常用方法
在机器学习和数据科学中,特征工程是一个非常重要的步骤,
它涉及到从原始数据中创建新的特征,
以期望这些新特征能够更好地帮助模型进行预测或分类。
当生成了多个特征变量后,
探索这些特征之间的组合以找到可能提高模型性能的新特征是一个常见的做法。
虽然没有一个直接的“算法”可以自动确定哪些特征组合将产生最佳效果,
但有一些方法和工具可以帮助你进行这种探索:
特征交叉(Feature Crosses) 在机器学习中,特征交叉是一种通过将两个或多个特征相乘(或进行其他形式的组合) 来创建新特征的技术。 这在推荐系统、广告点击率预测等领域特别有用。 在TensorFlow和scikit-learn等库中,可以通过手动编码或使用库提供的工具来实现特征交叉。 多项式特征(Polynomial Features)
scikit-learn中的PolynomialFeatures类可以用来生成多项式特征,
这实际上是特征交叉的一种形式,
但它可以自动地为所有特征生成所有可能的多项式组合(直到指定的度数)。
网格搜索(Grid Search)和随机搜索(Randomized Search)
虽然这些技术主要用于超参数调优,
但它们也可以用来评估不同特征组合的效果。
你可以定义一个包含不同特征组合的“超参数”空间,并使用这些搜索技术来找到最佳组合。
递归特征消除(Recursive Feature Elimination, RFE) 虽然RFE主要用于特征选择,但它也可以间接地帮助识别哪些特征组合可能更有用。 通过逐步排除特征并观察模型性能的变化, 你可以了解哪些特征或特征组合对模型性能贡献最大。 特征重要性评估
在训练完模型后,评估各个特征的重要性(例如,在决策树、随机森林等模型中),
这可以帮助你理解哪些特征或特征组合对模型预测最有帮助。
自动化机器学习(AutoML)工具
一些自动化机器学习工具(如Auto-sklearn、TPOT等)可以自动进行特征工程、模型选择和超参数调优。
这些工具可能会尝试不同的特征组合,并基于交叉验证的结果来选择最佳模型。
自定义脚本和迭代
最后,编写自定义脚本来尝试不同的特征组合,
并基于模型性能来迭代改进,是一个灵活且强大的方法。
这可能需要一些试错和领域知识,但通常能够找到最适合你具体问题的特征组合。
综上所述,虽然没有一个直接的“算法”可以自动找到最佳的特征组合,
但你可以使用上述方法和工具来指导你的特征工程过程,
并找到可能提高模型性能的新特征。
|
在scikit-learn库中,并没有直接命名为“验证特征交叉”的特定算法。 然而,scikit-learn提供了多种工具和方法,这些可以用于实现和评估特征交叉的效果。 以下是一些与特征交叉相关的方法和步骤: 手动实现特征交叉: 最直接的方法是手动编写代码来创建特征交叉。这通常涉及到将两个或多个特征相乘、相加、相除或应用其他数学运算来生成新的特征。然后,这些新特征可以被添加到模型中,以评估它们对模型性能的影响。 使用PolynomialFeatures: PolynomialFeatures是scikit-learn中的一个类, 它可以用于生成多项式特征,这实际上是一种形式的特征交叉。 通过设置degree参数,你可以指定要生成的多项式的最高次数, 从而生成包括原始特征及其交叉在内的多项式特征。 自动化机器学习(AutoML)工具: 虽然scikit-learn本身不提供完整的AutoML解决方案, 但有一些基于scikit-learn的AutoML库(如Auto-sklearn、TPOT等) 可以自动进行特征工程、模型选择和超参数调优。 这些工具可能会尝试不同的特征组合(包括特征交叉), 并基于交叉验证的结果来选择最佳模型。 然而,需要注意的是,这些AutoML工具通常具有更高的计算成本, 并且可能需要较长的时间来找到最佳解决方案。 网格搜索(Grid Search)和随机搜索(Randomized Search): 虽然这些技术主要用于超参数调优,但它们也可以用来评估不同特征组合(包括特征交叉)的效果。 你可以定义一个包含不同特征组合的“超参数”空间,并使用这些搜索技术来找到最佳组合。 然而,这通常涉及到大量的计算和尝试,因此可能不适用于大型数据集或复杂模型。
模型的特征重要性评估:
在训练完模型后,你可以评估各个特征(包括通过特征交叉生成的新特征)的重要性。
这可以通过查看模型的系数、使用特征重要性分数(如随机森林中的feature_importances_)或
进行置换测试等方法来实现。
特征重要性的评估可以帮助你了解哪些特征或特征组合对模型预测最有帮助。
自定义脚本和迭代:
编写自定义脚本来尝试不同的特征交叉方法,并基于模型性能来迭代改进是一个灵活且强大的方法。
这可以涉及到使用循环、条件语句和scikit-learn的API来动态地创建和评估特征交叉。
总结来说,scikit-learn没有直接的“验证特征交叉”的算法,
但你可以通过手动实现、使用PolynomialFeatures、网格搜索/随机搜索、评估特征重要性、
使用AutoML工具或编写自定义脚本来实现和评估特征交叉的效果。
|
|
|
|
|
|
|
PolynomialFeatures
from sklearn.datasets import load_iris from sklearn.preprocessing import PolynomialFeatures from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 查看数据形状
print("Original data shape:", X.shape)
#Original data shape: (150, 4)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 初始化多项式特征生成器,设置degree为2
poly = PolynomialFeatures(degree=2)
# 转换特征
X_poly = poly.fit_transform(X)
# 查看转换后数据的形状
print("Transformed data shape:", X_poly.shape)
Transformed data shape: (150, 15)
X[0]
array([5.1, 3.5, 1.4, 0.2])
X_poly[0]
array([ 1. , 5.1 , 3.5 , 1.4 , 0.2 , 26.01, 17.85, 7.14, 1.02,
12.25, 4.9 , 0.7 , 1.96, 0.28, 0.04])
# 划分数据集 X_train, X_test, y_train, y_test = train_test_split(X_poly, y, test_size=0.3, random_state=42) # 初始化决策树分类器 clf = DecisionTreeClassifier() # 训练模型 clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Accuracy: 1.00
|
polynomial 英/ˌpɒli'nəʊmiəl/ 美/ˌpɑli'noʊmiəl/ adj. 多项式的;多词学名的 from sklearn.preprocessing import PolynomialFeatures # 初始化多项式特征生成器,设置degree为2 poly = PolynomialFeatures(degree=2) Generate a new feature matrix consisting of all polynomial combinations of the features with degree less than or equal to the specified degree. For example, if an input sample is two dimensional and of the form [a, b], the degree-2 polynomial features are [1, a, b, a^2, ab, b^2].
degree : int or tuple (min_degree, max_degree), default=2
If a single int is given, it specifies the maximal degree of thepolynomial features.
If a tuple `(min_degree, max_degree)` is passed,
then `min_degree` is the minimum and `max_degree` is the maximum
polynomial degree of the generated features.
Note that `min_degree=0`
and `min_degree=1` are equivalent as outputting the degree zero term is
determined by `include_bias`.
interaction_only : bool, default=False
If `True`, only interaction features are produced: features that are
products of at most `degree` *distinct* input features, i.e. terms with
power of 2 or higher of the same input feature are excluded:
- included: `x[0]`, `x[1]`, `x[0] * x[1]`, etc.
- excluded: `x[0] ** 2`, `x[0] ** 2 * x[1]`, etc.
include_bias : bool, default=True
If `True` (default), then include a bias column, the feature in which
all polynomial powers are zero (i.e. a column of ones - acts as an
intercept term in a linear model).
order : {'C', 'F'}, default='C'
Order of output array in the dense case. `'F'` order is faster to
compute, but may slow down subsequent estimators.
|
|
组合之前 iris.feature_names ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] 按之前的iris数据集例子,原特征重要性 clf.n_features_in_ 4 clf.feature_importances_ array([0.01911002, 0. , 0.89326355, 0.08762643]) clf.n_classes_ 3 组合之后
clf.n_features_in_
15
clf.feature_importances_
array([0. , 0.01911002, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.03276003, 0. , 0.00546001, 0.94266994, 0. ])


|
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建Pipeline
poly_features = PolynomialFeatures(degree=2, include_bias=False)
scaler = StandardScaler()
lgbm = LGBMClassifier(random_state=42,max_depth=3,num_leaves=4)
pipeline = make_pipeline(poly_features, scaler, lgbm)
# 训练模型
pipeline.fit(X_train, y_train)
# 预测测试集
y_pred = pipeline.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
[LightGBM] [Info] Number of positive: 286, number of negative: 169 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.005022 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 75319 [LightGBM] [Info] Number of data points in the train set: 455, number of used features: 495 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.628571 -> initscore=0.526093 [LightGBM] [Info] Start training from score 0.526093 Accuracy: 0.97 不使用PolynomialFeatures,lightgbm的准确率也是0.97 大概率数据的上限是0.97 |
|
|
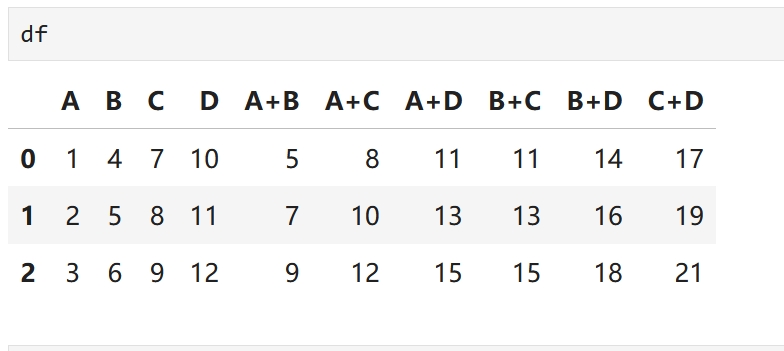
加法组合
import pandas as pd
from itertools import combinations
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9], 'D': [10, 11, 12]}
df = pd.DataFrame(data)
# 获取所有列的名称
columns = df.columns
# 生成所有可能的列对(不包括自身组合)
column_pairs = list(combinations(columns, 2))
# 遍历列对,计算每对列的和,并将新列添加到DataFrame中
for pair in column_pairs:
new_col_name = f"{pair[0]}+{pair[1]}"
df[new_col_name] = df[pair[0]] + df[pair[1]]
|
import pandas as pd
from itertools import combinations
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9], 'D': [10, 11, 12]}
df = pd.DataFrame(data)
# 获取所有列的名称
columns = df.columns
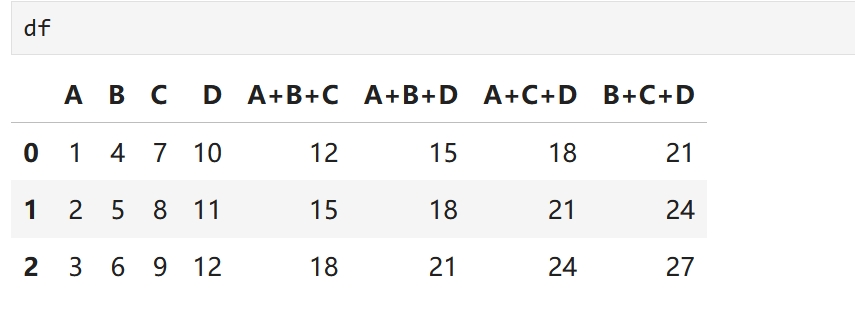
# 生成所有可能的列对(不包括自身组合)
column_pairs = list(combinations(columns, 3))
# 遍历列对,计算每对列的和,并将新列添加到DataFrame中
for pair in column_pairs:
new_col_name = f"{pair[0]}+{pair[1]}+{pair[2]}"
df[new_col_name] = df[pair[0]] + df[pair[1]]+ df[pair[2]]
|
import pandas as pd
from itertools import combinations
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9], 'D': [10, 11, 12]}
df = pd.DataFrame(data)
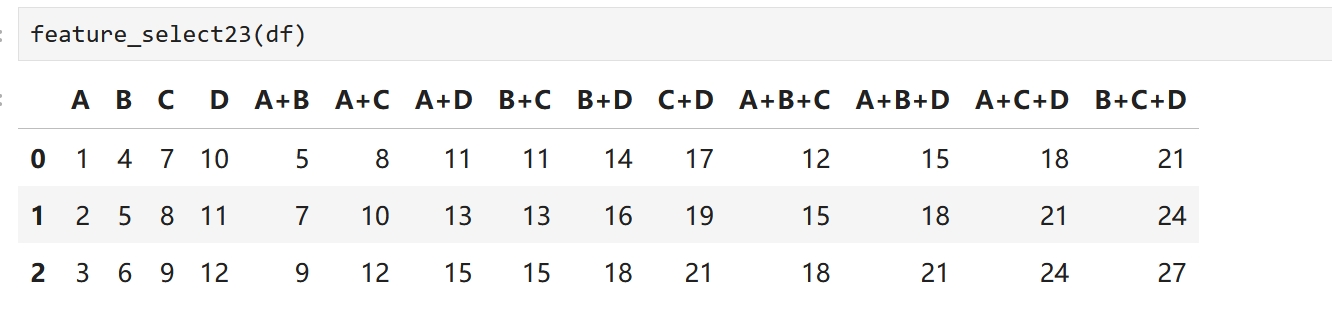
def feature_select23(df):
"""将pandas中的数表两两组合,三三组合"""
# 获取所有列的名称
columns = df.columns
# 生成所有可能的列对(不包括自身组合)
column_pair2 = list(combinations(columns, 2))
# 遍历列对,计算每对列的和,并将新列添加到DataFrame中
for pair in column_pair2:
new_col_name = f"{pair[0]}+{pair[1]}"
df[new_col_name] = df[pair[0]] + df[pair[1]]
# 生成所有可能的列对(不包括自身组合)
column_pair3 = list(combinations(columns, 3))
# 遍历列对,计算每对列的和,并将新列添加到DataFrame中
for pair in column_pair3:
new_col_name = f"{pair[0]}+{pair[1]}+{pair[2]}"
df[new_col_name] = df[pair[0]] + df[pair[1]]+ df[pair[2]]
return df
|
|
|
|
|
featuretools
|
擅长处理 多表关联 的特征组合
Featuretools 是一个强大的开源 Python 库,
用于自动化地从关系型数据(如数据库表或Pandas DataFrame)中生成特征。
它基于深度特征合成(Deep Feature Synthesis, DFS)的概念,
通过递归地应用特征基元(如求和、平均值、最大值、最小值、计数等)来构建新的特征。
Featuretools 非常适合于机器学习中的特征工程阶段,
特别是当数据集包含多个相关表且需要快速生成大量特征时。
Featuretools 的原理
Featuretools 的核心在于定义实体(Entity)和关系(Relationship),
然后利用这些定义来自动构建特征。
实体(Entity):代表数据集中的一张表,包含行(观测值)和列(特征)。
关系(Relationship):定义不同实体之间的连接,通常是基于外键的。
Featuretools 通过以下步骤生成特征:
定义实体和关系:
首先,你需要定义数据中的实体以及它们之间的关系。
应用特征基元:
Featuretools 使用预定义的特征基元(如求和、平均值等)来生成新特征。
这些基元可以递归地应用于现有特征和关系。
深度特征合成:
通过递归地应用特征基元和关系,Featuretools 能够生成复杂的特征,
这些特征可能跨越多个表。
|
import pandas as pd
import warnings
warnings.filterwarnings("ignore", message="Could not infer format")
warnings.filterwarnings("ignore", message="The provided callable")
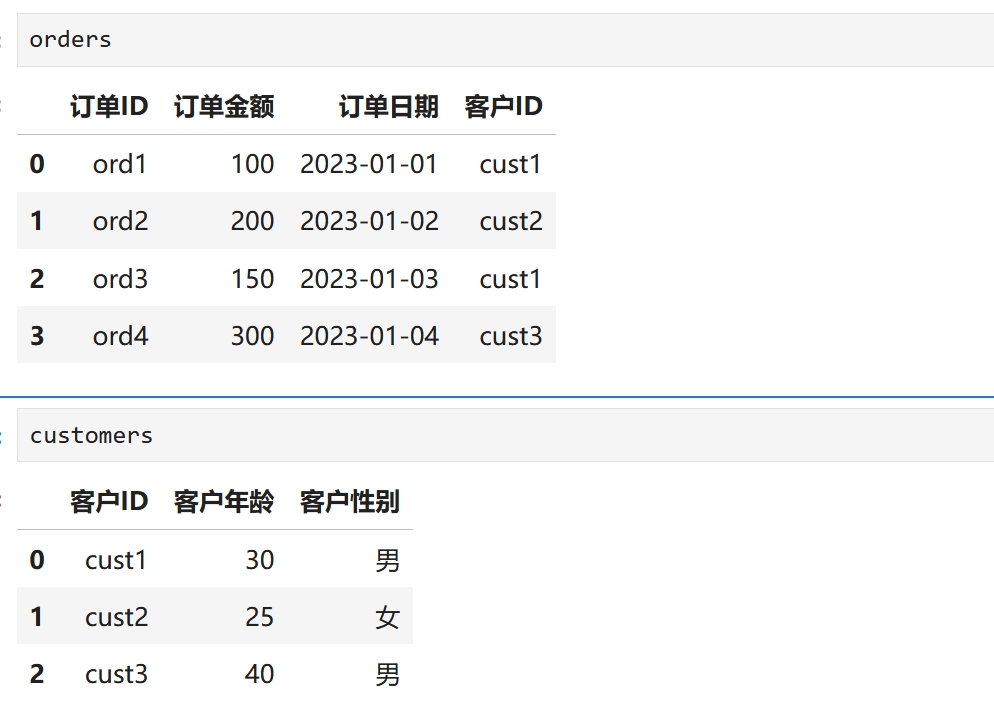
# 订单交易流水表
orders = pd.DataFrame({
'订单ID': ['ord1', 'ord2', 'ord3', 'ord4'],
'订单金额': [100, 200, 150, 300],
'订单日期': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04'],
'客户ID': ['cust1', 'cust2', 'cust1', 'cust3']
})
# 客户表
customers = pd.DataFrame({
'客户ID': ['cust1', 'cust2', 'cust3'],
'客户年龄': [30, 25, 40],
'客户性别': ['男', '女', '男']
})
# 确保日期是datetime类型
orders['订单日期'] = pd.to_datetime(orders['订单日期'])
import featuretools as ft
# 创建一个EntitySet
es = ft.EntitySet(id='transactions')
# 添加实体
es.add_dataframe(dataframe=orders,
dataframe_name='orders',
index='订单ID',
time_index='订单日期')
es.add_dataframe(dataframe=customers,
dataframe_name='customers',
index='客户ID')
# 创建实体间的关系
es.add_relationship('customers', '客户ID', 'orders', '客户ID')
Entityset: transactions
DataFrames:
orders [Rows: 4, Columns: 4]
customers [Rows: 3, Columns: 3]
Relationships:
orders.客户ID -> customers.客户ID
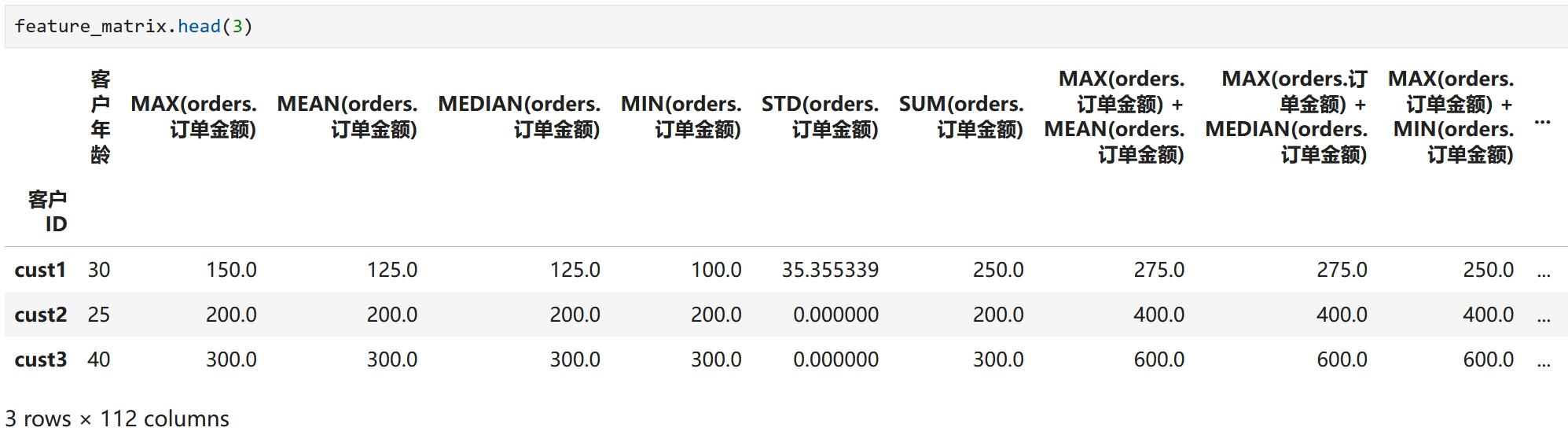
聚合的维度是featuretools自动隐式处理的,这里是按客户ID
# 聚合和转换原语
agg_primitives = ['mean','median', 'sum', 'std', 'min', 'max']
# trans_primitives = ['day', 'month', 'year', 'weekday']
trans_primitives=['add_numeric', 'subtract_numeric', 'multiply_numeric', 'divide_numeric'] # 2列相加减乘除来生成新特征
# 进行深度特征合成
feature_matrix, feature_names = ft.dfs(entityset=es,
target_dataframe_name='customers',
agg_primitives=agg_primitives,
trans_primitives=trans_primitives,
max_depth=2,
verbose=True)
# 查看特征矩阵
# priint(type(feature_matrix)) # pandas.core.frame.DataFrame
# print(feature_matrix.head(3))
# print(feature_names)
STD空值处理
sindex = feature_matrix.isnull().sum()
for index, value in sindex.items():
if value>0:
print(f"Index: {index}, Value: {value}")
feature_matrix[index] = feature_matrix[index].fillna(0)
|
'categorical':类别型数据 'ordinal':有序类别型数据 'numeric':数值型数据(整数或浮点数) 'datetime':日期时间数据 'boolean':布尔值 'text':文本数据 'double'(在某些情况下,作为 'numeric' 的别名) 'integer'(在某些情况下,作为 'numeric' 的特定类型) 'timedelta':时间间隔 'geospatial':地理空间数据(虽然 Featuretools 可能不直接支持此类型用于特征工程) - categorical会将不全为null的string自动转化为categorical - 如果一个列全为null,则不会自动成为categorical - 如果一列值全为null,实则无用,去掉是合适的... from woodwork import logical_types logical_types.Categorical Categorical |
trans_logical_types = {
'PARTY_ID': 'categorical', # 或者使用 Categorical() 对象
'DT_TIME': 'datetime',
}
# 添加交易实体
es.add_dataframe(dataframe=trans,
dataframe_name='trans',
index='TICD',
time_index='DT_TIME',
logical_types=trans_logical_types)
trans是一个pandas数表,经过es.add_dataframe之后 ,
featuretools会选择一些trans中的字符串列使用,并标记为 categorical类型
特征组合之后的矩阵,只包含categorical类型的列与数字列
# 进行深度特征合成
feature_matrix, feature_names = ft.dfs(entityset=es,
target_dataframe_name='trans',
agg_primitives=agg_primitives,
trans_primitives=trans_primitives,
max_depth=3,
verbose=True)
|
|
|
参考
sklearn数据集分割方法汇总