硬件环境
笔记本系列 5000¥ - 12000¥ 皆可
有GPU更好,无GPU也行
磁盘:至少2T,
最好是存储或者特定的高速的卡,其次是SSD,普通磁盘也可以,就是慢一点
普通电脑磁盘不够,买个固态移动硬盘也可以
|
|
由于大模型有多家,并且每家都在发版多个版本,每个版本也在迭代 所以环境经常变,曾经可以运行的环境,换了新版本,就无法运行了 比如,半年前的模型要求一些依赖包必须升级,现环境还运行着其他的模型,就只能新建一个环境 所以,使用docker,部分环境依赖安装到docker中,部分依赖映射到外部磁盘 大模型参数,通常一个模型几十G大小,来上三五个就几百G,放外部,映射到docker -v /opt/models:/models 或者直接挂载/mnt GPU环境直接安装 nvidia的docker, 安装好了CUDA CPU环境,可以安装一下ubuntu的docker WSL中创建的docker如果映射了 -v /mnt:/mnt ,那么可直接访问外部磁盘, xt@qisan:~$ df -h|grep mnt|grep -v wsl C:\ 884G 805G 79G 92% /mnt/c D:\ 69G 50G 19G 73% /mnt/d E:\ 466G 150G 316G 33% /mnt/e F:\ 1.9T 1.2T 700G 63% /mnt/f 包含插入的移动硬盘,若是移动硬盘,要求电脑启动前就插入,否则无法访问, 只需要开机前插入存储或硬盘,就可以在docker中访问,已经方便了很多 总体来说,docker中不保存文件,保存环境及配置 如果docker中文件需要保存,那么通常也是打包好复制出来,换环境,load docker,文件复制回去 总之,文件一般不打包到docker中 很多软件喜欢在当前用户下创建.cache,.config类似的文件,然后放往里放东西... 搞得磁盘用了很多,但不知道放的是啥,删除又不敢删除...这是windows C盘的痛点... docker中,有时新环境就创建一个新用户, 环境玩坏了,想重装,就只删除该用户下的文件就可以了 用docker,主要用的是它的linux环境...通常不往里面放文件 |
|
|
|
|
transformers
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat",trust_remote_code=True)
query = "现在是9月份,我鼻炎爆发了,一经风吹就不停打喷嚏,我是湿寒体质,生活习惯上我应该注意什么?"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
鼻炎在秋季确实容易发作,尤其是对于湿寒体质的人来说,以下是一些建议,可以帮助您缓解症状并改善生活习惯:
1. **保暖防寒**:
- 注意保暖,尤其是在早晚温差较大的时候,避免受凉。
- 尽量减少在寒冷或风大的环境中停留的时间。
2. **饮食调养**:
- 饮食宜温热,避免生冷、油腻、辛辣的食物。
- 多吃一些具有温补作用的食物,如生姜、大枣、核桃等。
- 增加富含维生素C的食物摄入,如柑橘类水果,有助于增强免疫力。
3. **适度运动**:
- 适量进行有氧运动,如散步、慢跑等,增强体质,提高抵抗力。
- 避免过度劳累,保证充足的睡眠。
4. **保持室内空气流通**:
- 经常开窗通风,保持室内空气新鲜。
- 使用空气净化器,减少室内过敏原。
5. **避免过敏原**:
- 尽量避免接触可能引起过敏的物质,如花粉、尘螨、宠物毛发等。
- 保持家居环境的清洁,定期打扫,减少灰尘。
6. **中药调理**:
- 可以在中医师的指导下,使用一些具有温肺散寒、祛湿通窍作用的中药进行调理。
7. **日常护理**:
- 每天用温水清洗鼻腔,有助于缓解鼻腔不适。
- 避免用手揉搓鼻子,以免加重症状。
8. **心理调节**:
- 保持良好的心态,避免情绪波动过大。
请记住,以上建议仅供参考,如有需要,请咨询专业医生的意见。同时,如果鼻炎症状严重或持续不缓解,应及时就医。
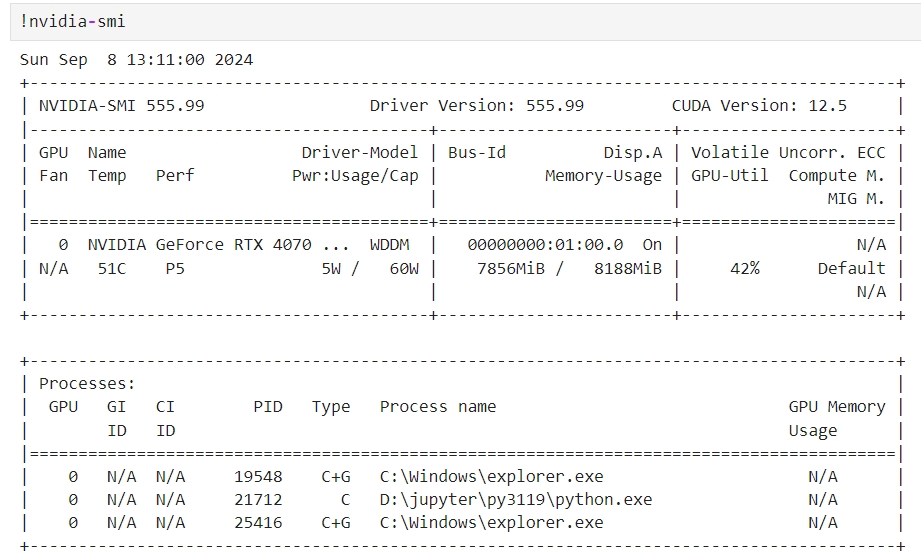
笔记本电脑,8G显卡,运行9B模型非常吃力,半小时回答一次问题
query = "湿寒体质,饮食上应该注意什么?"
def ask(query):
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
ask(query)
湿寒体质的人在饮食上需要注意以下几点,以帮助调节体质,增强身体健康:
1. **温热食物**:应多吃一些温热性质的食物,如生姜、大蒜、辣椒、羊肉、鸡肉等,这些食物有助于驱寒除湿。
2. **避免寒凉食物**:应减少或避免食用寒凉性质的食物,如西瓜、黄瓜、苦瓜、绿豆、梨等,这些食物可能会加重湿寒症状。
3. **适量摄入温补食物**:如红枣、桂圆、枸杞等,这些食物有助于温补身体,增强体质。
4. **多吃健脾利湿的食物**:如薏米、红豆、南瓜、山药等,这些食物有助于健脾利湿,改善湿寒体质。
5. **适量摄入蛋白质**:如鸡肉、鱼肉、豆腐等,这些食物有助于增强体质,提高免疫力。
6. **保持饮食均衡**:多吃蔬菜和水果,保证营养均衡,有助于身体健康。
7. **适量饮水**:保持充足的水分摄入,有助于身体代谢,排除湿气。
8. **避免生冷食物**:如冰淇淋、冷饮等,这些食物会加重湿寒症状。
9. **控制饮食量**:避免暴饮暴食,以免加重脾胃负担。
10. **注意饮食卫生**:确保食物新鲜、卫生,避免食物中毒。
请根据个人体质和健康状况,在专业医生的指导下调整饮食。
下面是其他的回答:
数学是一门逻辑性强、抽象性高的学科,学习数学需要系统的方法和持之以恒的努力。
以下是一些建议,帮助你更有效地学习数学:
1. **打好基础**:
- 从基础概念开始,确保对每个数学概念都有清晰的理解。
- 重视基础运算,如加减乘除、代数运算等。
2. **系统学习**:
- 按照数学的内在逻辑顺序,从简单到复杂,逐步深入。
- 遵循教材或课程大纲,系统学习各个章节。
3. **多做练习**:
- 通过大量练习来巩固所学知识,提高解题能力。
- 练习时注意不同类型的题目,包括基础题、中等题和难题。
4. **理解而非死记**:
- 尽量理解数学概念背后的原理,而不是单纯记忆公式和定理。
- 通过举例、类比等方式加深对概念的理解。
5. **积极参与课堂**:
- 课堂上认真听讲,积极思考,勇于提问。
- 与老师和同学讨论,共同解决问题。
6. **利用资源**:
- 利用图书馆、网络等资源,查找相关资料和习题。
- 观看教学视频,如MOOC(大型开放在线课程)等。
7. **培养逻辑思维**:
- 数学训练有助于培养逻辑思维和解决问题的能力。
- 在日常生活中,尝试用数学思维分析问题。
8. **定期复习**:
- 定期回顾所学内容,防止遗忘。
- 对易错题进行总结,避免重复犯错。
9. **保持耐心和毅力**:
- 学习数学需要时间和耐心,不要因为一时的困难而放弃。
- 遇到难题时,多思考、多尝试,不要急于求成。
10. **参加竞赛和活动**:
- 参加数学竞赛和活动,可以激发学习兴趣,提高解题能力。
- 通过与其他同学交流,拓宽视野。
总之,学习数学需要持之以恒的努力和正确的方法。希望以上建议能帮助你更好地学习数学。
培养良好的生活习惯对身心健康和个人的全面发展至关重要。以下是一些建议,帮助您逐步养成良好的生活习惯:
1. **规律作息**:
- 每天保持固定的睡眠时间,保证充足的睡眠。
- 早晨起床后进行适量的晨练,如散步、做操等。
2. **合理饮食**:
- 饮食均衡,多吃蔬菜、水果和粗粮,少吃油腻、高糖、高盐的食物。
- 避免暴饮暴食,定时定量。
3. **适量运动**:
- 每周至少进行150分钟的中等强度运动,如快走、游泳、骑自行车等。
- 根据个人兴趣选择运动项目,保持运动的乐趣。
4. **保持个人卫生**:
- 每天早晚刷牙,饭后漱口。
- 定期洗澡,保持身体清洁。
5. **培养阅读习惯**:
- 每天安排一定时间阅读,可以是专业书籍、文学作品或新闻资讯。
- 阅读有助于拓宽视野,提高思维能力。
6. **学习新知识**:
- 不断学习新知识,提高自身素质。
- 可以通过在线课程、讲座、研讨会等方式学习。
7. **保持社交活动**:
- 与家人、朋友保持良好的沟通,参加社交活动。
- 社交有助于缓解压力,提高生活质量。
8. **培养兴趣爱好**:
- 选择一项或多项兴趣爱好,如绘画、音乐、摄影等。
- 兴趣爱好有助于丰富生活,提高幸福感。
9. **自我反思**:
- 定期进行自我反思,总结经验教训,不断改进。
- 学会从失败中汲取教训,保持积极向上的心态。
10. **时间管理**:
- 合理安排时间,提高工作效率。
- 学会拒绝无意义的事务,专注于重要任务。
通过以上方法,您可以逐步养成良好的生活习惯,提高生活质量。请记住,改变需要时间和耐心,持之以恒是关键。
|
|
|
|
|
|
|
|
ollama本地部署
|
大模型经ollama量化后本部运行 https://ollama.com/library https://github.com/ollama/ollama 下载,这个是支持windows的,可放心下载windows版本 https://ollama.com/download 更改默认下载路径的方法
环境变量设置
OLLAMA_MODELS
该变量为模型的下载目录
如果你希望将模型下载到其他位置以节省C盘空间或出于其他考虑,可以通过设置环境变量的方式来更改默认下载路径。以下是具体步骤:
打开系统属性:右键点击“此电脑”或“计算机”,选择“属性”。
进入环境变量设置:点击“高级系统设置”,在弹出的窗口中点击“环境变量”按钮。
新建环境变量:在“系统变量”或“用户变量”部分,点击“新建”来创建一个新的环境变量。
变量名:输入OLLAMA_MODELS。
变量值:输入你希望保存模型的新目录路径,例如D:\OllamaModels。
应用更改:点击“确定”保存设置。
重启Ollama:为了确保更改生效,你需要重启Ollama服务或应用程序。
你可以通过任务管理器结束相关进程后重新启动,或者重启电脑。
PS C:\Users\83933> ollama list
NAME ID SIZE MODIFIED
llama2-chinese:13b 990f930d55c5 7.4 GB 6 weeks ago
gemma:latest a72c7f4d0a15 5.0 GB 6 weeks ago
qwen2:latest e0d4e1163c58 4.4 GB 6 weeks ago
llama3:latest 365c0bd3c000 4.7 GB 6 weeks ago
Welcome to Ollama!
Run your first model:
ollama run llama3
PS C:\Windows\System32> ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 1% ▕
安装完ollama后可查看其运行端口11434
PS C:\Users\83933>
PS C:\Users\83933> netstat -nao|findstr "11434"
TCP 127.0.0.1:11434 0.0.0.0:0 LISTENING 24560
ubantu安装
curl -fsSL https://ollama.com/install.sh | sh
(base) xt@ai:~$ curl -fsSL https://ollama.com/install.sh | sh
>>> Downloading ollama...
######################################################################## 100.0%#=#=-# #
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
root@ai:~# netstat -tunlp|grep 11434
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 4974/ollama
|
https://mp.weixin.qq.com/s/S5Pxb9fe055F6Kg8aMQUDw
Ollama 是一个用于在本地运行大型语言模型的工具,本文将介绍如何在Windows/Linux/Mac系统上安装和使用 Ollama。
官网:https://ollama.com
Github:https://github.com/ollama/ollama
curl -fsSL https://ollama.com/install.sh | sh
rm -rf /datai/bigmodel
sudo mkdir -p /datai/bigmodel/ollama
sudo chown -R bml:xt /datai/bigmodel/ollama
export OLLAMA_MODELS=/datai/bigmodel/ollama
ollama serve
bml@kl:~$ sudo netstat -tunlp|grep oll
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 21280/ollama
ollama pull llama3
ollama run llama3
ollama rm llama3
ollama list
ollama run deepseek-r1:8b
ollama run deepseek-r1:14b
ollama run deepseek-r1:32b
ollama run deepseek-r1:70b
bml@kl:~$ ollama run deepseek-r1:14b pulling manifest pulling 6e9f90f02bb3... 100% ▕████████████████████████████████████████████████▏ 9.0 GB pulling 369ca498f347... 100% ▕████████████████████████████████████████████████▏ 387 B pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████▏ 1.1 KB pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████▏ 148 B pulling 3c24b0c80794... 100% ▕████████████████████████████████████████████████▏ 488 B verifying sha256 digest writing manifest success >>> 你好 bml@kl:~$ ollama run deepseek-r1:32b pulling manifest pulling 6150cb382311... 100% ▕████████████████████████████████████████████████▏ 19 GB pulling 369ca498f347... 100% ▕████████████████████████████████████████████████▏ 387 B pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████▏ 1.1 KB pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████▏ 148 B pulling c7f3ea903b50... 100% ▕████████████████████████████████████████████████▏ 488 B verifying sha256 digest writing manifest success >>> >>> 你好
|
https://ollama.com/library
首次运行需要下载,再次运行直接进入交互窗口
PS C:\Windows\System32> ollama run llama3
>>>
PS C:\Windows\System32>
下载指定参数大小的版本
ollama run llama3:70b
ollama run llama2-chinese:13b
ollama run qwen2
PS C:\Users\83933> ollama run qwen2
>>> 讲个关于程序员的笑语
,程序员生活中的笑话和趣事很多。下面是一则比较受欢迎的:
为什么电脑永远不会生病?
因为它只用软件,不用硬件。
这虽然是一个笑话,但它反映了程序员对计算机系统的理解。在IT行业里,"只用软件,不用硬件"可能意味着程序员通常依赖于软件解决方案
来解决问题,而不是硬件故障或问题。当然,在现实生活中,所有的系统都会遇到各种各样的问题和挑战!
这样的笑话不仅幽默而且亲切,也常常用于增进程序员团队的内部氛围和友情。
>>> 如何培养良好的生活习惯
培养良好的生活习惯对个人健康、工作效率以及生活质量都有着深远的影响。以下是一些实用的方法来帮助您逐步建立并保持良好的生活习惯
:
### 1. **规律作息**
- 确保每天都有固定的起床时间和睡觉时间,让身体适应自然的生物钟。
- 避免夜间过度使用电子设备,因为蓝光会干扰睡眠质量。
### 2. **健康饮食**
- 均衡摄入各类食物,保证足够的蛋白质、维生素和矿物质。
- 尽量减少高糖、高盐和加工食品的摄入。
- 定时用餐,避免长时间不吃或暴饮暴食。
### 3. **定期运动**
- 根据个人兴趣选择适合自己的运动方式(如跑步、瑜伽、游泳等)。
- 每周至少进行150分钟中等强度的有氧运动或75分钟高强度的有氧运动。
- 定期检查身体,了解自身的健康状况。
### 4. **保持社交**
- 与家人和朋友定期交流,建立良好的社会支持网络。
- 参加社区活动、俱乐部或兴趣小组,扩展人际交往圈。
### 5. **学习新技能**
- 持续学习可以提升自我价值感,同时增加生活中的乐趣。
- 利用在线课程、书籍或工作坊来学习新的知识和技能。
### 6. **管理压力**
- 学习放松技巧如冥想、深呼吸等,帮助减轻日常的压力。
- 设置合理的工作目标,学会说“不”,避免过度承诺。
### 7. **保持个人卫生**
- 定期洗澡、刷牙,保持身体清洁和口腔健康。
- 经常洗手以预防疾病传播。
### 8. **良好的阅读习惯**
- 每天安排一段时间进行阅读,无论是专业书籍、小说还是时事新闻,都可以提升知识面和个人素养。
通过逐步实践这些习惯,您可以逐渐建立起更健康、更有条理的生活方式。记住,改变需要时间和耐心,对自己保持积极和包容的态度至关重
要。
>>>
PS C:\Users\83933>
llama3
qwen2
windows上curl运行要注意以下几点:
- 访问地址使用的是localhost,若是想从其他机器/虚拟机/WSL 中访问windows的主机IP,可能是访问不通的
- windows上的cmd没有curl,安装一下git bash,这样就能以localhost的方式访问
- model的名称是固定的,是前面ollama run model_name,安装过的模型才可以
$ curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "who are you"
}
]
}'
{"id":"chatcmpl-421","object":"chat.completion","created":1718456517,"model":"llama3","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"I'm just an artificial intelligence designed to assist and communicate with humans in a helpful and friendly way. I don't have personal feelings or emotions, but I'm always happy to help answer questions, provide information, or just chat about topics that interest you.\n\nYou can think of me like a knowledgeable concierge who's available 24/7 to provide assistance on a wide range of subjects. Whether you need help with a problem, want to learn something new, or just need someone to talk to, I'm here for you!\n\nI understand and respond to natural language input, so you can ask me questions in your own words, using everyday language. I'll do my best to provide accurate and helpful responses, and if I don't know the answer to a question, I'll let you know and try to point you in the direction of someone who might be able to help.\n\nSo, what's on your mind? Do you have a specific question or topic you'd like to discuss? I'm all ears (or rather, all text)!"},"finish_reason":"stop"}],"usage":{"prompt_tokens":8,"completion_tokens":210,"total_tokens":218}}
$ curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2",
"messages": [
{
"role": "system",
"content": "七三笔记是一个关于介绍AI相关知识的网站"
},
{
"role": "user",
"content": "七三笔记是什么"
}
]
}'
{"id":"chatcmpl-579","object":"chat.completion","created":1718456827,"model":"qwen2","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"\"�����ʼ\" ��汉语意思是\"喂,你好\" 或者 \"喂\". 这通常是用于对某人的非正式或亲切的问候。例如在电话中或者遇到熟人的时候使用。"},"finish_reason":"stop"}],"usage":{"prompt_tokens":36,"completion_tokens":45,"total_tokens":81}}
$ curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2",
"messages": [
{
"role": "system",
"content": "你是一个AI助手."
},
{
"role": "user",
"content": "讲个关于程序员的笑语"
}
]
}'
{"id":"chatcmpl-574","object":"chat.completion","created":1718457020,"model":"qwen2","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"�ű��ģ��Щ�ϵ�����ļ�й�ֱ�ۣ�\n\n1. ���ϵ���: ��Ц���л��\ \n2. �ش�ֵ: \n3. ��ץ���; \n\n���ھ�����\n\n�о��� :\n\n1. ���ϵ� 150��, 90��, 80�,\n\n2. �š�ֵ 3600s, \n\n3. ��ץ��� ��\n\n���֣�\n\nAI��:\n\n1. ���ϵ� \n2. ��Ц\n3. ��ץ\n\n1. ��Ц=150+90+80 =320��\n2. ��ץ=3600s/1min=60min\n3. AI= �š�ֵ÷��ץ= =3600s÷60min=60��"},"finish_reason":"stop"}],"usage":{"prompt_tokens":24,"completion_tokens":202,"total_tokens":226}}
$ curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Tell a joke about programmers"
}
]
}'
{"id":"chatcmpl-564","object":"chat.completion","created":1718457102,"model":"qwen2","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"Why do programmers always mix up Christmas and Halloween?\n\nBecause Oct 31 equals Dec 25 in their world. 😃"},"finish_reason":"stop"}],"usage":{"prompt_tokens":21,"completion_tokens":27,"total_tokens":48}}
|
使用apipost/postman apipost 设置 -- 超时时间要设置长一些 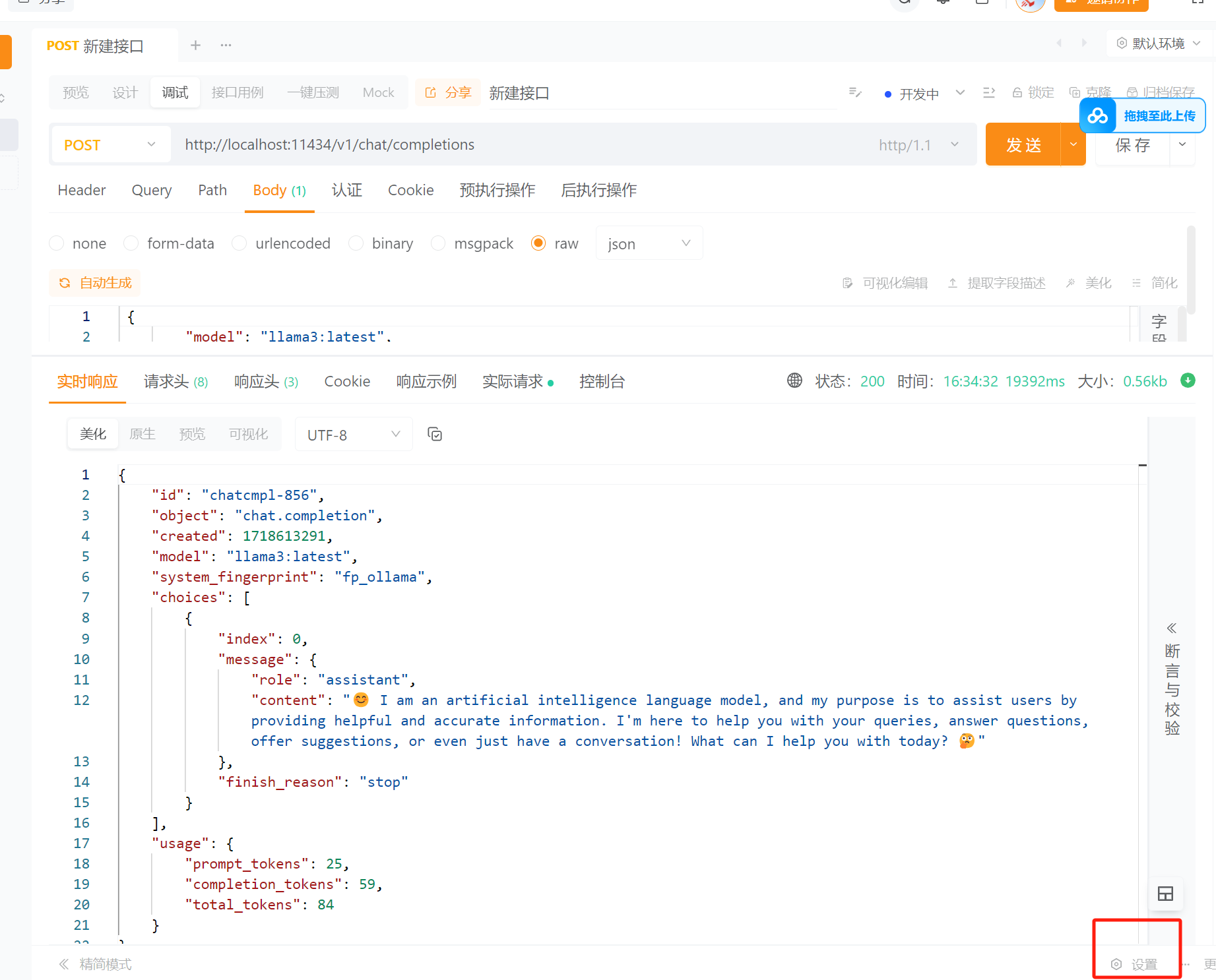
浏览器中测试ollama是否通畅: http://localhost:11434/api/tags
http://localhost:11434/v1/chat/completions
{
"model": "llama3:latest",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你是谁?"
}
]
}
{"id":"chatcmpl-765","object":"chat.completion","created":1722307705,
"model":"llama3:latest",
"system_fingerprint":"fp_ollama",
"choices":[
{"index":0,
"message":{
"role":"assistant",
"content":"😊 I'm just an AI assistant, here to help you with any questions or tasks you may have. You can think of me as a knowledgeable and friendly companion who's always ready to lend a hand. My capabilities include providing information on various topics, answering questions, generating text, and even helping with creative projects or brainstorming ideas. I'm constantly learning and improving, so feel free to ask me anything - I'll do my best to assist you! 💡"},"finish_reason":"stop"}],
"usage":{"prompt_tokens":25,"completion_tokens":95,"total_tokens":120}
}
http://localhost:11434/v1/chat/completions
{
"model": "qwen2:latest",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你是谁?"
}
]
}
|
|
代码设置 A question about Hugging Face's Transformers library! 😊 The `location` variable in the `ollama` model is a parameter that specifies the location of the model's weights on disk. When you download a pre-trained model using the `transformers` library, the weights are stored in a file on your local machine. By default, the `location` variable is set to `~/.transformers` on Unix-based systems (e.g., macOS, Linux) and `C:\Users\ 环境变量设置 OLLAMA_MODELS 该变量为模型的下载目录 
这两个方式都可以,本人未测试谁的优化高,二者选其一就可以 如果不设置,则是去找当前系统用户的路径 - windows是C:\Users\用户名 - linux是/home/用户名 然后在这个路径下创建缓存目录...及一系列的默认目录 |
|
Generate a response
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'
{"model":"llama3","created_at":"2024-08-01T03:11:42.0896015Z","response":"The","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.1215574Z","response":" sky","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.1487048Z","response":" appears","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.1768242Z","response":" blue","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.2032868Z","response":" because","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.2307869Z","response":" of","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.2568036Z","response":" a","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.2888101Z","response":" phenomenon","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.3048339Z","response":" called","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.3555454Z","response":" Ray","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.3903134Z","response":"leigh","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.4072346Z","response":" scattering","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.4398911Z","response":",","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.4727368Z","response":" named","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.489377Z","response":" after","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.5302665Z","response":" the","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.5628564Z","response":" British","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.588753Z","response":" physicist","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.6254843Z","response":" Lord","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.6521852Z","response":" Ray","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.6847907Z","response":"leigh","done":false}
{"model":"llama3","created_at":"2024-08-01T03:11:42.7124274Z","response":",","done":false}
...
...
Chat with a model
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
{"model":"llama3","created_at":"2024-08-01T03:13:23.604011Z","message":{"role":"assistant","content":"The"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.6441514Z","message":{"role":"assistant","content":" sky"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.6701667Z","message":{"role":"assistant","content":" appears"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.6884909Z","message":{"role":"assistant","content":" blue"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.7264717Z","message":{"role":"assistant","content":" because"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.7548182Z","message":{"role":"assistant","content":" of"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.7707096Z","message":{"role":"assistant","content":" a"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.8058229Z","message":{"role":"assistant","content":" phenomenon"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.8216976Z","message":{"role":"assistant","content":" called"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.8656523Z","message":{"role":"assistant","content":" Ray"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.8933627Z","message":{"role":"assistant","content":"leigh"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.9155393Z","message":{"role":"assistant","content":" scattering"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:23.9372442Z","message":{"role":"assistant","content":","},"done":false}
...
...
...
{"model":"llama3","created_at":"2024-08-01T03:13:34.0888992Z","message":{"role":"assistant","content":" scattering"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.1164082Z","message":{"role":"assistant","content":" of"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.1377344Z","message":{"role":"assistant","content":" light"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.1701336Z","message":{"role":"assistant","content":" by"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.2033446Z","message":{"role":"assistant","content":" tiny"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.2229329Z","message":{"role":"assistant","content":" molecules"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.2401199Z","message":{"role":"assistant","content":" in"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.2801627Z","message":{"role":"assistant","content":" our"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.3050865Z","message":{"role":"assistant","content":" atmosphere"},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.3282763Z","message":{"role":"assistant","content":"."},"done":false}
{"model":"llama3","created_at":"2024-08-01T03:13:34.3553094Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,
"total_duration":11066389900,"load_duration":7978500,"prompt_eval_count":11,"prompt_eval_duration":314779000,"eval_count":398,"eval_duration":10740509000}
|
Ollama是一个开源的、轻量级且高效的大型语言模型(LLM)运行框架,它并非直接属于某一家特定的公司,而是由社区和开发者共同维护的。以下是关于Ollama的详细介绍: 一、Ollama的背景与功能 开源性质:Ollama是一个开源项目,允许用户根据特定需求定制LLM,并支持多种开源大型语言模型的运行。 功能强大:它极大地简化了在Docker容器内部署和管理LLM的过程,使得用户能够快速地在本地运行大型语言模型。 多平台支持:Ollama支持Windows、Linux和Mac等多个操作系统,用户可以根据自己的需求选择合适的平台进行安装和使用。 二、Ollama与大型语言模型的关系 与LLaMA的关系:Ollama利用了llama.cpp提供的底层功能,而LLaMA(又称为羊驼)是Meta公司(原Facebook公司)开源的预训练大型语言模型。Ollama作为大模型运行框架,能够加载和运行包括LLaMA在内的多种开源大型语言模型。 支持的模型:Ollama已经支持了包括Llama 2、Llama 3、Mistral 7B、Gemma等在内的多种开源大型语言模型,用户可以根据自己的需求选择合适的模型进行运行和测试。
三、Ollama的下载与安装
用户可以通过访问Ollama的官方网站(如Ollama官网)或GitHub页面来获取Ollama的下载链接和安装指南。
安装过程通常包括下载Ollama的安装包、解压、配置环境变量以及运行Ollama服务等步骤。
四、Ollama的社区与生态
社区支持:Ollama拥有一个活跃的开发者社区,用户可以在社区中交流使用心得、提出问题和建议,并获取来自其他开发者的帮助和支持。
生态发展:随着Ollama的不断发展和完善,越来越多的开源大型语言模型被纳入其支持范围,同时也有越来越多的开发者基于Ollama框架开发出了各种第三方WebUI和桌面端应用,进一步丰富了Ollama的生态系统。
综上所述,Ollama是一个由社区和开发者共同维护的开源大型语言模型运行框架,它不属于某一家特定的公司,而是为广大用户提供了一个快速、便捷地运行和测试开源大型语言模型的平台。
|
WebUI
https://lobehub.com/zh/docs/usage/features/local-llm
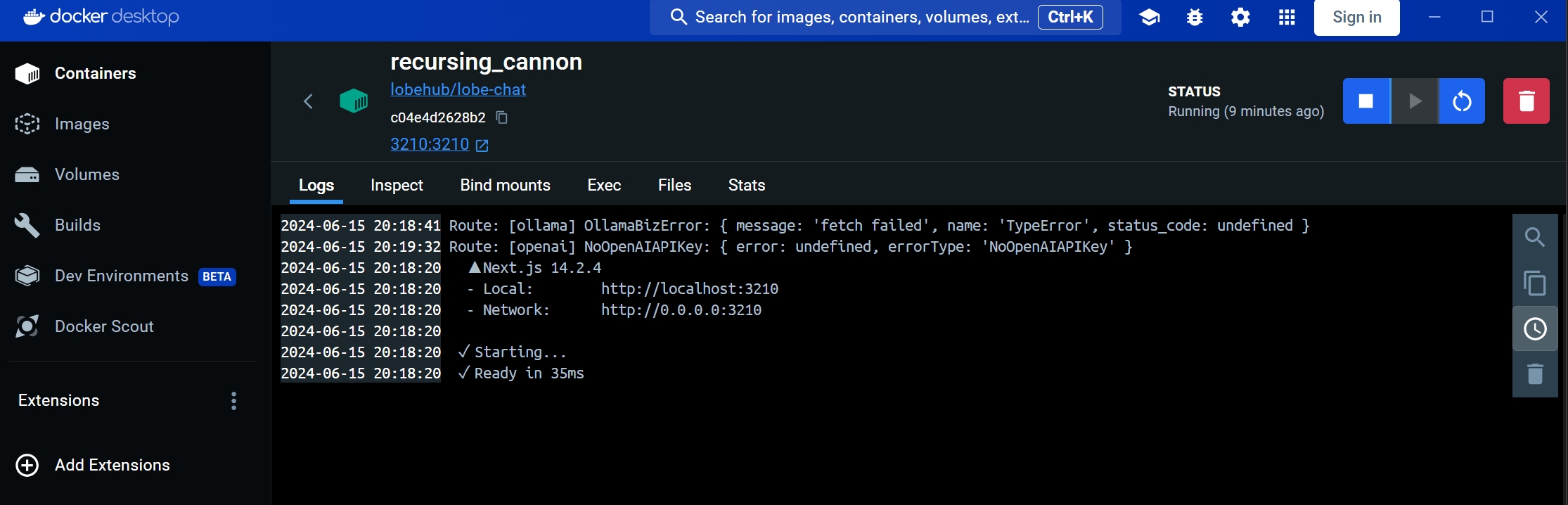
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://host.docker.internal:11434/v1 lobehub/lobe-chat
可以确定一下这个地址,如果有多台服务器,也可以手工指定具体地址
root@ai:~# ping host.docker.internal
PING host.docker.internal.localdomain (192.168.0.43) 56(84) bytes of data.
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://127.0.0.1:11434/v1 lobehub/lobe-chat
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://192.168.136.43:11434/v1 lobehub/lobe-chat
如果是windows,要先启动docker desktop,然后再执行
PS C:\Users\83933> docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://192.168.136.43:11434/v1 lobehub/lobe-chat
Unable to find image 'lobehub/lobe-chat:latest' locally
latest: Pulling from lobehub/lobe-chat
2cc3ae149d28: Downloading [=============================> ] 17.2MB/29.15MB
83321cd73585: Download complete
8e10193cc4bc: Downloading [=================> ] 13.97MB/40.55MB
16d525763801: Download complete
访问
http://127.0.0.1:3210/welcome
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://127.0.0.1:11434/v1 lobehub/lobe-chat
回到docker desktop,可以看到有个容器正在运行,
|
|
https://openwebui.com/ curl -fsSL https://ollama.com/install.sh | sh root@ai:~# which ollama /usr/local/bin/ollama root@ai:~# netstat -tunlp|grep 11434 tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 4974/ollama https://github.com/open-webui/open-webui If Ollama is on your computer, use this command: docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main To run Open WebUI with Nvidia GPU support, use this command: docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda If Ollama is on a Different Server, use this command: To connect to Ollama on another server, change the OLLAMA_BASE_URL to the server's URL: docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main After installation, you can access Open WebUI at http://localhost:3000. Enjoy! 😄 |
|
WebUI找不到ollama 通过apipost/postman可以访问ollama,确认Ollama正在运行,但WebUI不识别 这是WebUI Docker创建时的网络方式导致的,以open-webui为例 https://github.com/open-webui/open-webui#troubleshooting 该文档给出了多种docker创建方式 解决办法:将ollama直接映射进docker GPU docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama CPU docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama 这种方式不是IP映射,而是直接将ollama文件映射到docker中了, 本人是windows11,就是将windows上的文件映射到linux上用,也没有问题的,可见ollama具有平台兼容性 无模型可选 
虽然ollama中安装了LLM,但在WebUI中就是找不到, 这时可以在WebUI中下载一个模型,然后选择列表中就会出现刚刚下载的模型 |
|
|
|
|
vLLM简介
https://blog.vllm.ai/2023/06/20/vllm.html vLLM 是一个大模型部署及服务框架 vLLM支持的model https://docs.vllm.ai/en/latest/models/supported_models.html windows创建docker
先启动 docker desktop
这里要从windows访问docker里的端口,使用独立IP的方式,同时映射端口,
windows上访问直接localhost:8888即可,
既然端口映射为啥还要使用独立IP,因为本人在docker不使用独立IP时,仅端口映射结果是网络不通;
也许,你不会遇到该问题,具体方式不限,主要是解决以下几点问题:
1. linux环境
2. 能使用主机的GPU
3. 能访问外网,以方便下载大模型
4. 最后,就是一个独立的环境,如果换电脑了,只需要将docker镜像迁移过去就行了
docker network create --subnet=192.168.73.0/24 mydk
docker run -itd --privileged --name llm -h llm --net=mydk --ip 192.168.73.11 -p 8888:8888 -p 8080:8080 -p 8081:8081 -p 8008:8008 --gpus all -v /D/wks:/wks -v /h/soft:/opt/soft -v /T/data:/data -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all cent7 bash
docker exec -it llm bash
### 依赖安装
yum install -y net-tools libaio numactl
yum -y install gcc gcc-c++ autoconf make
yum install openssl-devel bzip2-devel
yum install centos-release-scl
yum install devtoolset-8-gcc*
/usr/bin/scl enable devtoolset-8 bash
官方安装
https://docs.vllm.ai/en/latest/getting_started/installation.html
NVIDIA PyTorch Docker image
If you have trouble building vLLM,
we recommend using the NVIDIA PyTorch Docker image.
# Use `--ipc=host` to make sure the shared memory is large enough.
docker run --gpus all -it --rm --ipc=host nvcr.io/nvidia/pytorch:23.10-py3
这里面已经安装好了CUDA,ubantu系统
root@a36d70ce15e2:/workspace# ll /usr/local/cuda
lrwxrwxrwx 1 root root 22 Oct 4 2023 /usr/local/cuda -> /etc/alternatives/cuda/
root@a36d70ce15e2:/workspace# which apt
/usr/bin/apt
root@a36d70ce15e2:/workspace# uname -a
Linux a36d70ce15e2 5.15.146.1-microsoft-standard-WSL2 #1 SMP Thu Jan 11 04:09:03 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux
PS C:\Users\83933> docker images|findstr "nvidia"
nvcr.io/nvidia/pytorch 23.10-py3 d6779f3e7f3f 8 months ago 22.1GB
docker network create --subnet=192.168.73.0/24 mydk docker run -itd --privileged --name llm -h llm --net=mydk --ip 192.168.73.11 -p 6006:6006 -p 8888:8888 -p 8080:8080 -p 8008:8008 --gpus all -v /C/wks:/opt/wks -v /T/soft:/opt/soft -v /D/app:/opt/app -v /T/data:/data -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all nvcr.io/nvidia/pytorch:23.10-py3 bash docker exec -it llm bash |
|
centos git lfs中的“lfs”是Large File Storage的缩写,即大文件存储。Git LFS是Git的一个扩展,主要用于管理大型文件,如图像、音频和视频文件等。通过使用Git LFS,开发者可以将大文件的实际内容存储在Git LFS服务器上,而只在Git仓库中存储大文件的文本指针,从而显著减小仓库的体积,提高性能,并更好地管理大文件。 curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash sudo yum install git-lfs # 对于CentOS 7或更早版本 ubantu
apt update
apt install sudo curl git
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt install git-lfs
要求是必须是linux系统,必须带GPU,
git lfs install
git clone https://huggingface.co/01-ai/Yi-6B-Chat
https://github.com/vllm-project/vllm
https://docs.vllm.ai/en/latest/getting_started/installation.html
安装注意点
- 要先安装CUDA,这里直接用的nvidia的docker images nvcr.io/nvidia/pytorch:23.10-py3
- 看一下CUDA版本,如果是12.1或以上版本直接
(vllm) xt@llm:~$ nvidia-smi
Fri Jun 28 01:34:33 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.119 Driver Version: 537.53 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4070 ... On | 00000000:01:00.0 Off | N/A |
| N/A 43C P8 2W / 80W | 0MiB / 8188MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
conda create -n vllm python=3.9 -y
conda activate vllm
# Install vLLM with CUDA 12.1.
pip install vllm
pip install vllm==0.4.0
sudo apt install net-tools
root@llm:/data/bigmodel# netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.11:40325 0.0.0.0:* LISTEN -
udp 0 0 127.0.0.11:44547 0.0.0.0:* -
python -m vllm.entrypoints.openai.api_server --model /data/bigmodel/Yi-6B-Chat --trust-remote-code --port 6006
curl http://localhost:6006/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-agiclass" \
-d '{
"model": "/data/bigmodel/Yi-6B-Chat",
"max_tokens":60,
"messages": [
{
"role": "user",
"content": "who are you"
}
]
}'
https://open.bigmodel.cn/api/paas/v4/chat/completions
curl https://open.bigmodel.cn/api/paas/v4/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 715c27776d19889a332309a4c81b3e0f.D6VnhU9eQl8Itjc3" \
-d '{
"model": "glm-4-0520",
"max_tokens":60,
"messages": [
{
"role": "user",
"content": "who are you"
}
]
}'
windows安装:结果安装失败
(base) PS C:\Users\83933> conda create -n vllm python=3.9 -y
conda activate vllm
(vllm) PS C:\Users\83933> nvidia-smi
Fri Jun 28 10:19:34 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 537.53 Driver Version: 537.53 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
pip install vllm
结果安装失败
(vllm) PS C:\Users\83933> pip install vllm
Collecting vllm
Using cached vllm-0.5.0.post1.tar.gz (743 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [17 lines of output]
Traceback (most recent call last):
File "C:\Users\83933\anaconda3\envs\vllm\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in
|
vLLM 支持分布式张量并行推理和服务,使用 Ray 管理分布式运行时,请使用以下命令安装 Ray: pip install ray 启动服务 要运行多 GPU 服务,请在启动服务器时传入 --tensor-parallel-size 参数。 例如,要在 2 个 GPU 上运行 API 服务器: 执行命令 python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/Yi-6B-Chat --dtype auto --api-key sk-agiclass --trust-remote-code --port 6006 --tensor-parallel-size 2
测试
curl http://localhost:6006/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-agiclass" \
-d '{
"model": "/root/autodl-tmp/Yi-6B-Chat",
"max_tokens":60,
"messages": [
{
"role": "user",
"content": "你是谁?"
}
]
}'
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:6006/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="Yi-6B-Chat",
prompt="你是谁?")
print("Completion result:", completion)
|
|
|
|
|
llm docker dev
|
LLM开发环境搭建
docker network create --subnet=192.168.73.0/24 mydk
docker run -itd --privileged --name llm -h llm --net=mydk --ip 192.168.73.11 -p 6006:6006 -p 8888:8888 -p 8080:8080 -p 8008:8008 -p 13301:13301 -p 33033:33033 --gpus all -v /C/wks:/opt/wks -v /D/soft:/opt/soft -v /D/app:/opt/app -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all nvcr.io/nvidia/pytorch:23.10-py3 bash
docker exec -it llm bash
注意事项:
这种docker本质上还是一个wsl的系统,它与真正的linux服务器上docker是有区别的,比如安装vllm时,就能体现出这种区别了
apt update
apt install sudo curl git
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt install git-lfs
apt install net-tools vim pkg-config ntpdate libncurses5 libxft-dev
apt install cmake
apt-get install libaio-dev tcl tk expect libldap2-dev libsasl2-dev
apt-get install libssl-dev #openssl
apt-get install p7zip-full
apt-get install libmysqlclient-dev
apt install daemonize fontconfig
apt-get install libffi7 libffi-dev
adduser xt
export PYTHONPATH=/data/jupyter/pyuban/lib/python3.11/site-packages
export PATH=/data/jupyter/pyuban/bin:$PATH
xt@llm:~$ nvidia-smi
Fri Jul 19 09:18:17 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.119 Driver Version: 537.53 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4070 ... On | 00000000:01:00.0 Off | N/A |
| N/A 43C P8 1W / 80W | 0MiB / 8188MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
两套环境 原生jupyter rsync -rltDv jupyter_gpu.tar.gz /data/ sudo apt-get install libsqlite3-dev File "/data/jupyter/pyuban/lib/python3.11/ssl.py", line 100, in
anaconda3
sh Anaconda3-2024.02-1-Linux-x86_64.sh
|
conda create --name wkflow python=3.11
conda activate wkflow
conda deactivate
conda remove -n wkflow --all
wkflow
pip install openai langgraph Agently==3.3.1.9 mermaid-python nest_asyncio
(wkflow) xt@llm:/opt/wks/bigmodel$ mkdir wkflow
(wkflow) xt@llm:/opt/wks/bigmodel$ cd wkflow/
(wkflow) xt@llm:/opt/wks/bigmodel/wkflow$ jupyter notebook
|
|
|
|
|
|
|
模型下载
https://hf-mirror.com/
域名 hf-mirror.com,用于镜像 huggingface.co 域名
|
huggingface-cli 是 Hugging Face 官方提供的命令行工具,自带完善的下载功能。 1. 安装依赖 pip install -U huggingface_hub 2. 设置环境变量 Linux export HF_ENDPOINT=https://hf-mirror.com Windows Powershell $env:HF_ENDPOINT = "https://hf-mirror.com" 建议将上面这一行写入 ~/.bashrc。 3.1 下载模型 huggingface-cli download --resume-download gpt2 --local-dir gpt2 3.2 下载数据集 huggingface-cli download --repo-type dataset --resume-download wikitext --local-dir wikitext |
非侵入式,能解决大部分情况。huggingface 工具链会获取HF_ENDPOINT环境变量来确定下载文件所用的网址,所以可以使用通过设置变量来解决。 HF_ENDPOINT=https://hf-mirror.com python your_script.py |
|
|
|
|
参考
GLM-4-9B 开源,探索模型极限