本地部署
https://mp.weixin.qq.com/s/3xW0NJVnMsc22R189w7YWQ https://ollama.com/library/deepseek-r1 DeepSeek-R1-Distill-Qwen-1.5B ollama run deepseek-r1:1.5b DeepSeek-R1-Distill-Qwen-7B ollama run deepseek-r1:7b ollama run deepseek-r1:8b ollama run deepseek-r1:14b ollama run deepseek-r1:32b ollama run deepseek-r1:70b
milVus向量数据库的安装步骤
https://blog.csdn.net/wangqiaowq/article/details/136163338
https://zhuanlan.zhihu.com/p/677763767
最近全网大火的报告,由清华新闻学院、人工智能学院双聘教授沈阳教授团队余梦珑博士后倾力打造
《DeepSeek:从入门到精通》1.0版发布!助你快速上手、精通运用,一起探索AI新视界。
链接: http://t.cn/A63evoRO 提取码: 9e72
|
官网:https://ollama.com
Github:https://github.com/ollama/ollama
curl -fsSL https://ollama.com/install.sh | sh
rm -rf /datai/bigmodel
sudo mkdir -p /datai/bigmodel/ollama
sudo chown -R bml:xt /datai/bigmodel/ollama
环境变量设置
export OLLAMA_MODELS=/datai/bigmodel/ollama
服务启动 ollama serve bml@kl:~$ sudo netstat -tunlp|grep oll tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 21280/ollama 拉取大模型 ollama pull llama3 ollama run llama3 ollama rm llama3 ollama list ollama run deepseek-r1:1.5b ollama run deepseek-r1:8b ollama run deepseek-r1:14b ollama run deepseek-r1:32b ollama run deepseek-r1:70b
|
from openai import OpenAI
#ollama serve
#ollama list
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='key',#必需但可以随便填写
)
chat_completion = client.chat.completions.create(
messages=[{'role': 'user','content': '我要健康,但之间没有运行过,过开始适合做哪些运动',}],
model='deepseek-r1:1.5b',
)
print(chat_completion.choices[0].message.content)
think 嗯,我想要找到一种既能保持健康又不需要在运动机器上走动的方法。之前总觉得如果经常健身的话挺不错的选择,主要是因为它能帮助我们提升身体素质和整体mindset。但是现在我觉得,可能有时候身体太忙了,或者说有些东西无法坚持下去,所以想试试其他的活动形式。 首先,我想到了瑜伽这个方法。听说瑜伽不仅能放松身心,还能增加对力量的感觉。但是我之前总觉得如果开始太多人说它不适合,特别是在没有特别运动能力的情况下。不过现在觉得,只要花时间在上面,应该是可以达到一定的效果。 然后是瑜伽流道。这个听起来比单纯的瑜伽要简单一些,适合需要练习更多动作的人。可能也容易坚持下去?但我不确定,不知道有没有别的更好的办法。 力量训练是另一种选择,比如举重或者带 weights。我觉得如果我能够找到好材料的话,可能就能完成,而且时间也不用太长,只要安排在下午或者晚上,感觉比较方便。不过要找合适的器械和方法可能需要花费一些时间。 力量骑车也是一个不错的选择,因为我可以跟自行车在一起跑。这样不仅锻炼身体,又能与朋友相处。但不知道是否适合所有人,特别是在一些人流量很大的时候。 跳绳是另外一个有趣的活动形式,因为它不用太多工具也能保持运动状态。不过,我想知道能不能找到有效的强度,否则可能会累伤。 力量球是一个容易理解的方式,可能能帮助我更好地放松和调节身体状态。不过我不确定是否有训练好的姿势,所以可能需要慢慢来。 力量划船和瑜伽划波也是比较有挑战性的活动,可能适合喜欢运动者。但会不会太紧张或者不适合我现在的健身量呢? 我可以尝试一些力量步行,如果能在下午或者晚上走几步,锻炼腰和 legs。这样可能可以同时进行不同的动作。 力量游泳,可能涉及到更长的距离,但如果我的时间允许的话,或许也能安排在傍晚或夜晚,让自己的身体有更多的运动机会。 力量跳舞,则不需要太多设备就能完成,感觉很轻松,特别是当周围的人不多的时候。这个方法可能会增加一些放松的过程,有助于全身的协调。 力量骑单车,如果我有自行车,可以在白天或晚上骑车前进和骑行的力量训练,这样也能保持活跃的运动模式。 力量划伞也是一个有趣的活动形式,可能需要找到一个适合他的伞方式来进行锻炼。不过我觉得在下雨天或者光线不好时可能会不太合适。 我觉得这些运动形式都需要时间和耐心,同时需要选择正确的器械和方法,所以可能需要慢慢来,逐步尝试,看看哪种最适合我现在的状态就好了。 也许我可以先从小规模的运动做起,比如简单的力量训练、瑜伽或者轻度步行,然后在坚持下来之后再来挑战更高强度的内容。如果一段时间后,感觉满意再往更高的级别发展比较好。 不过,在进行这些运动之前,我觉得需要确认一下自己对健身的兴趣和条件,确保自己能找到适合自己的锻炼方式。同时,避免过量的运动会影响健康,所以得权衡一下个人的需求和个人的生活习惯。 总之,我现在在寻找一种既能保持健康,又不经常用工具跑动的方法。经过一系列的想法和搜索,我认为比较实用的是力量训练、力量划船和力量跳舞这些活动形式。它们不需要太多工具也能有效地锻炼身体,同时还能让生活的其他部分保持轻松自在。 think 为了维持健康并减少可能的跑动次数,以下是一些适合你的方式: 1. **力量训练**:选择合适的锻炼器械(如杠铃、哑铃或带绳子使用的带 weights),在下午或晚上进行轻松的快节奏运动,持续30-60分钟。这能提升力量和协调感,同时不需要太多工具。 2. **力量划船与瑜伽划波**:如果喜欢挑战性的动作,请寻找适合你的划船姿势(如坐船、跨船等)。这些活动提供额外的锻炼,既能拉长距离也能增进肌肉放松,适合喜欢运动者的挑战。 3. **力量骑单车**:在天气温暖且没有太多人群时,可以选择骑行或滑板的方式。骑一辆自行车至早上或晚上完成少量步行,增加腰和腿的锻炼机会。 4. **力量跳舞与瑜伽**:在这个时候坐下,并坐在周围的朋友旁边做轻柔的跳跃练习。跳舞既放松身心又能让其他同伴感到轻松,特别适合在空旷环境中进行。 5. **力量球与力量划伞**:这些活动不需要设备也能拉近身体和释放肌肉紧张感。选择有适合自己姿势的伞方式进行力量球练习,同时在下雨天或光线较差时可以尝试划伞,注意安全。 6. **简单的力量训练或瑜伽流道**:无论时间多短,如果条件允许都可以安排一次力量流道或力量训练。这能帮助你保持适当的运动强度并增强动作。 7. **轻度步行与骑行**:在黄昏或黎明时分步行或骑行少量路段,这有助于放松全身肌肉,同时提升心肺功能。 这些运动形式既能有效锻炼身体又不涉及大量工具和机械,适合维持健康并且减少跑动次数。重要的是找到一个适合自己的方式来融入日常活动,以获得持续的运动体验。 |
from tpf.llm import chat_ollama
res = chat_ollama("上班很累了,办公看了一天的电脑,因为手机很好玩,下班后如何克制自己不玩手机?",model='deepseek-r1:1.5b')
print(res)
下班后克制自己不玩手机的策略如下: 1. **设定小目标**:每天设定完成几项任务的目标,比如完成几篇报告或处理几份文件,这样能激励自己坚持。 2. **利用提醒功能**:如果手机有提醒功能,定期设置关机提醒和充电提醒,帮助自己保持手机不被使用。 3. **选择安静环境**:在休息时找些安静的地方,如房间里的书桌或小本子,减少外界干扰。 4. **使用番茄工作法**:每天固定时间专注工作,比如25分钟专注,然后休息5分钟,这样高效又不容易分心。 5. **利用语音助手**:与家人或朋友聊天,缓解压力,同时也能保持手机的使用状态。 6. **选择替代工具**:如果手机没电,可以听音乐、看视频或用简单的任务完成工具(如番茄工作法)来代替。 通过这些方法,可以在不玩手机的情况下提升工作效率,帮助自己更好地放松和专注。 |
mkdir deepseek export OLLAMA_MODELS=/root/deepseek curl -fsSL https://ollama.com/install.sh | sh nohup ollama serve & ollama pull deepseek-r1:32b ssh -L 11435:localhost:11434 root@px-asia-3.matpool.com -p 29825 -N -q |
大模型文件格式
简介
safetensors 是由 Hugging Face 提出的一种安全、高效的机器学习模型权重存储格式。
它旨在替代传统的 PyTorch .pt 或 .pth 文件,
解决后者因使用 pickle 序列化可能存在的安全漏洞(如恶意代码执行)问题。
核心特点
1. 安全性
文件仅存储张量数据,不包含可执行代码,避免了反序列化时的恶意代码注入风险。
通过限制文件头大小(如 100MB)和内存访问范围,防止极端情况下的内存溢出攻击。
2. 高效加载
零拷贝技术:支持内存直接映射(mmap),跳过不必要的 CPU 数据复制,在 Linux 系统上加载速度比 PyTorch 快 2 倍。
惰性加载:允许仅加载部分张量,适合分布式或多 GPU 场景。
3. 跨框架兼容性
支持 PyTorch、TensorFlow 等框架,但主要集成于 Hugging Face 生态,常用于快速部署和安全敏感的模型共享。
4. 局限性
未包含模型的元数据(如架构、超参数),依赖外部配置文件。
在大模型的高效序列化、量化支持等方面较弱。
|
简介 .gguf(GPT-Generated Unified Format)由 Georgi Gerganov(llama.cpp 创始人)设计, 专为大规模语言模型(LLM)优化,是 GGML 格式的继任者。 它通过二进制编码和内存映射技术,显著提升模型加载效率,并支持量化以降低资源消耗。 核心特点 高效性与跨平台支持 内存映射(mmap):直接从磁盘加载模型到内存,减少内存占用和启动时间,尤其适合 CPU 推理。 单文件部署:包含所有元数据(如模型架构、超参数),无需额外依赖文件,简化跨平台共享。 量化支持 支持从 2 位到 8 位的多种量化方案(如 Q4_K、Q5_K),平衡模型精度与资源消耗,显著减小文件体积(如 70B 模型可从 140GB 压缩至 20GB)。 量化参数可灵活配置,适用于低资源设备(如手机、边缘计算)。 可扩展性与兼容性 元数据采用键值对结构,支持向后兼容的格式扩展。 可通过官方工具将 PyTorch、Safetensors 等格式转换为 GGUF。 应用场景 主要用于大语言模型(如 LLaMA、Gemma、Qwen)的推理部署,在 Hugging Face 上有超过 6000 个 GGUF 模型。 文件名通常以 Q+位数+变体 命名(如 q4_k_m.gguf),量化方案影响性能与精度。 |
特性 .safetensors .gguf 核心目标 安全存储与快速加载张量 高效加载大模型+量化支持 安全性 高(无代码执行风险) 中等(依赖二进制解析安全性) 元数据支持 无 包含完整元数据 量化支持 无 多级量化方案 适用场景 通用模型共享、Hugging Face 生态 大模型推理、低资源设备部署 跨平台能力 依赖框架支持 自包含,无需外部依赖 主要生态 Hugging Face llama.cpp、Hugging Face 能不用量化方案就不用,它不如原来的效果好,但若是资源有限,没办法了...也可用 参考 https://zhuanlan.zhihu.com/p/23807625841 |
|
|
|
|
离线部署·ollama
https://ollama.com/download/linux 安装包下载地址: https://ollama.com/download/ollama-linux-amd64.tgz GitHub手动安装文档地址: https://github.com/ollama/ollama/blob/main/docs/linux.md
Ollama 支持离线安装,具体步骤如下:
### 1. 下载 Ollama 安装包
- 访问 Ollama 官方下载页面,根据你的操作系统和架构选择合适的安装包。例如:
- **Linux (x86_64)**:下载 `ollama-linux-amd64.tgz`。
- **Linux (ARM64)**:下载 `ollama-linux-arm64.tgz`。
- **Windows 和 macOS**:可以直接从官网或国内中文站下载对应的安装文件。
### 2. 传输安装包到目标设备
将下载好的安装包通过 U 盘、局域网共享或其他方式传输到目标设备上。
### 3. 安装 Ollama
#### 对于 Linux 系统:
1. **解压安装包**:
```bash
tar -xzf ollama-linux-amd64.tgz -C /usr
```
或者将文件解压到其他目录,例如 `/opt/ollama`。
2. **创建服务文件**(可选,用于后台运行):
创建 `/etc/systemd/system/ollama.service` 文件,内容如下:
```ini
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
Environment="OLLAMA_MODELS=/path/to/models"
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
```
修改 `OLLAMA_MODELS` 为你的模型存储路径。
3. **启动服务**:
```bash
systemctl daemon-reload
systemctl enable ollama
systemctl start ollama
systemctl status ollama
```
#### 对于 Windows 和 macOS:
直接运行下载好的安装文件即可。
### 4. 配置环境变量(可选)
在 Linux 或 macOS 系统中,可以将 Ollama 的路径添加到环境变量中:
```bash
echo 'export PATH=$PATH:/path/to/ollama/bin' >> ~/.bashrc
source ~/.bashrc
```
### 5. 验证安装
运行以下命令检查 Ollama 是否安装成功:
```bash
ollama --version
```
如果显示版本号,则说明安装成功。
### 6. 离线安装模型(可选)
如果需要离线安装模型,可以按照以下步骤操作:
1. 在联网设备上运行 `ollama run model-name` 下载模型。
2. 找到模型文件(通常是 `.gguf` 文件)和对应的 `Modelfile` 文件。
3. 将这些文件传输到目标设备的模型目录下。
4. 使用以下命令导入模型:
```bash
ollama create model-name -f Modelfile
```
通过以上步骤,你可以在离线环境中成功安装和运行 Ollama。
|
cd /opt/soft curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz wget https://ollama.com/download/ollama-linux-amd64.tgz --no-check-certificate sudo tar -C /usr -xzf ollama-linux-amd64.tgz ollama serve 没有刻意安装GPU版,日志中显示也使用了GPU time=2025-03-25T16:06:21.707+08:00 level=INFO source=types.go:130 msg="inference compute" id=GPU-4e096a81-7ca7-6220-38f9-cfec732f72d4 library=cuda variant=v12 compute=8.9 driver=12.6 name="NVIDIA GeForce RTX 4070 Laptop GPU" total="8.0 GiB" available="6.9 GiB" $ sudo netstat -tunlp |grep 11434 tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 1985/ollama $ ollama -v ollama version is 0.6.1 |
https://modelscope.cn/models/syutung2/DeepSeek-R1-Distill-Qwen-1.5B-1949-Q4_2_K-GGUF/files Q4:4位量化位 下面的链接有8位量化位 https://modelscope.cn/models/lmstudio-community/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/files DeepSeek-R1-Distill-Qwen-1.5B-Q8_0.ggufGGUF 1.89GB cd /data/models/deepseek$ git lfs install git clone https://www.modelscope.cn/syutung2/DeepSeek-R1-Distill-Qwen-1.5B-1949-Q4_2_K-GGUF.git cd DeepSeek-R1-Distill-Qwen-1.5B-1949-Q4_2_K-GGUF/ rm -rf .git deepseek@uu:~$ cat Modelfile from /data/models/deepseek/DeepSeek-R1-Distill-Qwen-1.5B-1949-Q4_2_K-GGUF/DeepSeek-R1-Distill-Qwen-1.5B-1949-Q2_K.gguf ollama create DeepSeek-R1-Distill-Qwen-1.5B -f Modelfile $ ollama list NAME ID SIZE MODIFIED DeepSeek-R1-Distill-Qwen-1.5B:latest 026b2a354fee 752 MB 6 seconds ago |
https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/files sudo apt install curl git sudo curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash sudo apt install git-lfs git lfs install git clone https://www.modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF.git 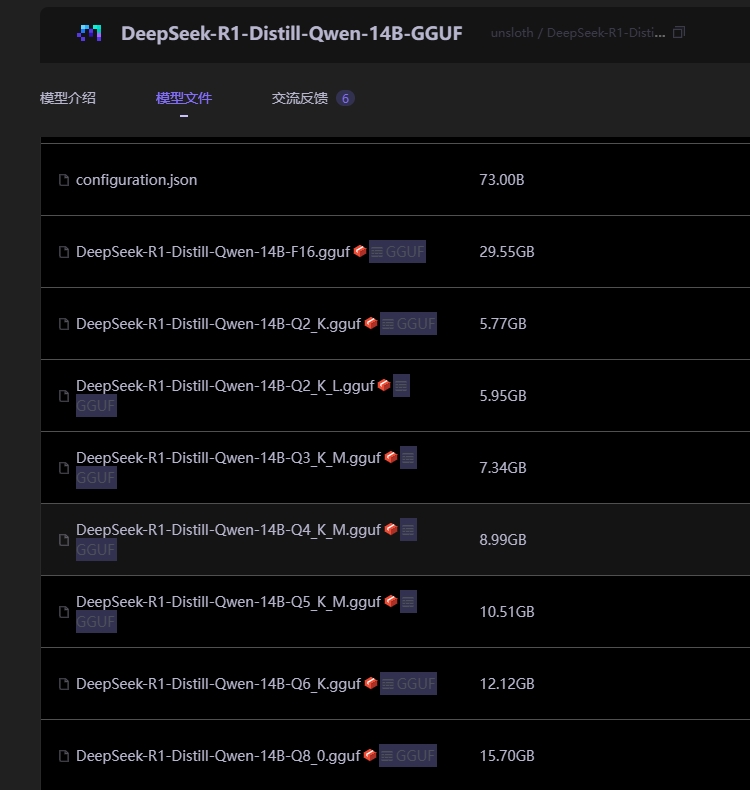
ollama serve ollama create DeepSeek-R1-14B-Q4 -f /wks/models/deepseek/mf_14b_q4 vim mf_14b_q8 from /wks/models/deepseek/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf ollama create DeepSeek-R1-14B-Q8 -f /wks/models/deepseek/mf_14b_q8 vim mf_14b_f16 from /wks/models/deepseek/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-F16.gguf ollama create DeepSeek-R1-14B-F16 -f /wks/models/deepseek/mf_14b_f16 ollama list $ ollama list NAME ID SIZE MODIFIED DeepSeek-R1-14B-Q4:latest 61aae878c40b 15 GB 6 seconds ago DeepSeek-R1-Distill-Qwen-1.5B:latest 026b2a354fee 752 MB 17 hours ago |
|
|
本地部署·vllm
https://modelscope.cn/models/deepseek-ai/DeepSeek-R1 reasoning 英/ˈriːznɪŋ , ˈriːzənɪŋ/ 美/ˈriːznɪŋ , ˈriːzənɪŋ/ n. 推理;论证;推想;理性的观点 v. 推理;理解;思考;推断;推论 adj. 能推理的;有关推理的 使用 vLLM 本地部署 DeepSeek https://zhuanlan.zhihu.com/p/27650814946 deepseek官方文档 https://api-docs.deepseek.com/zh-cn/api/deepseek-api 模型下载·git下载 前提:已安装好python环境 https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/files apt install curl git curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash apt install git-lfs root@uu:/wks/models# mkdir deepseek root@uu:/wks/models# chown -R deepseek:deepseek deepseek/ su - deepseek cd /wks/models/deepseek/ git lfs install git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git deepseek@uu:/wks/models/deepseek/DeepSeek-R1-Distill-Qwen-1.5B$ rm -rf .git deepseek@uu:/wks/models/deepseek/DeepSeek-R1-Distill-Qwen-1.5B$ cd .. deepseek@uu:/wks/models/deepseek$ du -sh DeepSeek-R1-Distill-Qwen-1.5B/ 3.4G DeepSeek-R1-Distill-Qwen-1.5B/
git lfs install
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B.git
$ du -sh DeepSeek-R1-Distill-Qwen-14B/
28G DeepSeek-R1-Distill-Qwen-14B/
|
pip install uvicorn -i https://pypi.tuna.tsinghua.edu.cn/simple pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple pip install sse_starlette -i https://pypi.tuna.tsinghua.edu.cn/simple vLLM 是一款专为 高效推理 设计的大语言模型框架,其基于 PagedAttention 算法,性能显著优于传统方案。 vllm也可以在CPU上进行安装 # 安装PyTorch CPU版本 pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu pip install vllm VLLM的CPU安装是可行的,但性能会显著受限。建议根据实际需求(推理/训练)和硬件条件选择部署环境。 轻量化替代:若仅需在CPU上运行,可考虑使用VLLM的轻量化版本(如蒸馏模型)或降低输入分辨率/模型复杂度。 CUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server --model ./path/deepseek_model --port 8000 --tensor-parallel-size 2 CUDA_VISIBLE_DEVICES=0,1 表示让程序看到设备 ID 为 0 和 1 的两个 GPU, 同时 --tensor-parallel-size 2 表示使用 2 个 GPU 进行张量并行计算,以加速推理过程。 其中./path/deepseek_model 指定模型文件路径,替换为本地自己的,--port 可自定义端口。 CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model /wks/models/deepseek/DeepSeek-R1-Distill-Qwen-1.5B --port 8000 注意事项 确保模型路径正确,文件无损坏。 推理服务启动后,可通过浏览器访问 http://localhost:8000 检查服务状态。 或观察终端输出,如果看到类似 INFO: Started server process 和 INFO: Uvicorn running on ... 的信息,则表示 vLLM 服务启动成功。 注意 GPU 显存: 启动 vLLM 服务会占用 GPU 显存。请确保您的 GPU 显存足够运行模型。如果显存不足,可能会导致启动失败或运行缓慢。您可以尝试减小 --max-model-len 参数或使用更小规模的模型。 如果启动 vLLM 服务时遇到 CUDA 相关错误,请检查您的 NVIDIA 驱动版本和 CUDA 环境是否正确安装。 |
|
DeepSeek-R1-Distill-Qwen-32B模型与deepseek-r1:32b模型区别 ### 训练方式 - **DeepSeek-R1-Distill-Qwen-32B**:是通过知识蒸馏技术从 DeepSeek-R1 模型中蒸馏出来的。它以 Qwen2.5-32B 为基础,使用 DeepSeek-R1 生成的样本进行微调。 - **DeepSeek-R1:32b**:是 DeepSeek-R1 系列中的一个版本,经过了完整的多阶段训练过程以及强化学习调整。 ### 参数量与架构 - **DeepSeek-R1-Distill-Qwen-32B**:参数量为 32B,基于 Qwen 架构。 - **DeepSeek-R1:32b**:参数量同样为 32B,但其架构是 DeepSeek-R1 的原始架构。 ### 性能表现 - **推理能力**:DeepSeek-R1-Distill-Qwen-32B 在推理能力上表现出色,推理速度比原始模型提高了约 50 倍。在数学、代码与推理任务上,其性能超越了 OpenAI-o1-mini。 - **速度与资源消耗**:通常情况下,蒸馏版本的模型在推断过程中速度更快,计算成本更低。因此,DeepSeek-R1-Distill-Qwen-32B 在资源消耗方面可能更具优势。 - **精度与泛化能力**:DeepSeek-R1:32b 作为未经蒸馏的完整模型,在更多样化的测试集上可能展示出更强的表现力,尤其是在面对未见过的数据分布时,能够保持较高的预测质量。 ### 适用场景 - **DeepSeek-R1-Distill-Qwen-32B**:更适合在资源有限的环境中使用,例如在普通消费级硬件上进行部署。它适用于需要高效推理和较低硬件成本的场景。 - **DeepSeek-R1:32b**:更适合需要高精度和强大推理能力的复杂任务,尤其是在专业领域和研究场景中。 |
pip uninstall vllm pip install torch==2.4.0 torchaudio==2.4.0 torchvision==0.19.0 transformers==4.44.0 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install tokenizers==0.19.1 triton==3.0.0 vllm==0.5.5 vllm-flash-attn==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple vllm==0.5.5出来的时间是2024年8月,也就是说其他依赖包差不多也要这个时间的 Successfully installed audioread-3.0.1 datasets-3.4.1 dill-0.3.8 fsspec-2024.12.0 gguf-0.9.1 lazy_loader-0.4 librosa-0.11.0 lm-format-enforcer-0.10.6 multiprocess-0.70.16 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.20.5 nvidia-nvtx-cu12-12.1.105 outlines-0.0.46 pooch-1.8.2 pyairports-2.1.1 pyarrow-19.0.1 soundfile-0.13.1 soxr-0.5.0.post1 tokenizers-0.19.1 torch-2.4.0 torchvision-0.19.0 transformers-4.44.0 triton-3.0.0 vllm-0.5.5 vllm-flash-attn-2.6.1 xformers-0.0.27.post2 xxhash-3.5.0 |
deepseek@uu:~$ CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model /wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B --port 8000 --max-model-len 4096 nohup CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model /wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B --port 8000 --max-model-len 4096 >/tmp/vllm_dp15.log 2>&1 & 4096使用了6G显存 deepseek@uu:~$ nvidia-smi Tue Mar 25 13:51:03 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 560.41 Driver Version: 561.03 CUDA Version: 12.6 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4070 ... On | 00000000:01:00.0 On | N/A | | N/A 50C P8 4W / 75W | 6786MiB / 8188MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B 两种启动方式 https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1 vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2 https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B |
|
手工下载的访问方法 from openai import OpenAI client = OpenAI( base_url='http://127.0.0.1:8000/v1/', api_key='token', # 随意写 )
response = client.chat.completions.create(
model='/wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B', # ModelScope Model-Id
messages=[
{
'role': 'user',
'content': '你好'
}
],
stream=True
)
done_reasoning = False
for chunk in response:
delta = chunk.choices[0].delta
# print(delta) #ChoiceDelta(content='你好', function_call=None, refusal=None, role=None, tool_calls=None)
answer_chunk = delta.content
if hasattr(delta, 'reasoning_content') and callable(getattr(delta, 'reasoning_content')):
print("obj has a callable my_method")
reasoning_chunk = delta.reasoning_content
if reasoning_chunk != '':
print(reasoning_chunk, end='',flush=True)
elif answer_chunk != '':
if not done_reasoning:
print('\n\n === Final Answer ===\n')
done_reasoning = True
print(answer_chunk, end='',flush=True)
=== Final Answer === NoneAlright, the user just said "你好". That's Chinese for "hello". I should respond in a friendly and welcoming manner. I'll say "你好!有什么我可以帮你的吗?" which means "Hello! How can I assist you?" That should be good to keep the conversation going. think 你好!有什么我可以帮你的吗? 通过ModelScope下载的访问方法
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1/',
api_key='MODELSCOPE_SDK_TOKEN', # ModelScope Token
)
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-R1-Distill-Qwen-14B', # ModelScope Model-Id
messages=[
{
'role': 'user',
'content': '你好'
}
],
stream=True
)
done_reasoning = False
for chunk in response:
reasoning_chunk = chunk.choices[0].delta.reasoning_content
answer_chunk = chunk.choices[0].delta.content
if reasoning_chunk != '':
print(reasoning_chunk, end='',flush=True)
elif answer_chunk != '':
if not done_reasoning:
print('\n\n === Final Answer ===\n')
done_reasoning = True
print(answer_chunk, end='',flush=True)
|
|
python环境
启动ollama服务
root@uu:/# su - ollama
ollama@uu:~$ ollama serve &
adduser deepseek
echo '%deepseek ALL=(ALL) NOPASSWD:ALL' > /etc/sudoers.d/deepseek
su - deepseek
sudo mkdir -p /wks/python/deepseek/
sudo chown -R deepseek:deepseek /wks/python/deepseek/
sudo tar -xvf Python-3.11.11.tar.xz
sudo chown -R deepseek:deepseek Python-3.11.11
cd /wks/python/soft/Python-3.11.11
./configure --prefix=/wks/python/deepseek/ --enable-optimizations
checking for stdlib extension module _sqlite3... yes
checking for stdlib extension module _tkinter... yes
checking for stdlib extension module _uuid... yes
checking for stdlib extension module zlib... yes
checking for stdlib extension module _bz2... yes
checking for stdlib extension module _lzma... yes
checking for stdlib extension module _ssl... yes
checking for stdlib extension module _hashlib... yes
checking for stdlib extension module _testcapi... yes
checking for stdlib extension module _testclinic... yes
checking for stdlib extension module _testinternalcapi... yes
checking for stdlib extension module _testbuffer... yes
checking for stdlib extension module _testimportmultiple... yes
checking for stdlib extension module _testmultiphase... yes
checking for stdlib extension module _xxtestfuzz... yes
checking for stdlib extension module _ctypes_test... yes
make
make install
cd /wks/python/deepseek/bin
ln -s python3 python
ln -s pip3 pip
export PYTHONHOME=/wks/python/deepseek
export PATH=$PYTHONHOME/bin:$PATH
which python
which pip
pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install python-dotenv -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
|
ollama用户 - 在线安装ollama deepseek - 离线安装的ollama - vllm 环境 ,torch2.4,transformer 4.44
|
|
|
|
|
|
|
vllm与ollama对比
|
1.5B CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model /wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B --port 8000 --max-model-len 4096 CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model /wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B --port 8000 --max-model-len 8192
from openai import OpenAI
client = OpenAI(
base_url='http://127.0.0.1:8000/v1/',
api_key='token', # ModelScope Token
)
流式
response = client.chat.completions.create(
model='/wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B', # ModelScope Model-Id
messages=[{'role': 'user','content': '我要健康,但之间没有运行过,过开始适合做哪些运动',}],
stream=True
)
done_reasoning = False
for chunk in response:
delta = chunk.choices[0].delta
print(delta) #ChoiceDelta(content='你好', function_call=None, refusal=None, role=None, tool_calls=None)
answer_chunk = delta.content
if hasattr(delta, 'reasoning_content') and callable(getattr(delta, 'reasoning_content')):
print("obj has a callable my_method")
reasoning_chunk = delta.reasoning_content
if reasoning_chunk != '':
print(reasoning_chunk, end='',flush=True)
elif answer_chunk != '':
if not done_reasoning:
print('\n\n === Final Answer ===\n')
done_reasoning = True
print(answer_chunk, end='',flush=True)
对于这个问题--max-model-len 4096不够用,需要将之调整为--max-model-len 8192
响应时间 15-19秒之间
流式的输出是一个单词一个单词的返回,但每个返回是带有func_call,可以使用tools 确保ChoiceDelta(content='每次', function_call=None, refusal=None, role=None, tool_calls=None) 每次ChoiceDelta(content='运动', function_call=None, refusal=None, role=None, tool_calls=None) 运动ChoiceDelta(content='都', function_call=None, refusal=None, role=None, tool_calls=None) 都ChoiceDelta(content='有效', function_call=None, refusal=None, role=None, tool_calls=None) 有效ChoiceDelta(content='且', function_call=None, refusal=None, role=None, tool_calls=None) 且ChoiceDelta(content='有趣', function_call=None, refusal=None, role=None, tool_calls=None) 有趣ChoiceDelta(content='。', function_call=None, refusal=None, role=None, tool_calls=None) 。ChoiceDelta(content='', function_call=None, refusal=None, role=None, tool_calls=None) 非流式
response = client.chat.completions.create(
model='/wks/bigmodels/DeepSeek-R1-Distill-Qwen-1.5B', # ModelScope Model-Id
messages=[{'role': 'user','content': '我要健康,但之间没有运行过,过开始适合做哪些运动',}],
stream=False
)
print(response.choices[0].message.content)
嗯,我想要健康但没有进行过运动,但又想做一些适合的运动。这有点让我困惑,因为通常健康的人会经常运动,但也许我暂时不打算这样做。不过,为了长期的健康,我觉得还是需要进行一些运动,以保持活跃的体魄和增强体质。
那我应该做哪些适合的运动呢?首先,我想到的可能是跑步,因为它是全身性的运动,能帮助你提高心肺功能和肌肉力量。不过,有时候可能需要先做一些热身运动,比如慢跑、骑自行车或者进行简单的拉伸,以确保你有足够的能量来完成跑步。
接下来,瑜伽可能也是一个不错的选择。瑜伽可以增强动作的灵活性和力量,同时有助于放松身心,恢复肌肉和关节。我可能会选择一些简单的瑜伽动作,比如平板支撑、深蹲或者仰卧起坐,这些动作对身体来说都很适合,而且练习起来也不需要太多的时间。
另外,游泳也是一个不错的选择。游泳不仅能帮助你放松身心,还能提升心肺功能和耐力。不过,游泳可能需要一定的体力,所以一开始可能需要先进行一些热身运动,比如游泳或慢跑,确保你有足够的体力来完成游泳动作。
力量训练也是一个好的选择,特别是如果有时间的话。我可以选一些简单但有效的力量训练,比如深蹲、素数引体向上、俯卧撑等。这些力量训练可以帮助我增强肌肉力量,同时也有助于饮食的调整,比如多摄入蛋白质和健康脂肪,减少脂肪的摄入量。
力量训练需要一些时间,所以我可能会先进行热身运动,比如慢跑或散步,确保我能保持足够的体力来完成这些力量训练。此外,力量训练后还可以进行一些休息和恢复,这样有助于身体恢复,避免受伤。
最后,力量训练也可以帮助我保持良好的状态,提升自信心,这些都对长期的健康有帮助。如果我开始进行力量训练,我可能会先享受一段时间的放松和恢复,然后再逐渐增加强度,确保自己能够不断进步。
不过,我需要注意的是,任何运动都需要适量的饮食和充足的睡眠,才能保证健康。我可能会先调整饮食,多吃一些蛋白质ated的食材,比如鱼、肉类和豆类,同时避免过多的脂肪和碳水化合物。充足的睡眠也很重要,所以我会确保每天都有足够的休息时间,避免熬夜。
综上所述,我应该先进行热身运动,然后是瑜伽、游泳或力量训练,最后是放松和休息。这样不仅有助于保持健康,还能帮助我逐步恢复并提升自己的身体和心理状态。
think
为了保持健康且不进行运动,建议先进行热身运动,然后是瑜伽、游泳或力量训练。
热身运动可以帮助你调整 your body 和 mind,准备好进入运动状态。
瑜伽和力量训练则可以帮助你增强肌肉力量和整体身体素质。
游泳则是一个适合身体条件较好的选择。
最后,放松和休息是恢复和增强身体的重要步骤。
通过这些方法,你可以逐步恢复健康,同时享受放松和提升自我带来的成就感
10.8秒
|
|
|
|
|
|
|
|
参考