提升了1%的精度, O-Net就有这样的一种思想, 你看它的网络设计,都是非常简单的,没有很深的层数, 也没有很高大尚的 类似图像金字塔 涉及傅立叶变换等 这样高深莫测的事物 简单的组合之后, 仅凭这三个网络就已经可以名扬天下了(即使没有最后的五点定位), 但发现最后的精度不是很高,或者说没有达到让当时的人们感觉到震撼的程度, MTCNN的解决办法不是去复杂化一个简单的网络(这才是解决问题的首先想到的思路), 而是在人脸分类还没搞好的情况下,直接去定位眼睛,鼻子.... 本层面简单方法解决不了的问题,就去找高一个层面的简单方法... 像不像古代有些人,自己温饱问题还没解决,房子媳妇还不知道在哪,脑子里天天想的却是天下大事... 实际上,若是你真能解决一个天下大事,前面的都不叫事了... 五点定位的计算方法也不并复杂,但直接提高了人脸分类的精度, 即把那些本不是人脸区域 却误判为人脸的框 给消除了
划框理论
MTCNN要解决的两大问题: 1. 分类 2. 定位 首先程序通过训练集已经学习过了,有了区分物体的能力 以框切图来分类: 这个框要与检测的物体样子差不多,不能相差太远 滑动取框,切出一系统数据集,分正负两类样本,用于训练/预测 可以将这个过程看作一个实时动态分类的过程, 每切出一个框就可以判断它是不是要检测的物体, 同样的,用滑框理论检测信号波,识别语音也是可以的 框的合并: 如果同样包含一个物体的两个框重叠度比较高,可以进行合并 这样框的数量会大量减少, 因为滑框的步长比较小, 这就导致一个物体附近必定存在多个包含该物体的框
损失函数设计
图像偏移率
通过图像增强生成一系列新的图像,记录这些新图像在原图上的坐标,这里记为新坐标 (原坐标 - 新坐标)/ 新的最大边长 = 偏移率 所有点的 偏移率之和 就是 损失函数 损失函数的目标是 让程序框到的图像 离 真实标签框的图像 的偏移率 越来越小 如此,程序框 就逐渐逼近 标签框 了
损失目标与数据集构建
MTCNN 是多任务,这里有三个损失函数 1. 图像分类,是否有人脸 2. 框的损失,目标是程序框逼近标注框 3. 五点定位,目标是程序点逼近标注点 图像分类: 二分类问题,先从原图像上切出一系列固定大小的图像,然后确认其是不是人脸 切图时,要生成了正样本,标注为1,表示是有脸,负样本标注为0表示不是人脸, 将这些数据扔进几个net训练一下,就有分类的能力 框的损失: 标注框就是提前画好的框,目的在于让AI学习 图像上哪些位置是有人脸 程序框与标注框的差,偏移率 这两个值都能反应损失的大小 但由于人脸在不同的照片上缩放程序不一样,就导致其视觉大小也不一样 所以选择偏移率来作为损失函数,让程序框 偏移 标注框 的比例接近0 是任务目标 那怎么制造/生成 一批 数据/图像 让AI学习这个偏移率呢?这是一个连续型数值 标注图像记录下图像的名称,高与宽,框的坐标,这是原始的标注信息 使用图像增强,就是让标注框抖动一下,生成一批框,记录下新框的位置,相对标注框的偏移率 轻微抖动表示偏移率很小,是任务需要的,抖动过大的,就是负样本,舍弃不要, 因为我们的目标是学习什么是人脸, 就是给了大批量的偏移率小的场景让任务去学习, 偏移率越小,框的就越准确 五点定位: 眼睛,鼻子,两个嘴角,是在人脸的基础上标注的,是相对人脸坐标的一个位置 定下人脸,五点的位置就是一个相对位置, 同样的,具体的相对坐标大小,不如相对偏移率更合适 但以哪个位置为标准呢?可选的有,框的左上,右下,中心 可能是因为图像的原点坐标就是左上, 所以,五点定位的起点就是框的左上角(x0,y0) 以鼻子为例(x1,y1),偏移率计算如下: (x1-x0)/max_size为宽方向上的相对偏移率 (y1-y0)/max_size为高方向上的相对偏移率 各个单维度上计算,然后再组合回二维 标注框中五点偏移率是个比值, 就鼻子而言, 它学习到的可能就是人脸框 宽方向二分之一处, 高方向大概也是二分之一就是鼻子了吧
损失函数设计
分类任务损失函数可以选择交叉熵 针对这里的二分类问题,可以选择BCE 回归问题,MSE
参考