chatglm
|
简介 https://arxiv.org/abs/2406.12793 https://github.com/THUDM/GLM-4
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
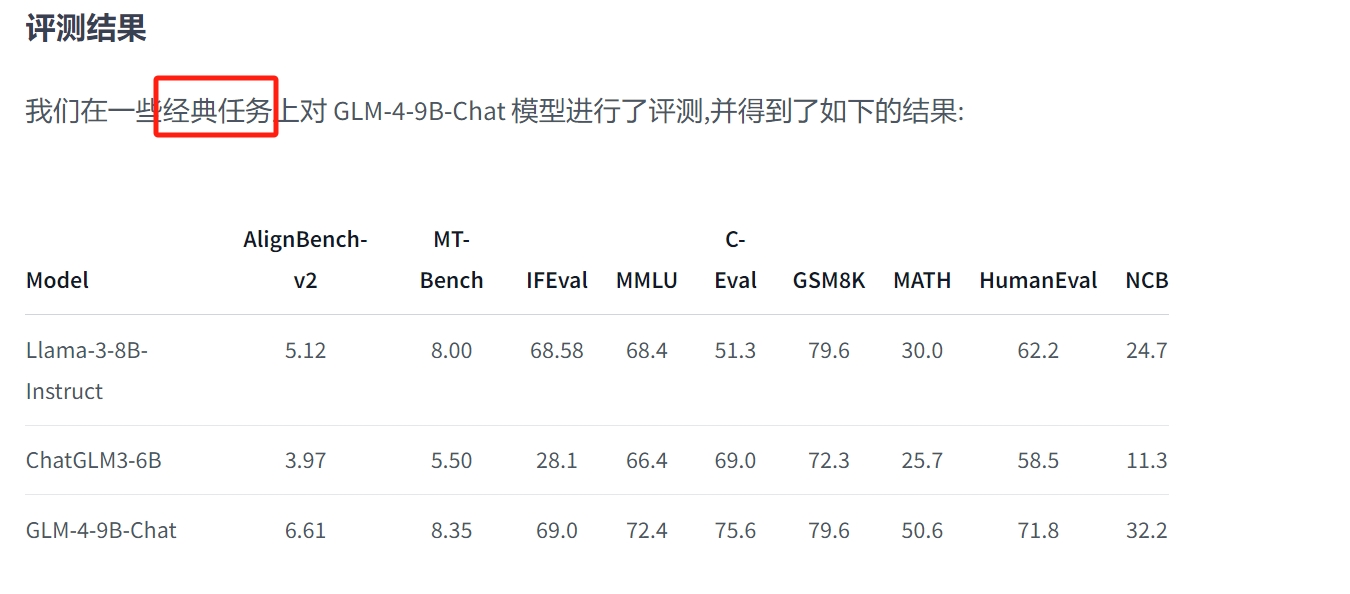
在语义、数学、推理、代码和知识等多方面的数据集测评中,
GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。
除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、
自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。
本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。
我们还推出了支持 1M 上下文长度(约 200 万中文字符)的模型。
下载 https://huggingface.co/THUDM/glm-4-9b-chat apt install curl git curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash apt install git-lfs git lfs install cd /root/autodl-tmp nohup git clone https://www.modelscope.cn/models/ZhipuAI/glm-4-9b-chat.git >/tmp/git.log 2>&1 &
# du -sh glm-4-9b-chat/
36G glm-4-9b-chat/
# cd glm-4-9b-chat/
# ls
LICENSE model-00002-of-00010.safetensors model-00010-of-00010.safetensors
README.md model-00003-of-00010.safetensors model.safetensors.index.json
README_en.md model-00004-of-00010.safetensors modeling_chatglm.py
config.json model-00005-of-00010.safetensors tokenization_chatglm.py
configuration.json model-00006-of-00010.safetensors tokenizer.model
configuration_chatglm.py model-00007-of-00010.safetensors tokenizer_config.json
generation_config.json model-00008-of-00010.safetensors
model-00001-of-00010.safetensors model-00009-of-00010.safetensors
# du -sh .git
18G .git
# rm -rf .git
# cd ..
# du -sh glm-4-9b-chat/
18G glm-4-9b-chat/
GLM-4-9B系列 
硬件配置 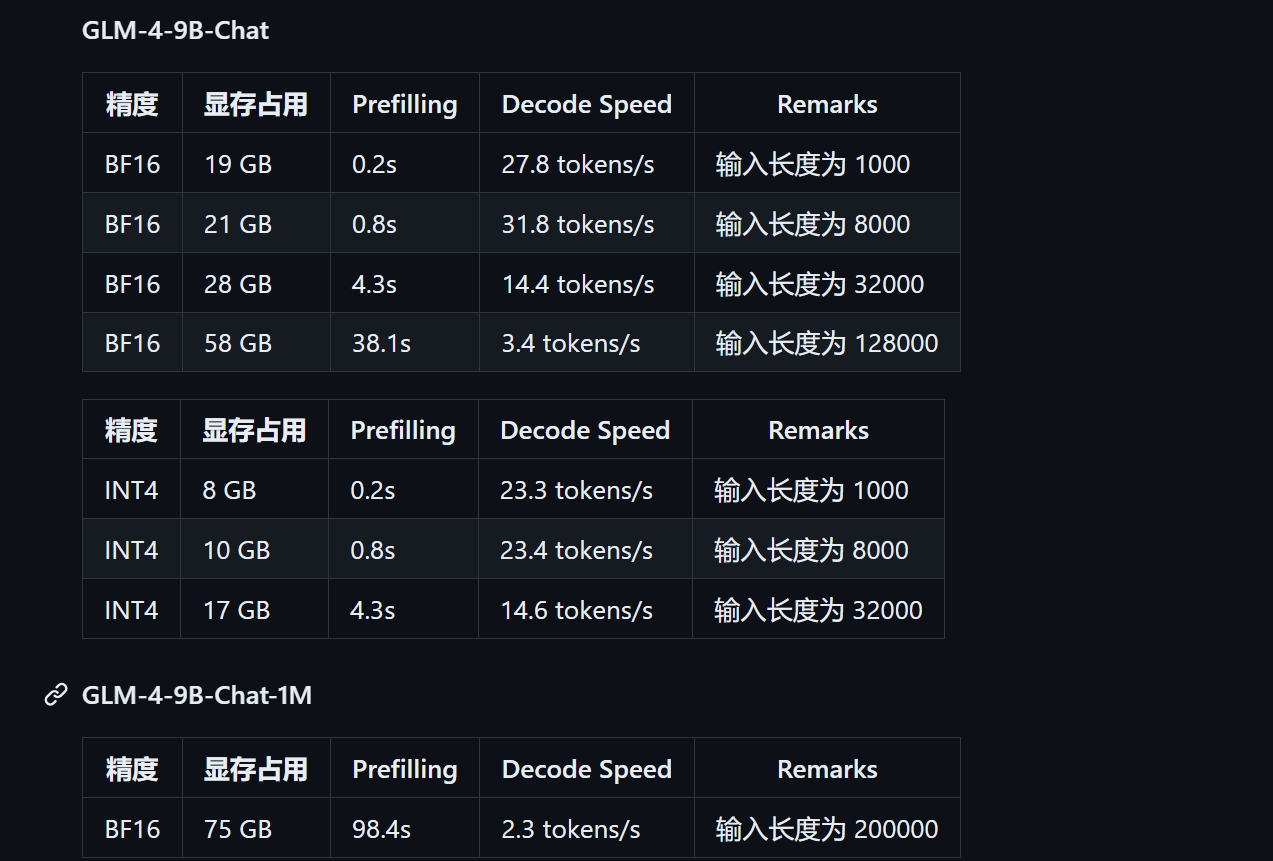
https://github.com/THUDM/GLM-4/tree/main/basic_demo
GLM-4V-9B 一次会话支持一张图像
|
cpp (c++ c plus plus) - 纯 C/C++ 实现,无需外部依赖。 - 针对使用 ARM NEON、Accelerate 和 Metal 框架的 Apple 芯片进行了优化。 - 支持适用于 x86 架构的 AVX、AVX2 和 AVX512。 - 提供 F16/F32 混合精度,并支持 2 位至 8 位整数量化。 参考:https://github.com/li-plus/chatglm.cpp 部署 chatglm3
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
git submodule update --init --recursive
windows上可能性能差一点,本地部署需要量化
Quantize Model 量化模型
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
通过 convert 专为 GGML 格式
- 用于 convert.py 将 ChatGLM-6B 转换为量化的 GGML 格式。要将 fp16 原始模型转换为 q4_0(量化 int4)GGML 模型,请运行:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o chatglm3-ggml.bin
在命令行启动服务
第一步:使用 CMake 配置项目并在当前目录下创建一个名为 "build" 的构建目录¶
cmake -B build
第二步:使用先前生成的构建系统文件在构建目录 "build" 中构建项目,采用并行构建和 Release 配置
cmake --build build -j --config Release
第三步:运行
./build/bin/main -m chatglm3-ggml.bin -p 你好
启动 web 服务
python3 ./examples/web_demo.py -m chatglm3-ggml.bin
更多模型
https://github.com/ggerganov/llama.cpp
|
智谱AI,全称为北京智谱华章科技有限公司,是一家专注于AI大模型研发的创业公司。以下是对智谱AI的详细介绍: 一、公司背景 成立时间:2019年6月11日 所属地:北京 创始人背景:由清华大学计算机系知识工程研究室团队的技术成果转化而来,团队成员具有丰富的学术和研发经验。CEO张鹏在清华大学计算机系获得本科和博士学位,研究方向为知识图谱。董事长刘德兵师从高文院士,曾任清华数据科学研究院科技大数据研究中心副主任。 二、技术实力 研发方向:智谱AI致力于打造新一代认知智能通用模型,提出了Model as a Service(MaaS)的市场理念。公司合作研发了双语千亿级超大规模预训练模型GLM-130B,并主导构建了高精度通用知识图谱,把两者有机融合为数据与知识双轮驱动的认知引擎。 产品矩阵:基于上述技术,智谱AI推出了多个AIGC产品,包括ChatGLM系列模型、高效率代码模型CodeGeeX、高精度文图生成模型CogView等,以及认知大模型平台Bigmodel.ai。此外,智谱AI还开发了生成式AI助手智谱清言。 三、融资情况 融资历程:智谱AI自成立以来,已完成多轮融资,投资方包括君联资本、启明创投、中科创星、美团、蚂蚁、阿里、腾讯、小米、金山、顺为、Boss直聘、好未来、红杉、高瓴等多家知名机构。据公开资料,智谱AI在2023年累计获得超过25亿人民币的融资,企业估值高达100亿元,是国内AI领域的独角兽企业。 最新动态:2024年7月,智谱AI获得浙江华策投资的战略融资,具体交易金额未披露。此前,公司还完成了由北京市人工智能产业投资基金光速光合参与的C轮融资。 四、市场应用 行业应用:智谱AI的GLM大模型已被应用到政务、金融、能源等多个领域,合作伙伴包括阿里、腾讯云、火山引擎、华为、美团、微软、OPPO、海天瑞声等数十家公司。 定制化服务:根据客户需求,智谱AI提供大模型定制化开发服务,包括云端私有化、本地私有化等多种部署方式,以及标准版大模型通过API接入方式收费。 五、发展目标 未来规划:智谱AI的目标是将大模型能力更快地推向市场,并拓展生态和朋友圈。公司将继续加码基座大模型研究,并探索更多AI技术的应用场景和商业模式。 综上所述,智谱AI是一家在AI大模型领域具有深厚技术实力和丰富产品矩阵的创业公司,其发展前景广阔,备受市场关注。
|
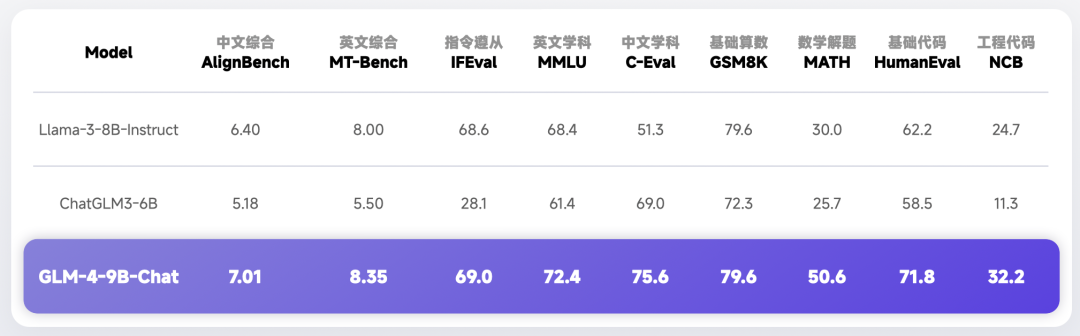
AlignBench-v2 含义: AlignBench-v2是由清华大学自然语言处理实验室(THUNLP)开发的开源项目, 专门用于评估和比较不同文本对齐算法的性能。 在自然语言处理领域,文本对齐是将两个或多个文本序列中的对应元素进行匹配的关键任务, 如多语种翻译、信息检索和知识图谱构建等。 AlignBench-v2提供了标准化的测试集和评估指标,包括准确率、召回率、F1分数等, 使得研究人员和开发者能够公正地比较他们的算法,并推动该领域的进步。 特点: 多样化数据集:包含多种类型和来源的文本对齐数据集,覆盖各种实际应用场景。 模块化架构:允许用户轻松接入自己的文本对齐模型,并便捷地更换不同的评估策略。 社区支持:拥有活跃的社区,不断更新的数据集和新的挑战,有助于保持项目的活力。 MT-Bench 含义: MT-bench,即Machine Translation Benchmark, 是一种用于衡量大语言模型在机器翻译任务上性能的综合性评估指标。 它旨在提供一个全面的评估工具,以评估模型在处理不同语言对、各种文本类型和语境下的翻译表现。 MT-bench不仅关注翻译的准确性,还考虑模型对多样性、流畅性、语法正确性等方面的影响。 相关指标: BLEU:通过比较生成的翻译和参考翻译之间的匹配程度来计算分数。 TER:通过编辑距离计算模型生成的翻译和参考翻译之间的相似性。 METEOR:考虑精确度、召回率等多个因素。 ROUGE、CHRF、BLEURT等也是常用的评估指标。 IFEval 含义: IFEval是一个直接且易于复制的评估基准,专注于评估语言模型在指令遵循方面的熟练程度。 它围绕着一组“可验证的指令”构建,如“写出超过400个单词”和“至少三次提到人工智能的关键字”。 通过构建包含这些可验证指令的提示,IFEval能够评估模型是否准确遵循了指令。 特点: 易于复制:提供标准化的评估方法和数据集。 指令可验证:确保评估结果具有客观性和准确性。 MMLU 含义: MMLU(Massive Multitask Language Understanding)基准测试旨在评估大语言模型在多种自然语言理解任务上的性能。它通常包含一系列多样化的任务,如阅读理解、常识推理、文本分类等,以全面衡量模型的能力。 特点: 多任务:涵盖多种自然语言理解任务。 广泛覆盖:能够评估模型在不同领域和任务上的泛化能力。 C-Eval 含义: C-Eval是一个针对中文大模型的知识和推理能力评估基准。 它包含覆盖人文、社科、理工等多个学科方向的题目, 旨在测试模型在知识型任务和推理任务上的表现。 特点: 针对性强:专注于中文大模型的评估。 广泛覆盖:包含多个学科方向的题目。 区分度高:能够区分模型在知识和推理能力上的强弱。 GSM8K 含义: GSM8K是一个用于评估多步数学推理能力的数据集,包含8.5K由人编写的小学数学题。 这些题目要求模型具备解决多步骤数学问题的能力。 特点: 多步推理:要求模型具备解决复杂数学问题的能力。 实用性强:与现实生活中的数学问题紧密相关。 MATH 含义: MATH数据集用于评估模型解决数学问题的能力,包含12,500个高中数学竞赛题。这些题目涉及广泛的数学概念和技能,对模型的数学能力提出了很高的要求。 特点: 难度高:包含高中数学竞赛题,对模型的数学能力提出挑战。 实用性强:有助于评估模型在解决实际应用中数学问题的能力。 HumanEval 简述: HumanEval是一个评估语言模型在解决编程和代码相关任务上表现的基准。 它要求模型根据自然语言指令编写代码,并评估代码的正确性和执行效果。
NCB ChatGLM官方指出的是工程代码,也搜索出了另外一种解释
NCB 值越高,表示模型对该类别的预测结果越准确
NCB(Normalized Cumulative Boost)是一种常用的模型评估指标,用于评估分类模型的性能。
NCB 指标衡量的是模型在每个类别上的累积提升率,
即模型对每个类别的预测结果相对于随机猜测的改进率。
NCB 值越高,表示模型对该类别的预测结果越准确。
NCB 计算公式为:
NCB = (TPR - TNR) / (1 - TNR)
其中:
* TPR(True Positive Rate):实际正例占总正例的百分比
* TNR(True Negative Rate):实际负例占总负例的百分比
NCB 值的范围是[-1, 1],其中:
* NCB = 1 表示模型对该类别的预测结果完全准确
* NCB = 0 表示模型对该类别的预测结果与随机猜测相同
* NCB < 0 表示模型对该类别的预测结果不准确
NCB 指标可以用于评估模型对不同类别的性能,帮助模型选择器选择合适的模型。
|
- 访问github等外网速度慢时可开启学术加速 开启学术加速 source /etc/network_turbo 取消学术加速,如果不再需要建议关闭学术加速,因为该加速可能对正常网络造成一定影响 unset http_proxy && unset https_proxy |
|
|
部署
ssh -p 13627 root@connect.westb.seetacloud.com
K6am0ejNWveL
git clone https://github.com/THUDM/GLM-4.git
nohup git clone https://github.com/THUDM/GLM-4.git &
pip install uvicorn
pip install vllm
pip install sse_starlette
cd /root/autodl-tmp/GLM-4/basic_demo
CUDA_VISIBLE_DEVICES=0 python openai_api_server.py
12G内存不够
[rank0]: torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 36.00 MiB. GPU
rsync -e 'ssh -p10155' -avP root@connect.westb.seetacloud.com:/root/autodl-tmp/GLM-4 ./
CUDA_VISIBLE_DEVICES=0 python openai_api_server.py pynvml.NVMLError_InvalidArgument: Invalid Argument
(agiclass) root@autodl-container-5a7e46b0ba-9efc4c06:~/autodl-tmp/GLM-4/basic_demo# CUDA_VISIBLE_DEVICES=0 python openai_api_server.py
INFO 08-03 13:26:47 llm_engine.py:176] Initializing an LLM engine (v0.5.3.post1) with config: model='/root/autodl-tmp/glm-4-9b-chat', speculative_config=None, tokenizer='/root/autodl-tmp/glm-4-9b-chat', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, rope_scaling=None, rope_theta=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.bfloat16, max_seq_len=8192, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=True, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None), seed=0, served_model_name=/root/autodl-tmp/glm-4-9b-chat, use_v2_block_manager=False, enable_prefix_caching=False)
WARNING 08-03 13:26:47 tokenizer.py:129] Using a slow tokenizer. This might cause a significant slowdown. Consider using a fast tokenizer instead.
INFO 08-03 13:26:48 model_runner.py:680] Starting to load model /root/autodl-tmp/glm-4-9b-chat...
Loading safetensors checkpoint shards: 0% Completed | 0/10 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 10% Completed | 1/10 [00:00<00:02, 3.07it/s]
Loading safetensors checkpoint shards: 20% Completed | 2/10 [00:00<00:02, 2.73it/s]
Loading safetensors checkpoint shards: 30% Completed | 3/10 [00:01<00:02, 2.60it/s]
Loading safetensors checkpoint shards: 40% Completed | 4/10 [00:01<00:02, 2.55it/s]
Loading safetensors checkpoint shards: 50% Completed | 5/10 [00:01<00:01, 2.51it/s]
Loading safetensors checkpoint shards: 60% Completed | 6/10 [00:02<00:01, 2.50it/s]
Loading safetensors checkpoint shards: 70% Completed | 7/10 [00:02<00:01, 2.60it/s]
Loading safetensors checkpoint shards: 80% Completed | 8/10 [00:03<00:00, 2.60it/s]
Loading safetensors checkpoint shards: 90% Completed | 9/10 [00:03<00:00, 2.55it/s]
Loading safetensors checkpoint shards: 100% Completed | 10/10 [00:03<00:00, 2.51it/s]
Loading safetensors checkpoint shards: 100% Completed | 10/10 [00:03<00:00, 2.56it/s]
INFO 08-03 13:26:52 model_runner.py:692] Loading model weights took 17.5635 GB
INFO 08-03 13:26:53 gpu_executor.py:102] # GPU blocks: 2962, # CPU blocks: 6553
INFO: Started server process [2335]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
使用20G显存 # nvidia-smi Sat Aug 3 13:50:02 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.67 Driver Version: 550.67 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4090 On | 00000000:B1:00.0 Off | Off | | 31% 27C P8 30W / 450W | 20405MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| +-----------------------------------------------------------------------------------------+ # python openai_api_request.py ChatCompletion(id='chatcmpl-yGBEKQAw9qWAwd1R3BPhymc6njmxH', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='喵喵喵,我是人工智能助手,很高兴为您服务!有什么可以帮助您的吗?', role='assistant', function_call=None, tool_calls=None))], created=1722664484, model='glm-4', object='chat.completion', service_tier=None, system_fingerprint='fp_j98jzQ2E4', usage=CompletionUsage(completion_tokens=19, prompt_tokens=47, total_tokens=66))
from openai import OpenAI
base_url = "http://127.0.0.1:8000/v1/"
client = OpenAI(api_key="EMPTY", base_url=base_url)
def simple_chat(use_stream=False):
messages = [
{
"role": "system",
"content": "请在你输出的时候都带上“喵喵喵”三个字,放在开头。",
},
{
"role": "user",
"content": "你是谁"
}
]
response = client.chat.completions.create(
model="glm-4",
messages=messages,
stream=use_stream,
max_tokens=256,
temperature=0.4,
presence_penalty=1.2,
top_p=0.8,
)
if response:
if use_stream:
for chunk in response:
print(chunk)
else:
print(response)
else:
print("Error:", response.status_code)
if __name__ == "__main__":
# simple_chat(use_stream=False)
function_chat(use_stream=False)
|
|
对齐openai接口demo 
默认工具执行长度为8K
- 这是因为通常训练使用的显存是24G,对应8K,
- 如果有有更大的显存,比如48G,也可以配置16K
|

composite 英/ˈkɒmpəzɪt/ 美/kəmˈpɑːzət/ adj.复合的;合成的;混成的;混合成的 n.复合材料;混合物;合成物 https://github.com/THUDM/GLM-4/tree/main/composite_demo |

vllm推理停不下来,可能是因为stopid设置有误,可以按说明再设置一下 微调时要使用BF16,FP16有可能出现浮点数精度溢出的问题 
|
|
|
硬件配置

https://github.com/THUDM/GLM-4/blob/main/basic_demo/README.md
|
|
|
|
|
|
|
|
参考