AI记事·2024
|
TOP5职位 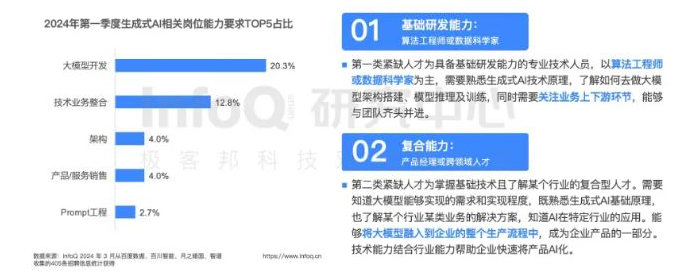
开发者的多元战场 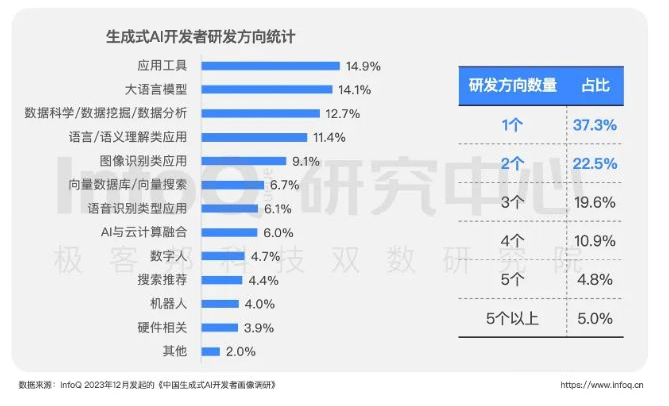
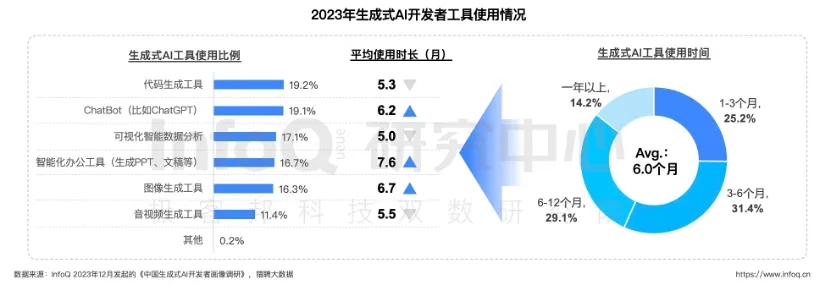
大模型使用占比
AI 研发团队的构建,是一门艺术。 目前,小而美的团队成为主流,他们灵活、高效,专注于应用层的创新。 团队成员不仅要懂得场景、开发,更要精通大模型。 而团队领导者,往往是拥有世界顶级名校背景和科技巨头企业经验的行业精英。 
|
特斯拉大裁员后的豪赌,FSD v12 是如何诞生的|TECH TUESDAY
https://mp.weixin.qq.com/s/KOE1aayXscZ4P6ozt8-8bQ
裁员 1 万多人、大幅缩减重要项目 4680 电池团队、负责三电系统的高级副总裁等高管离职……特斯拉 CEO 埃隆·马斯克在 4 月 15 日发起的大调整,只是一个序幕。
之后半个月,特斯拉持续裁撤曾经的重点项目:4680 电池项目继续裁员、北美的超级充电桩团队完全解散、9000 吨以上一体压铸机项目被叫停,相关高管大批离职。接下来的 6 月,特斯拉还会在加州和得州两地裁员超过 6000 人。
马斯克的新赌注是全自动驾驶。无人出租车(Robotaxi)项目被拔到最高优先级。马斯克宣布将在 8 月 8 日发布产品,今年投入百亿美元采购 GPU、研发车载芯片,用于改进自动驾驶系统。他曾多次说过,只要持续迭代这套系统,就会实现无人驾驶,让特斯拉成为 10 万亿美元市值公司。
在特斯拉的第二大市场中国,马斯克也期望用这套系统翻盘。4 月底,马斯克到访中国,被政府领导接见。不久后,他在内部信中说,特斯拉已在中国获得测试部分辅助驾驶系统的许可。
今年开始大面积推送的 FSD v12 自动驾驶系统确实展现出一些不同寻常的潜力。车主的反馈都很接近:“就像人开车一样”,跟上一代相比有进步,狭路会车、超车更从容。
100亿美元以上的投资 一家国内一线新能源企业负责人体验后相信,特斯拉的自动驾驶会有革命性突破。竞争对手们不敢错过,仅 4 月底北京车展前后,小鹏、华为、长城、商汤绝影等公司宣布将推出类似 FSD v12 的自动驾驶系统。同期,软银、英伟达和微软用 10.8 亿美元投资与特斯拉路线相同的英国自动驾驶公司 Wayve。 沿着特斯拉的路线,一场新的自动驾驶竞赛正在开启。这一次不只要解决技术难题,还是一场资源竞赛。来中国当天,马斯克在社交媒体上划出入局门槛:“任何公司,如果算力投入达不到百亿美元 ...... 就无法参与这一轮竞争。” 原理:砍掉 30 万行代码,让数据决定车怎么开
2000 年代,DARPA 在沙漠中举办的 3 场无人车挑战赛,是现代无人驾驶技术研发的源头。Google 招揽了优胜者,趟出一条可行的方案,将自动驾驶拆成多个环节:
用激光雷达、摄像头等传感器收集车辆周围环境数据,交给依赖人工标注数据训练出的模型,
识别出常见的重要目标和各种障碍物(感知模块),
再配合高精地图,让系统了解道路会怎么变化,
最后依赖工程师用代码写成的规则决定车怎么开(预测、规划模块)。
推出 v12 前,特斯拉的自动驾驶系统工作流程大概是:
负责感知的视觉模块先工作,处理摄像头等传感器捕捉的路况数据,识别出路上有什么东西,大概怎么分布,哪些是动的,哪些是不动的,哪些是车道线,可以行车的区域有哪些等等。
然后是预测规划控制模块,调用感知模型处理过的信息,预测场景中人、车等动态目标接下来几秒如何行动,结合模型和工程师提前写入的规则,规划安全的行驶路线,再控制方向盘、加速或刹车踏板,照路线行驶。
为了尽可能应对路上遇到的各种情况,特斯拉数百名工程师写了 30 万行 C++ 代码制定规则——相当于早期 Linux 操作系统代码量的 1.7 倍。
这不是人学会开车的方式,人不需要认出一条路上可能出现的大量物体到底是什么,也不需要为每个复杂场景提前制定各种规则,就能开车上路。
特斯拉 FSD v12 学开车更像人。最大的改变是用了 “端到端” 架构:一端输入摄像头等传感器获得的数据,另一端直接输出车该怎么开。
训练这套系统时,机器从大量车辆行驶视频和人类司机在不同环境下打方向盘、踩加速踏板的数据中学习怎么开车。
在 FSD v12 中,特斯拉工程师们写的规则几乎全被消灭,30 万行规则代码仅剩 2000 多行,不到原来的 1%。
端到端自动驾驶系统学开车的方式,也只是有一点像人,并没有系统能像人类一样真的理解世界。所以人学几天,就能开车上路安全驾驶,但 FSD 要看海量的视频学习。马斯克去年在一次财报会上谈到数据有多重要:“用 100 万个视频 case 训练,勉强够用;200 万个,稍好一些;300 万个,就会感到 Wow;到了 1000 万个,就变得难以置信了。”
基础:最难的几年依然坚持预装硬件、研发芯片、采集数据 2018 年初,特斯拉深陷产能危机、面临生死考验时,马斯克发邮件给 OpenAI 管理层,希望 OpenAI 并入特斯拉,共同研发 “基于大规模神经网络训练的全自动驾驶方案”。 他认为,AI 研发需要巨资,而 OpenAI 需要建立盈利模式才能与巨头抗衡。而特斯拉已经用 Model 3 和其供应链打造了火箭的 “第一级”,如果 OpenAI 能够并入特斯拉,将会加速无人驾驶研发,打造火箭的 “第二级”,特斯拉会因此卖出更多车,OpenAI 也会有足够的收入开展人工智能研究。 马斯克的提议被拒绝,最后退出 OpenAI 董事会。但在此之前,他就已经从 OpenAI 挖来安德烈·卡帕蒂(Andrej Karpathy),负责自动驾驶技术研发,带队训练效果更强的模型。 多位自动驾驶从业者认为,卡帕蒂加入特斯拉是其研发 v12 版端到端自动驾驶模型的开端。 1986 年出生的卡帕蒂,是过去十多年人工智能浪潮的亲历者,也是从中成长起来的人工智能科学家。 他 2011 在斯坦福大学读博士期间和导师李飞飞一起完善催生 AlexNet 的 ImageNet 竞赛数据集, 在各个学术会议上发表数篇计算机视觉论文,在斯坦福大学开设了第一门深度学习课。 博士毕业后,他是最早一批加入 OpenAI 的人。 2017 年 11 月,卡帕蒂发布著名的《软件 2.0》 文章,称 “软件吞噬世界,而人工智能为基础的软件 2.0 正在吞噬软件”。那时经过大量数据训练的计算机视觉模型,识别物体的准确率超过人眼。AlphaGo 从数据中学到了击败人类围棋冠军的方法。 他相信,靠着大量数据,人工智能在大部分有价值的垂直领域,“至少在涉及图像 / 视频和声音 / 语音的领域,比你我能想出的任何代码都要好。” 在卡帕蒂到来前,特斯拉已经完成了自动驾驶的数据基建。 用大量数据训练更强的模型,是非常适合特斯拉的技术发展路线。 用大量数据训练更强的模型,是非常适合特斯拉的技术发展路线。 但特斯拉要投入大量资源研发自动驾驶技术,马斯克从不缺乏冒险的决心。 2016 年开始,每一辆出厂的特斯拉汽车都搭载能运行 Autopilot 辅助驾驶系统的硬件, 花钱买了软件才能开启功能。 到现在也没几个汽车品牌会这么做,更常见的做法是把同一款车分成不同的版本, 把搭载自动驾驶硬件车型卖给感兴趣的客户。 标配辅助驾驶的时候,特斯拉启用 “影子模式”(Shadow Mode), 就算驾驶员不购买 Autopilot 功能, 这套系统也会在后台运行,记录行车数据、规划行车路线。 马斯克当时接受采访说,它的作用是证明系统比人可靠,为监管机构批准技术提供数据支撑。 卡帕蒂加入后,影子模式成为特斯拉获得训练模型数据的核心来源—— 当系统选择的路线与驾驶员的选择有明显偏差时,就会触发数据回传机制, 系统会自动记录摄像头捕捉到的数据、车辆行驶数据等,等到连接 WiFi 后上传到特斯拉的服务器中。 到 2018 年底,特斯拉就靠这套系统采集 16 亿公里数据,超过现在绝大多数研发自动驾驶技术的车企。 特斯拉的自动驾驶团队把大部分精力放到数据上,搭建了一套数据处理系统,专门分析、筛选收集到的数据,一开始用人、后来绝大部分数据用机器打标签,然后喂给模型,持续改进自动驾驶系统。为了用大量数据训练模型,特斯拉在 2019 年之前,就采购大量 GPU 建设名为 Dojo 的算力中心,并持续扩大,到现在已经积累了等同 3.5 万张 H100 的算力。 摄像头替换激光雷达,并加入高度维度,实现3D识别 HydraNet 用微软亚洲研究院 2015 年发布的 ResNet 模型当主干,提取车身周边 8 个摄像头所捕捉画面的通用特征,交给不同的算法分支完成不同的任务。这么做可以避免用不同的模型重复从相同的画面提取特征,节省算力。 这是当时学术界和多数开发大型计算机识别系统公司的选择,特斯拉把它做得规模更大,并实现工程化。但这么做有局限。HydraNet 只能从不同角度的摄像头捕捉的画面中各自提取信息,摄像头可能只会捕捉到周边物体的一部分。就像新手司机很难靠后视镜流畅倒车入库一样,自动驾驶系统也很难靠它实现真正的无人驾驶,还得靠各种雷达、高精地图辅助。 不用激光雷达的卡帕蒂团队选择使用一系列算法,将 8 个不同方向的摄像头收集的画面拼成一个 360° 的鸟瞰图(Bird's Eye View,即 BEV)模式,再让模型 “理解世界”,规划行车路线。但想让这套系统效果良好,得尽量保证地面是平的,而且车周围环境要简单,否则系统就难以准确理解不同摄像头看到的图片之间有什么关联。 “当我们用它实现 FSD 时,很快发现达不到预想中的效果。” 安德烈·卡帕蒂在 2021 年特斯拉 AI Day 上说,他介绍了用 Transformer 架构开发的新版模型,能准确地把跨越多个相机的目标拼得更准确、稳定。 而且利用 Transformer 架构做成的模型,输出的信息可以直接用到后续的预测规划模块,也为 FSD v12 做成端到端模型打下基础。 与新模型配合,卡帕蒂还分享了一个名叫 “Spatial RNN” 的架构,用视频训练模型时,模型能获得短暂的 “记忆” 能力,理解周围的场景如何随着时间变化,从而具备脑补摄像头视野盲区、实时构建局部地图的能力。 这次技术迭代,让特斯拉的辅助驾驶系统不用高精地图也能把车开好,再一次推高自动驾驶的能力上限,向人眼靠近。 等到 2022 年特斯拉 AI Day 举办时,卡帕蒂已经离开特斯拉。特斯拉的自动驾驶系统继续迭代,继任者阿肖克·埃卢斯瓦米(Ashok Elluswamy)介绍了 “占用网络”(Occupancy Network),在 Transformer 架构基础上引入 “高度” 要素,能把不同角度摄像头捕捉到的画面还原成 3D 场景,计算出一个物体在空间中占用多少点,从而推断出它的形状。 借助 Occupancy Network,特斯拉的自动驾驶系统不用激光雷达,只靠摄像头收集信息,就可以识别出它没有见过的障碍物,被视为 “纯视觉方案” 的胜利。 特斯拉多年研发,终于实现马斯克多年前提出的第一个要求:人靠双眼就可以识别、还原 3D 环境,车靠摄像头也应该可以。 然而,尽管多名重要的技术高管选择离职,但OpenAI 的业务仍在继续增长。 据报道,OpenAI在2023年的年度经常性收入(ARR)已达到20亿美元,同比增长超过4500%,使OpenAI跻身包括谷歌和 Meta 在内的少数硅谷公司之列,即在成立后的10年内实现超10亿美元收入。 目前,OpenAI公司估值超过800亿美元。 就在北京时间2月14日凌晨,OpenAI宣布,本周将面向一小批 ChatGPT 免费版的用户和Plus付费版用户测试一项关于“记忆算法”的新功能——在与 ChatGPT 聊天时,用户可以要求它记住特定的内容,或是让它自行获取详细信息,用得越多,ChatGPT的记忆力就会越好。 OpenAI 表示,他们将很快公布向更大众群体用户推出上述新功能的计划。最初将有数以万计的用户“尝鲜”该功能,而团队希望先得到首批用户的使用反馈,并进行技术改进。 |
AI教母李飞飞创业首秀,“空间智能”需要哪些能力 https://mp.weixin.qq.com/s/UuuJw-aMW9Stk7DXQKsEwg 目的在于让AI理解三维物理规律... 被称为数智领域内的革命 让机器向人靠拢,机器研发方向... - 5G+传感器+AI自动化,这个AI更加追求可解释性,更多的是基于规则... - 优点:精准,不会产生幻觉 - 缺点:投入高 - 所有空间数据来自于传感器 - 训练+自学习 - 部分空间数据由推理得到,不全来自于传感器 数智时代,获取温度,土壤,温度等信息 - 植入温度,湿度传感器 - 观察地表的颜色,潮湿与干涸的地表颜色是不一样的,这是靠经验与推理 效率,成本,可靠性,稳定性,容错能力 李飞飞对“空间智能”的描述,是从物体之间的关系中获得预测和洞察力的能力, 涉及的算法能合理推断出图像和文字在三维环境中的样子,并根据这些预测采取行动。 而人工智能对“空间智能”理解的进步,正在催化机器人学习, 让我们更接近一个人工智能不仅可以看到、创造,还与周围的物理世界互动的世界。 为了帮助观众理解“空间智能”,李飞飞在演讲中展示了一张“猫咪伸出爪子试图把玻璃杯推向桌子边缘”的照片。 她解释,人类大脑在瞬间可以评估玻璃杯的几何形状, 在三维世界的位置,与桌子、猫咪和其他物体的关系,并预测接下来会发生什么,采取行动制止。 在“空间智能”的驱动下,大自然创造了视觉与行为的良性循环。 李飞飞的团队教计算机如何在三维世界中行动,如利用大型语言模型让机械臂执行任务, 根据口头指令开门和制作三明治,这就是“空间智能”。 空间计算——空间智能的底座:点云 空间智能的目标不是抽象出对场景的理解,而是不断捕捉正确的信息,并正确地表示信息, 以实现实时解释和行动。空间智能考验的是多领域软硬件的综合能力。 空间计算是使人类能够在三维空间与计算机交互的一组技术, 包括三维重建、空间感知、用户感知、空间数据管理等所有使人类、 虚拟生物或机器人在真实或虚拟世界中移动的软、硬件技术, 侧重对现实世界的三维空间信息的获取、处理、分析和理解。 空间计算硬件功能的提升,能带来更为身临其境和交互式的数字体验。 空间计算的基础是设备能使用实时3D渲染在三维空间生成虚拟对象, 通过摄像头计算机视觉或激光雷达技术,实时扫描周围环境, 计算它们在空间中的位置,空间跟踪生成唯一参考点的 点云, 通过控制器输入、手部跟踪输入和眼动跟踪输入等,实现数字内容的沉浸式自然交互。 2024年英伟达GTC开发者大会的炉边谈话中,李飞飞提到: “用大数据进行扩展时,我想看到的是结构化建模,或着说偏向于三维感知和结构的模型与大数据相结合”。 建模世界物体存在局限性,“空间智能”需要基于世界数据、多模态数据的人工智能模型架构, 应对复杂多变的物体识别、场景感知等挑战。 模型需要大量高质量标注数据进行训练,对各种噪声、遮挡等情况保持鲁棒避免误识别, 进行图像、文本等多模态学习等。 帝国理工学院计算机系机器人视觉教授安德鲁J·戴维森在论文中提到, 空间智能通过训练一个RNN(递归神经网络)或类似网络, 从实时输入的数据中顺序产生有用输出, 要求它在其内部状态内捕获一组持续的概念,这些概念必须与周围环境的形状和质量密切相关。 空间智能高效的关键,在于所需算法中识别计算和数据移动的图数据结构, 并尽可能地利用或设计具有相同属性的处理硬件,尽量减少架构周围的数据移动。 空间智能要走增量式进化路线,需要在AI设计中增加自由度。 未来空间智能系统设计需要考虑六个方面。 第一,需要包含一个或多个摄像头及辅助传感器, 与嵌入式移动实体(如机器人或增强现实系统)中的小型低功耗封装的处理架构紧密集成。 第二,实时系统需使用几何和语义信息维护和更新世界模型, 并根据板载传感器测量估算其在模型中的位置。 第三,理想状态下,系统要为环境中所有对象的身份、位置、形状和运动提供完整的语义模型。 第四,模型的表示要接近度量标准,以便快速推理预测系统感兴趣的内容。 第五,专注保留几何和语义的最高质量,即当前观察到的场景及近期交互, 其余部分存储在低质量级别的层次结构,在重新访问时快速升级。 第六,每个输入的视觉数据会自动根据预测场景进行跟踪检查,及时响应其环境变化。 |
|
|
|
|
AI记事
2012:深度学习时代的小分水领 2012年AlexNet通过ImageNet比赛大放光彩,同时也开启了GPU时代; 此时,AlexNet的作者,已在这条路上走了50年了,熬过了至少两个人工智能的寒冰时代。 2014 Jupyter Notebook源于2014年的ipython项目,是一个非盈利的开源项目,旨在开发跨几十种编程语言的开源软件、开放标准和用于交互式计算的服务。它是一款程序员和科学工作者的编程、文档、笔记、展示软件,因为兼容多种编程语言,具有共享笔记、交互式输出、大数据整合的特点而被广泛使用。 2015:深度学习时代的中分水领 resnet论文解决了深度学习多层网络梯度消失的问题,从而让网络的层次从个位数达到上千,大大增强了神经网络的能力 同年,注意力机制论文现世,transformer诞生,这为大模型的出现埋下的伏笔 TensorFlow,由Google在2015年11月9日发布的,其旨在提供一套完整的机器学习和深度学习框架,支持多种编程语言,包括Python、C++、Go、Java等 2016 PyTorch的前身是Torch,其底层和设计理念追求最少的封装,让用户尽可能地专注于实现自己的想法。PyTorch的初始版本于2016年9月由Adam Paszke、Sam Gross、Soumith Chintala等人创建,并于2017年在GitHub上开源 2017 2017年11月前后,谷歌的AutoML项目发展出新的神经网络拓扑结构,创建了NASNet,这是一个针对ImageNet和COCO优化的系统。 据Google称,NASNet的性能超过了以前发布的所有ImageNet性能。 [1]
参考