DL大纲
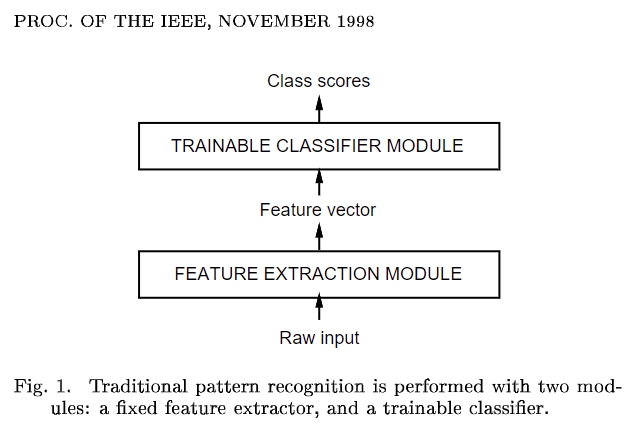
Raw input :原始数据 Feature Extraction Module : 特征提取/抽取模块,就是当前的模型要完成的功能 Feature vactor: 特征向量,可用于分类的特征向量 Trainable Classifier Module : 可训练的分类器,就是现在的分类层 机器学习数据特征提取,靠人工 深度学习数据特征提取,Feature Extraction Module,由神经网络(即模型)提取 - 但这并不是说,深度学习就不能人工提取特征了 - 对于一些交易场景,有其独特的业务含义, - 人工特征的提取是有助于神经网络推理的 - 但机器学习是一定需要人工提取特征的 然后通过全连接映射到业务的类别上 - 2分类映射到2维向量上 - n分类映射到n维向量上 深度学习输入数据,比如一张图像,然后映射到某个类别上 深度学习 原始数据 -- 模型 -- 分类 -- 标签类别 机器学习 原始数据 -- 特征工程 -- 模型 -- 标签类别
|
|
深度学习灵魂三问:
输入是什么?
输出是什么?
试图实现什么操作?要赋予网络什么样的功能?
|
|
图像分类模型 LeNet AlexNet VggNet InceptionNet ResNet |
|
深度学习的本质 矩阵相乘,线性变换 要清楚不同维度代表的含义,即矩阵shape的业务含义 |
concat 拼接 -- InceptionNet add 相加 -- ResNet |
LeNet网络设计
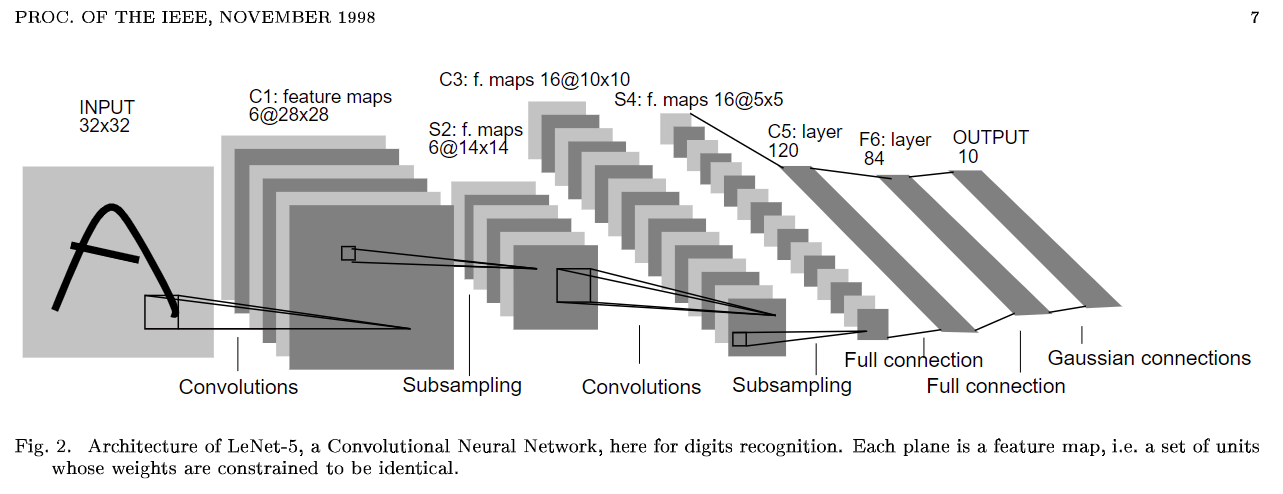
输入输出 - 输入是原始数据,一张图片,[B,1,32,32] - 输出是10个类别的向量 特征提取 - 卷积改变特征数,逐渐变大, 1 -- 6 -- 6 -- 16 -- 16 - 特征图下采样,图形逐渐变小 ,32-- 28 -- 14 -- 14 -- 5 分类 - 按批次展平,一张图片的数据展平为一个向量,全连接映射到类别 下采样 每四个格取一个 - 每隔一个取一个 :方式有些古板 - 随机取一个 - 平均值 :信息丢失最少 - 最小值 - 最大值 这也是池化层的操作, - 池化层无参数,只是一种计算方式 - 池化不改变特征层/数,只是一种下采样方式,收缩的是特征图的大小
|
|
LeNet论文复现
import torch
from torch import nn
from torch.nn import functional as F
class LeNet(nn.Module):
"""
定义一个LeNet
"""
def __init__(self):
super(LeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu1 = nn.ReLU()
# 2
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu2 = nn.ReLU()
# 展平层
self.flatten = nn.Flatten()
# 分类层,这一步输入的特征数是上一步向量的特征维数,是固定的
self.fc1 = nn.Linear(in_features=576, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=10)
def forward(self,x):
# [B, 1, 32, 32] --> [B, 6, 30, 30]
x = self.conv1(x)
# [B, 6, 30, 30] --> [B, 6, 15, 15]
x = self.pool1(x)
x = self.relu1(x)
# [B, 6, 15, 15] --> [B, 16, 13, 13]
x = self.conv2(x)
# [B, 16, 13, 13] --> [B, 16, 6, 6]
x = self.pool2(x)
x = self.relu2(x)
# [B, 16, 6, 6] --> [B, 576]
x = self.flatten(x)
# [B, 576] --> [B, 256]
x = self.fc1(x)
# [B, 256] --> [B, 128]
x = self.fc2(x)
# [B, 128] --> [B, 10]
x = self.fc3(x)
return x
batch_size = 32 #批次 features = 1 #黑白图片 img_h = 32 #高32个像素,就是32个特征 img_w = 32 out_feature = 10 #10分类问题,输出10个特征 data = torch.randn(batch_size,features,img_h,img_w) lenet = LeNet() lenet(data).shape #torch.Size([32, 10])
|
|
数据集 使用封装好的 手写数字数据集
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import datasets
from tpf.params import ImgPath
from tpf import pkl_load,pkl_save
# 数据加载测试
class MyDataset(Dataset):
"""手写数字数据集
"""
def __init__(self, fil):
"""超参数初始化
"""
self.img_list = pkl_load(file_path=fil)
def __getitem__(self, idx):
"""读取图像及标签
"""
return self.img_list[idx][0], self.img_list[idx][1]
def __len__(self):
"""数据集大小
"""
return len(self.img_list)
train_dataset = MyDataset(fil=ImgPath.mnist_data_train)
print(len(train_dataset)) # 60000
test_dataset = MyDataset(fil=ImgPath.mnist_data_test)
print(len(test_dataset)) # 10000
# 训练集加载器
train_dataloader = DataLoader(dataset=train_dataset, batch_size=512, shuffle=True)
# 测试集加载器
test_dataloader = DataLoader(dataset=test_dataset, batch_size=512, shuffle=False)
# 1个批次512个样本,一个像素用一个数值表示,shape为[32,32]
for X,y in train_dataloader:
print(X.shape,y.shape) #torch.Size([512, 1, 32, 32]) torch.Size([512])
break
# 是否有GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
class LeNet(nn.Module):
"""
定义一个LeNet
"""
def __init__(self):
super(LeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu1 = nn.ReLU()
# 2
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu2 = nn.ReLU()
# 展平层
self.flatten = nn.Flatten()
# 分类层,这一步输入的特征数是上一步向量的特征维数,是固定的
self.fc1 = nn.Linear(in_features=576, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=10)
def forward(self,x):
# [B, 1, 32, 32] --> [B, 6, 30, 30]
x = self.conv1(x)
# [B, 6, 30, 30] --> [B, 6, 15, 15]
x = self.pool1(x)
x = self.relu1(x)
# [B, 6, 15, 15] --> [B, 16, 13, 13]
x = self.conv2(x)
# [B, 16, 13, 13] --> [B, 16, 6, 6]
x = self.pool2(x)
x = self.relu2(x)
# [B, 16, 6, 6] --> [B, 576]
x = self.flatten(x)
# [B, 576] --> [B, 256]
x = self.fc1(x)
# [B, 256] --> [B, 128]
x = self.fc2(x)
# [B, 128] --> [B, 10]
x = self.fc3(x)
return x
model = LeNet()
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.Adam(params=model.parameters(),lr=1e-3)
epoch = 1
for i in range(epoch):
for X,y in train_dataloader:
#模型正向传播
y_pred = model(X)
#损失函数梯度清空后,反向求导
optim.zero_grad()
loss = loss_fn(y_pred,y)
optim.step()
break
y_pred
tensor([[-0.0286, -0.0236, 0.1188, ..., 0.0632, 0.1109, 0.0093],
[-0.0314, -0.0266, 0.1238, ..., 0.0644, 0.1135, 0.0147],
[-0.0187, -0.0252, 0.1177, ..., 0.0884, 0.1284, 0.0191],
...,
[-0.0311, -0.0226, 0.1131, ..., 0.0634, 0.1191, 0.0106],
[-0.0297, -0.0279, 0.1152, ..., 0.0972, 0.1198, 0.0182],
[-0.0207, -0.0258, 0.1170, ..., 0.0877, 0.1053, 0.0122]],
grad_fn=AddmmBackward0)
def get_loss(dataloader, model, loss_fn, device=device):
"""全体数据集/整个分布 模型输出与标签之间的 平均 偏差/损失
"""
# 把模型设置为评估模式
model.eval()
losses = []
with torch.no_grad():
for X,y in dataloader:
X = X.to(device=device)
y = y.to(device=device)
y_pred = model(X)
loss = loss_fn(y_pred, y)
losses.append(loss.item())
return round(np.array(losses).mean(), ndigits=3)
def get_acc(dataloader, model=model, device=device):
"""分类问题精度计算
- 精度是针对整个数据集的
"""
# 把模型设置为评估模式
model.eval()
accs = []
with torch.no_grad():
for X, y in dataloader:
X = X.to(device=device)
y = y.to(device=device)
y_pred = model(X)
y_pred = y_pred.argmax(dim=-1)
acc = (y_pred == y).float().mean()
accs.append(acc.item())
return round(np.array(accs).mean(), ndigits=3)
# 模型参数搬家
model.to(device=device)
def train(dataloader=train_dataloader, model=model, loss_fn=loss_fn,
optimizer=optim, epochs=2):
print(f"自然准确率:Train_Acc:{get_acc(dataloader=train_dataloader)}, Test_Acc: {get_acc(dataloader=test_dataloader)}")
# 循环训练epocs轮次
for epoch in range(1, epochs+1):
# 把模型设置为训练模型
model.train()
# 每轮都按批量训练
for X, y in dataloader:
X = X.to(device=device)
y = y.to(device=device)
# 正向传播
y_pred = model(X)
# 计算损失
loss = loss_fn(y_pred, y)
# 梯度清空
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
print(f"Epoch: {epoch}, Train_Acc:{get_acc(dataloader=train_dataloader)}, Test_Acc: {get_acc(dataloader=test_dataloader)}")
train(epochs=2)
自然准确率:Train_Acc:0.098, Test_Acc: 0.095 Epoch: 1, Train_Acc:0.932, Test_Acc: 0.938 Epoch: 2, Train_Acc:0.966, Test_Acc: 0.969 |
|
通常仅保存参数
model.state_dict()
OrderedDict([('conv1.weight',
tensor([[[[ 0.1514, -0.0253, 0.3065],
[ 0.1495, 0.3303, -0.2056],
[ 0.3438, -0.0484, 0.3366]]],
。。。。。
[ 1.0156e-01, -1.4222e-01, -3.5859e-02]]]])),
('conv2.bias',
tensor([-0.0321, -0.1062, 0.0668, 0.0728, 0.0881, -0.1327, 0.0257, -0.0702,
0.0444, 0.0858, 0.1039, 0.0888, -0.0225, 0.0063, 0.1431, -0.1209])),
('fc1.weight',
tensor([[ 0.0078, 0.0408, 0.0449, ..., 0.0143, 0.0387, 0.0377],
...,
[-0.0238, -0.0331, 0.0028, ..., -0.0578, -0.0317, -0.0269]])),
('fc1.bias',
tensor([-3.6302e-02, -2.9473e-02, -4.6407e-02, 2.9217e-02, -3.2748e-02,
。。。。。。
4.5190e-02])),
('fc2.weight',
tensor([[ 0.0387, 0.0094, -0.0014, ..., -0.0519, -0.0089, -0.0399],
...,
[ 0.0345, -0.0245, -0.0230, ..., -0.0107, -0.0671, 0.0299]])),
('fc2.bias',
tensor([-0.0255, 0.0335, 0.0006, -0.0283, 0.0003, 0.0603, -0.0160, -0.0432,
。。。。。
0.0479, -0.0003, -0.0592, -0.0500, -0.0101, 0.0607, 0.0329, 0.0077])),
('fc3.weight',
tensor([[ 0.0855, 0.0188, 0.0714, ..., -0.0760, 0.0899, 0.0265],
...,
[-0.0751, -0.0957, 0.1219, ..., 0.0270, -0.1015, -0.0457]])),
('fc3.bias',
tensor([-0.0875, -0.0108, 0.0775, -0.0821, -0.0394, -0.0221, -0.0566, 0.0552,
0.0577, -0.0431]))])
torch.save(obj=model.state_dict(), f="lenet.pt") 模型参数加载
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import transforms
# 是否有GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
class LeNet(nn.Module):
"""
定义一个LeNet
"""
def __init__(self):
super(LeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu1 = nn.ReLU()
# 2
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu2 = nn.ReLU()
# 展平层
self.flatten = nn.Flatten()
# 分类层,这一步输入的特征数是上一步向量的特征维数,是固定的
self.fc1 = nn.Linear(in_features=576, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=10)
def forward(self,x):
# [B, 1, 32, 32] -- [B, 6, 30, 30]
x = self.conv1(x)
# [B, 6, 30, 30] -- [B, 6, 15, 15]
x = self.pool1(x)
x = self.relu1(x)
# [B, 6, 15, 15] -- [B, 16, 13, 13]
x = self.conv2(x)
# [B, 16, 13, 13] -- [B, 16, 6, 6]
x = self.pool2(x)
x = self.relu2(x)
# [B, 16, 6, 6] -- [B, 576]
x = self.flatten(x)
# [B, 576] -- [B, 256]
x = self.fc1(x)
# [B, 256] -- [B, 128]
x = self.fc2(x)
# [B, 128] -- [B, 10]
x = self.fc3(x)
return x
model = LeNet()
# 加载权重
model.load_state_dict(state_dict=torch.load(f="lenet.pt"), )
model.state_dict()
OrderedDict([('conv1.weight',
tensor([[[[ 0.1514, -0.0253, 0.3065],
[ 0.1495, 0.3303, -0.2056],
[ 0.3438, -0.0484, 0.3366]]],
...
...
...
)))
|
|
直接读取图片
# PyTorch 三剑客
import torch
from torch import nn
from torch.nn import functional as F
# 数据打包工具
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 图像处理工具
from matplotlib import pyplot as plt
from PIL import Image
import cv2
from torchvision import transforms
# 通用科学计算神器
import numpy as np
# 解决 OMP问题
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 定义预处理
trans = transforms.Compose([
transforms.Grayscale(),
transforms.Resize(size=(32,32)),
transforms.ToTensor()
])
class MyDataset(Dataset):
"""
自定义数据集
"""
def __init__(self, anno_info=None, trans=trans):
"""
初始化:负责接收超参
"""
self.anno_info = anno_info
self.trans = trans
self.images = self._read()
def _read(self):
with open(file=self.anno_info, mode="r", encoding="utf8") as f:
images = [line.strip().split(",") for line in f.readlines()]
return images
def __getitem__(self, idx):
"""
实现下标读取(索引)
"""
img_path, label = self.images[idx]
img = Image.open(fp=img_path)
return self.trans(img), torch.tensor(data=int(label)).long()
def __len__(self):
"""
获取数据量
"""
return len(self.images)
# 构建训练集的数据加载器
train_dataset = MyDataset(anno_info="train.csv",)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=512, shuffle=True)
# 构建测试集的数据加载器
test_dataset = MyDataset(anno_info="test.csv")
test_dataloader = DataLoader(dataset=test_dataset, batch_size=512, shuffle=False)
|
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
# 图像处理工具
from matplotlib import pyplot as plt
from PIL import Image
import cv2
from torchvision import transforms
# 是否有GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
class LeNet(nn.Module):
"""
定义一个LeNet
"""
def __init__(self):
super(LeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu1 = nn.ReLU()
# 2
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu2 = nn.ReLU()
# 展平层
self.flatten = nn.Flatten()
# 分类层,这一步输入的特征数是上一步向量的特征维数,是固定的
self.fc1 = nn.Linear(in_features=576, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=10)
def forward(self,x):
# [B, 1, 32, 32] --> [B, 6, 30, 30]
x = self.conv1(x)
# [B, 6, 30, 30] --> [B, 6, 15, 15]
x = self.pool1(x)
x = self.relu1(x)
# [B, 6, 15, 15] --> [B, 16, 13, 13]
x = self.conv2(x)
# [B, 16, 13, 13] --> [B, 16, 6, 6]
x = self.pool2(x)
x = self.relu2(x)
# [B, 16, 6, 6] --> [B, 576]
x = self.flatten(x)
# [B, 576] --> [B, 256]
x = self.fc1(x)
# [B, 256] --> [B, 128]
x = self.fc2(x)
# [B, 128] --> [B, 10]
x = self.fc3(x)
return x
model = LeNet()
# 加载权重
model.load_state_dict(state_dict=torch.load(f="lenet.pt"), )
# 定义预处理
trans = transforms.Compose([
transforms.Grayscale(),
transforms.Resize(size=(32,32)),
transforms.ToTensor()
])
def predict(img_path="./0.jpeg", model=model, trans=trans):
"""
预测图像
"""
# 1,模型设置为推断模式
model.eval()
# 2, 读取图像
img = Image.open(fp=img_path)
img = torch.unsqueeze(input=trans(img), dim=0).to(device=device)
with torch.no_grad():
y_pred = model(img)
y_pred = y_pred.argmax(dim=-1)
return y_pred.item()
# 推断函数
print(predict(img_path="./0.jpeg"))
print(predict(img_path="./1.jpeg"))
print(predict(img_path="./2.jpeg"))
print(predict(img_path="./3.jpeg"))
print(predict(img_path="./4.jpeg"))
|
import torch
from torch import nn
from torch.nn import functional as F
class LeNet2(nn.Module):
def __init__(self,n_classes=10):
"""LeNet优化版
- 输入:32*32固定大小图片,格式[B,C,32,32]
- 输出:批次的类别,格式[B, n_classes]
"""
super().__init__()
self.n_classes = n_classes
# 第 1 层, [B, 1, 32, 32] -- [B, 16, 16, 16]
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=6),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
# 第 2 层, [B, 6, 16, 16] -- [B, 16, 8, 8], 层数多少会影响模型收敛速度
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
# 分类
self.classifier = nn.Sequential(
nn.Linear(in_features=16*8*8, out_features=1024),
nn.Dropout(p=0.3),
nn.Linear(in_features=1024, out_features=256),
nn.Dropout(p=0.2),
nn.Linear(in_features=256, out_features=self.n_classes)
)
def forward(self,x):
# [B, 1, 32, 32] -- [B, 6, 16, 16]
h = self.layer1(x)
# [B, 6, 16, 16] -- [B, 16, 8, 8]
h = self.layer2(h)
# 维度转换 [B, 16, 8, 8] -- [B, 16*8*8=1024]
h = h.view(h.size(0), -1)
# [B, 1024] -- [B, 10]
o = self.classifier(h)
return o
def test_LeNet2():
model = LeNet2()
x = torch.randn(size=(32,1,32,32))
y = model(x)
print(y.shape) # torch.Size([32, 10])
|
由于数据集非常足且非常好,没有噪声,脏数据,100%纯 因此此网络去除BN后完全不影响最终精度, 只是第一次收敛比有BN的第一次收敛速度点了一点点 这里提到的数据集的量与纯度也非常重要 |
LeNet全流程
|
依赖包安装 pip install opencv-python-headless -i https://pypi.tuna.tsinghua.edu.cn/simple pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple 单张图片读取 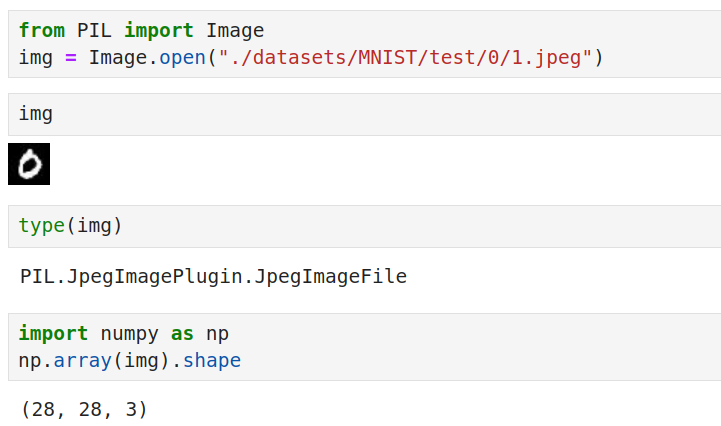
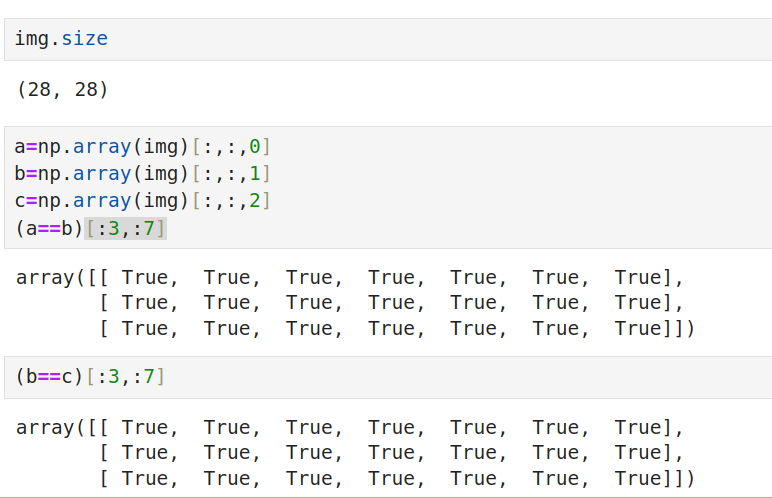
这是一张28×28尺寸的图像,有三色,但三色都是一样的
这意味着,训练时取三色中的一色即可
resize尺寸处理 灰度处理 归一化+转Tensor,这里的归一是除以 255,并没有拉到标准正态分布 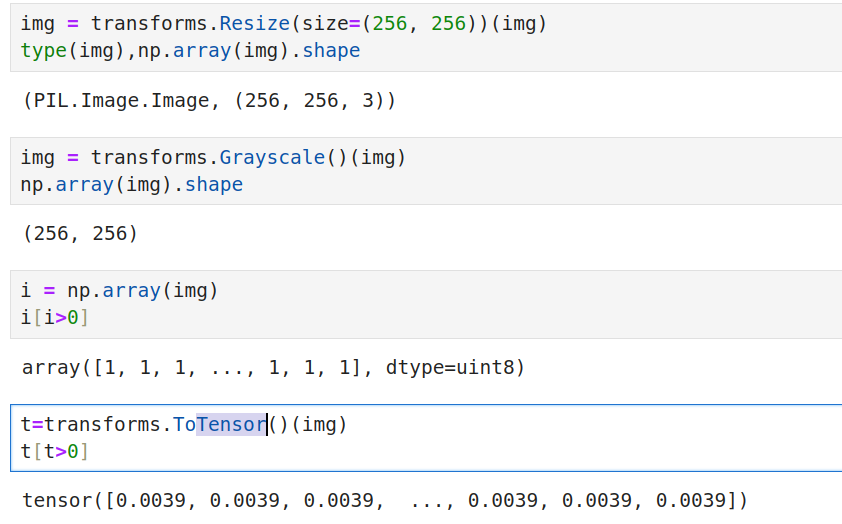
#拉到指定的正态分布
transforms.Normalize(mean=[0.5], std=[0.5])(img)
|
|
依赖包安装 pip install opencv-python-headless -i https://pypi.tuna.tsinghua.edu.cn/simple pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
# PyTorch 三剑客
import torch
from torch import nn
from torch.nn import functional as F
# 数据打包工具
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 图像处理工具
from matplotlib import pyplot as plt
from PIL import Image
import cv2
from torchvision import transforms
# 通用科学计算神器
import numpy as np
# 解决 OMP问题
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 测试是否有GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
import os
def get_image_paths(root_dir):
image_paths = []
for root, dirs, files in os.walk(root_dir):
for file in files:
if file.endswith(".jpeg") or file.endswith(".jpg") or file.endswith(".png"):
image_path = os.path.join(root, file)
label = os.path.basename(root)
image_paths.append([image_path, label])
return image_paths
# 指定数据集目录
mnist_dir = "/wks/datasets/MNIST"
# 获取测试集和训练集的图片路径
test_list = get_image_paths(os.path.join(mnist_dir, "test"))
train_list = get_image_paths(os.path.join(mnist_dir, "train"))
print(len(test_list))
print(len(train_list))
# 打印结果
print("测试集图片路径:")
for path, label in test_list:
print(f"图片路径: {path}, 标签: {label}")
break
print("\n训练集图片路径:")
for path, label in train_list:
print(f"图片路径: {path}, 标签: {label}")
break
10000 60000 测试集图片路径: 图片路径: /wks/datasets/MNIST/test/3/715.jpeg, 标签: 3 训练集图片路径: 图片路径: /wks/datasets/MNIST/train/3/1152.jpeg, 标签: 3
class MyDataset(Dataset):
"""
手写数字数据集
"""
def __init__(self, data_list=None):
"""自定义数据集
"""
# 定义预处理
self.trans = transforms.Compose([
transforms.Grayscale(),
transforms.Resize(size=(32,32)),
transforms.ToTensor()
])
self.images = data_list
def __getitem__(self, idx):
"""
实现下标读取(索引)
"""
img_path, label = self.images[idx]
img = Image.open(fp=img_path)
return self.trans(img), torch.tensor(data=int(label)).long()
def __len__(self):
"""
获取数据量
"""
return len(self.images)
# 构建训练集的数据加载器 train_dataset = MyDataset(data_list=train_list) train_dataloader = DataLoader(dataset=train_dataset, batch_size=512, shuffle=True) # 构建测试集的数据加载器 test_dataset = MyDataset(data_list=test_list) test_dataloader = DataLoader(dataset=test_dataset, batch_size=512, shuffle=False)
test_dataset[0]
(tensor([[[0.0118, 0.0039, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0157, 0.0157, 0.0078, ..., 0.0000, 0.0000, 0.0000],
[0.0039, 0.0078, 0.0157, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]),
tensor(3))
|
class LeNet(nn.Module):
"""
定义一个LeNet
"""
def __init__(self):
super(LeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu1 = nn.ReLU()
# 2
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.relu2 = nn.ReLU()
# 展平层
self.flatten = nn.Flatten()
# 分类层
self.fc1 = nn.Linear(in_features=576, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=10)
def forward(self,x):
# [B, 1, 32, 32] -- [B, 6, 30, 30]
x = self.conv1(x)
# [B, 6, 30, 30] -- [B, 6, 15, 15]
x = self.pool1(x)
x = self.relu1(x)
# [B, 6, 15, 15] -- [B, 16, 13, 13]
x = self.conv2(x)
# [B, 16, 13, 13] -- [B, 16, 6, 6]
x = self.pool2(x)
x = self.relu2(x)
# [B, 16, 6, 6] -- [B, 576]
x = self.flatten(x)
# [B, 576] -- [B, 256]
x = self.fc1(x)
# [B, 256] -- [B, 128]
x = self.fc2(x)
# [B, 128] -- [B, 10]
x = self.fc3(x)
return x
class LeNet1(nn.Module):
"""
定义一个LeNet
"""
def __init__(self):
super(LeNet1, self).__init__()
# 第 1 个阶段
self.stage1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=6),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
# 第 2 个阶段
self.stage2 = nn.Sequential(
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
# 分类器
self.classifier = nn.Sequential(
nn.Linear(in_features=1024, out_features=512),
nn.Dropout(0.2),
nn.Linear(in_features=512, out_features=128),
nn.Dropout(0.2),
nn.Linear(in_features=128, out_features=10)
)
def forward(self,x):
# [B, 1, 32, 32] -- [B, 6, 16, 16]
h = self.stage1(x)
# [B, 6, 16, 16] -- [B, 16, 8, 8]
h = self.stage2(h)
# 维度转换 [B, 16, 8, 8] -- [B, 1024]
h = h.view(h.size(0), -1)
# [B, 1024] -- [B, 10]
o = self.classifier(h)
return o
|
# 构建模型 lenet = LeNet1() # 参数搬家 lenet.to(device=device)
LeNet1(
(stage1): Sequential(
(0): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(stage2): Sequential(
(0): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=1024, out_features=512, bias=True)
(1): Dropout(p=0.2, inplace=False)
(2): Linear(in_features=512, out_features=128, bias=True)
(3): Dropout(p=0.2, inplace=False)
(4): Linear(in_features=128, out_features=10, bias=True)
)
)
# 定义损失函数 loss_fn = nn.CrossEntropyLoss() # 定义优化器 optimizer = torch.optim.Adam(params=lenet.parameters(), lr=1e-3) 过程监控
def get_loss(dataloader, model=lenet, loss_fn=loss_fn):
"""
计算平均损失
"""
# 把模型设置为评估模式
model.eval()
losses = []
with torch.no_grad():
for X,y in dataloader:
X = X.to(device=device)
y = y.to(device=device)
y_pred = model(X)
loss = loss_fn(y_pred, y)
losses.append(loss.item())
return round(np.array(losses).mean(), ndigits=3)
def get_acc(dataloader, model=lenet):
"""
计算平均准确率
"""
# 把模型设置为评估模式
model.eval()
accs = []
with torch.no_grad():
for X, y in dataloader:
X = X.to(device=device)
y = y.to(device=device)
y_pred = model(X)
y_pred = y_pred.argmax(dim=-1)
acc = (y_pred == y).float().mean()
accs.append(acc.item())
return round(np.array(accs).mean(), ndigits=3)
训练
def train(dataloader=train_dataloader, model=lenet, loss_fn=loss_fn, optimizer=optimizer, epochs=2):
print(f"自然准确率:Train_Acc:{get_acc(dataloader=train_dataloader)}, Test_Acc: {get_acc(dataloader=test_dataloader)}")
# 循环训练epocs轮次
for epoch in range(1, epochs+1):
# 把模型设置为训练模型
model.train()
# 每轮都按批量训练
for X, y in dataloader:
X = X.to(device=device)
y = y.to(device=device)
# 正向传播
y_pred = model(X)
# 计算损失
loss = loss_fn(y_pred, y)
# 梯度清空
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
print(f"Epoch: {epoch}, Train_Acc:{get_acc(dataloader=train_dataloader)}, Test_Acc: {get_acc(dataloader=test_dataloader)}")
train() 自然准确率:Train_Acc:0.104, Test_Acc: 0.104 Epoch: 1, Train_Acc:0.974, Test_Acc: 0.976 Epoch: 2, Train_Acc:0.976, Test_Acc: 0.975 |
|
保存 torch.save(obj=lenet.state_dict(), f="lenet_params.pkl") 加载权重 # 定义模型 my_lenet = LeNet1() # 加载权重 my_lenet.load_state_dict(state_dict=torch.load(f="lenet_params.pkl",weights_only=True), ) |
def predict(img_path, model=lenet):
"""
预测图像
"""
trans=transforms.Compose([
transforms.Grayscale(),
transforms.Resize(size=(32,32)),
transforms.ToTensor()
])
model.to(device=device)
# 模型设置为推断模式
model.eval()
# 读取图像
img = Image.open(fp=img_path)
img = torch.unsqueeze(input=trans(img), dim=0).to(device=device)
with torch.no_grad():
y_pred = model(img)
y_pred = y_pred.argmax(dim=-1)
return y_pred.item()
predict(img_path="/wks/datasets/MNIST/test/7/1001.jpeg",model=my_lenet) 7 |
|
参考