机器学习训练器
|
AI开发与传统开发
传统开发:需求分析,设计开发,测试 --- bug ,修订bug -- 上线
AI开发
- 先设定一个baseline,
- 大概率这个baseline存在很多可优化的地方,但这不叫bug
- 做一些优化,数据方向的,模型方向的,可以让模型的效果更好
- AI开发的对与错没有传统开发类似bug这样清晰的错误的界定
- 而是一个由效果由坏到好的过程,直到很难再提升为止
训练器示例 from sklearn.svm import SVC,SVR model = SVR()
from tpf import MlTrain
MlTrain.train(X_train, y_train, X_test, y_test,
model,
save_path="fangjia_SVR.pkl",
epoch=300000,
loss_break=0.1)
模型加载验证
from tpf import pkl_load,pkl_save
model,loss=pkl_load(file_path=save_path)
y_pred_dtr = model.predict(X_test)
((y_pred_dtr - y_test)**2).mean()
|
from tpf.datasets import load_boston X_train, y_train, X_test, y_test = load_boston(split=True,test_size=0.15, reload=False) X_train.shape,y_train.shape, X_test.shape, y_test.shape from sklearn.tree import DecisionTreeRegressor dtr = DecisionTreeRegressor() dtr.fit(X_train,y_train) feature=dtr.feature_importances_ import numpy as np a=np.argsort(feature)[::-1] X_train = X_train[a][:6] y_train = y_train[a][:6] X_test = X_test[a][:6] y_test = y_test[a][:6] save_path="fangjia_DecisionTreeRegressor.pkl" from sklearn.tree import DecisionTreeRegressor model = DecisionTreeRegressor()
from tpf import MlTrain
MlTrain.train(X_train, y_train, X_test, y_test,
model,save_path=save_path,epoch=1000)
loss_start: 2.994999999999996
from tpf import pkl_load,pkl_save model,loss=pkl_load(file_path=save_path) y_pred_dtr = model.predict(X_test) ((y_pred_dtr - y_test)**2).mean() |
深度学习训练器
|
数据集:100个特征列,2类标签 from yinum import get_train,get_test from yinum import DLModel from yinum import T import torch
model = DLModel(in_features=100, out_features=2)
参数以ml_开头,方便查看
T.train(model,
loss_fn=torch.nn.CrossEntropyLoss(),
optimizer='sgd',
train_dataset_func=get_train,
test_dataset_func=get_test,
train_dataset=None,
test_dataset=None,
train_dataloader=None,
epochs=3000,
learning_rate=0.001,
model_param_path='ml_model1_params.h5',
auto_save=True,
continuation=True,
is_regression=False,
log_file='/tmp/train.log',)
T.show_img(mean_num=100) T.show_img_loss(mean_num=100) |
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
from tpf import T
from sklearn.datasets import make_classification
# torch 批次处理
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from sklearn.datasets import make_regression
class MyDataSet(Dataset):
def __init__(self,X,y):
"""
构建数据集
"""
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
x = self.X[idx]
y = self.y[idx]
return torch.tensor(data=x).float(), torch.tensor(data=y).long()
from tpf import pkl_load,pkl_save
import os
save_path = "datset1.pkl"
if os.path.exists(save_path):
X_1,y_1 = pkl_load( file_path=save_path, use_joblib=False)
else:
X_1,y_1 = make_classification(n_samples=100000,n_features=100,n_classes=2,)
pkl_save((X_1,y_1), file_path=save_path, use_joblib=False)
def get_train():
train_index = np.random.randint(low=0,high=100000,size=1000)
_X = X_1[train_index]
_y = y_1[train_index]
return MyDataSet(_X,_y)
def get_test():
test_index = np.random.randint(low=0,high=100000,size=200)
_X = X_1[test_index]
_y = y_1[test_index]
return MyDataSet(_X,_y)
这里先生成一份数据保存,后续每次加载的是相同的数据
取的时候,是随机取,对应现实数据集不全的场景
- 将取数据的方式以方法封装
- 每次调用方法,生成的数据集是不一样的
- 但都是全体数据集中的一部分
|
class DLModel(nn.Module):
"""模型定义
"""
def __init__(self, in_features, out_features):
"""参数网络设计
- 总体来说,做的事件是将数据从一个维度转换到另外一个维度
"""
super(DLModel, self).__init__()
self.linear = nn.Linear(in_features=in_features, out_features=out_features)
def forward(self, X):
"""正向传播
- 调用定义的参数网络
- 让数据流过参数网络,常量数据流过不过的参数产生不同的值
- 这个过程参数本身不会变
- 让参数变化的是后面的优化器
"""
out = self.linear(X)
return out
model = DLModel(in_features=100, out_features=2) loss_fn = torch.nn.CrossEntropyLoss() |
T.train(model,
loss_fn,
optimizer='sgd',
train_dataset_func=get_train,
test_dataset_func=get_test,
train_dataset=None,
test_dataset=None,
train_dataloader=None,
epochs=500,
learning_rate=0.001,
model_param_path='ml_model1_params.h5',
auto_save=True,
continuation=True,
is_regression=False,
log_file='/tmp/train.log',)
model_param_path='ml_model1_params.h5'
- 文件路径参数,默认当前文件所在目录
- 默认以ml_为开头,这样生成的文件在查看时,能显示在一块
|
T.show_img(mean_num=2) mean_num=2 - 如果轮次太多,图形会显得很密集 - mean_num取指定长度的数据取均值 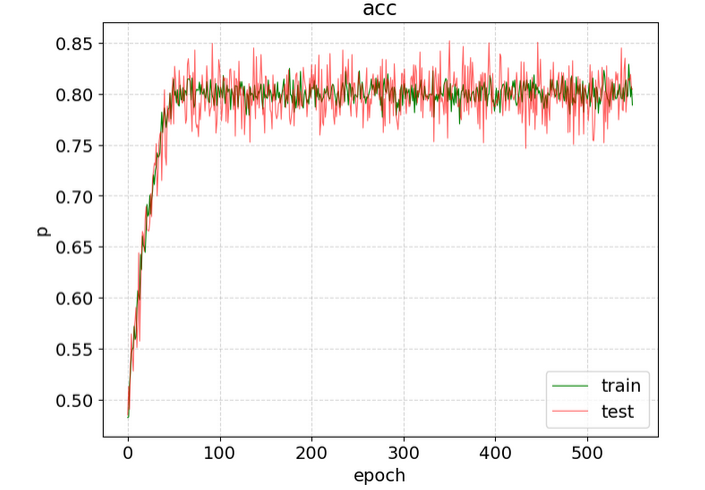
每20个长度的数据取平均,图形会显得平滑易观 # 数据还是存在文件中的那份数据,只是显示的时候,以不同的方式显示 T.show_img(mean_num=20) 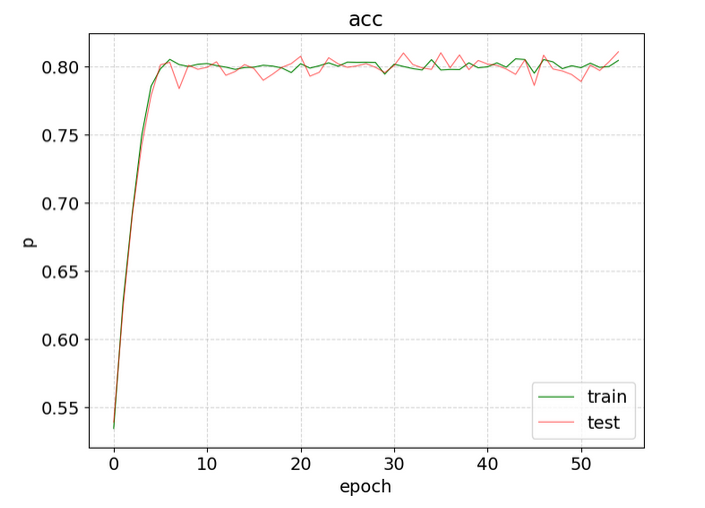
T.show_img_loss(mean_num=10)
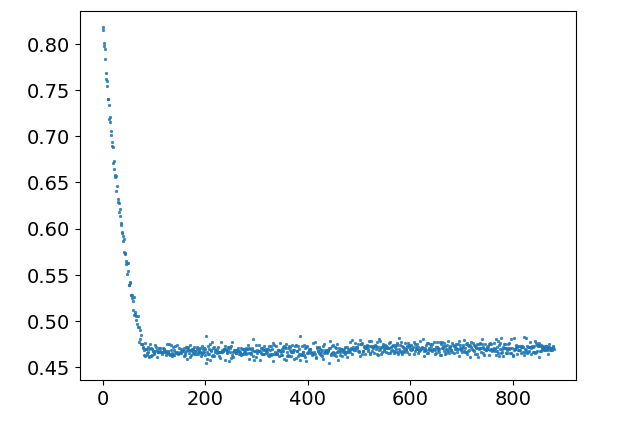
T.show_img_test()
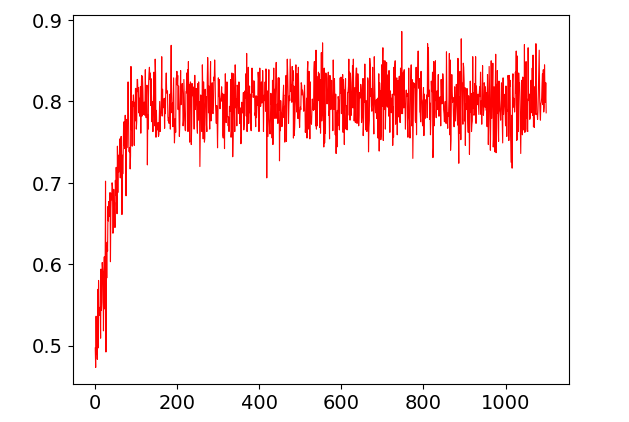
T.show_img_train()
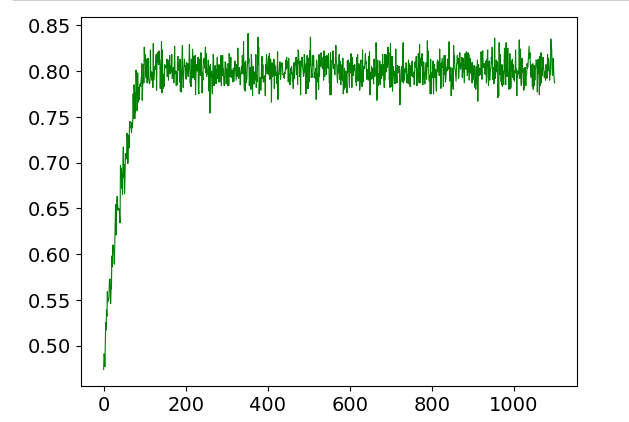
|
#### 精度不再变化
- 反复检查,代码没有错误
- 训练集与测试集没有找乱,同一批次的数据,即相同的数据,得到的结果相同
- 因此预测精度不变了
- 根本原因是,针对一条固定的数据,模型预测的很稳定,就是一个稳定的结果
- 每条数据是这样,那么整体的结果也不会变
- 出现这种情况的几种可能
- 代码错误,也是最大的可能
- 数据集简单,数据不多;或者数据很多,每你每次用的很少;并且总用固定的一部分
- 如果一切都OK,数据集也够,那就是模型简单,或者说训练到了再也不会变化的地步了
- 反观本例,是模型太简单了,就是一个全连接
本次出现预测分数固定的原因是: - 取了相对固定的一部分数据集 - 模型也简单,训练也充分了,对于相对固定的数据集出现了固定的结果 解决方案: - 已经制定了随机取数据集的方法 - 每放在的轮次for循环的外面,将之移入for循环中就好了 |
|
振荡的训练结果
昨天训练的精度在90%左右,
今天开始之后一直在80%左右,怎么都不会升了
- 加大训练次数,基本没有变化
删除所有记录结果,让参数重新初始化
- 很快精度就又恢复到了90%左右
参数随机初始化后,优化前进的方向有很多个
- 随机选择一个
- 有些方向能走的远
- 有些方向注定不会走太远
总结
可尝试多从开始训练几次
注意将训练的结果保存移走,防止被覆盖
|
模型保存
保存: def pkl_save(data, file_path, use_joblib=False, compress=0)
from tpf import pkl_load,pkl_save
pkl_save((model,loss),file_path=save_path, use_joblib=True)
pickle与joblib区别并不大, 只是深度学习模型转onnx时,只认joblib,所以模型保存就倾向于joblib吧 joblib - 可保存一切python对象,当然也包括 模型 - 对象序列化后写入文件 - 读取文件序列,反序列化转为对象
加载
from tpf import pkl_load,pkl_save model,loss=pkl_load(file_path=save_path, use_joblib=True) y_pred_dtr = model.predict(X_test) ((y_pred_dtr - y_test)**2).mean()
训练结果不一样
最大的可能是每次训练及预测的数据集不一样
数据集理论上要包含要学习的所有规律,是一个范围内规则的全集
但实际上,用到的数据集很难包括一个业务的所有规则
都是包括了一部分,大量的重复数据
学到的不一样,预测的也就有差异
当数据量足够大,大到包含了所有要学的规则时,
随意取一部分数据集都会包含所有要学的规则,
就算训练集不一样,相同的预测集结果也会非常接近
也有可能是在取数据集时,每次都是打乱了重新取 顺序不同,结果也有可能不同;关于顺序,也得看用的算法是不是与顺序无关
在深度学习中,模型参数是随机初始化的,
在不同的训练轮次中,结果不一样,
深度学习是随机一个起点,然后向最优解靠拢,
也有可能最优解有多少,靠拢到的最解角不同
参考