博弈论Shapley值
Shapley值,也称为沙普利值,是合作博弈论中的一个核心概念, 用于衡量合作博弈中各个参与者对合作所创造的价值的贡献程度。 这个概念由经济学家劳埃德·S·沙普利(Lloyd S. Shapley) 于1953年提出(也有说法称其在1951年提出), 沙普利也因此贡献在2012年获得了诺贝尔经济学奖。 收益分配 它用于解决合作博弈中的收益分配问题, 即如何公平地分配合作带来的总收益给每个参与者。 |
在合作博弈中,参与者通过合作形成联盟,并通过合作产生一定的效益或收益。 Shapley值的计算基于参与者在所有可能的联盟组合中的边际贡献。 边际贡献是指当一个参与者加入或离开一个联盟时,对整个联盟价值的变化。 具体计算过程中,需要考虑以下几个因素:
所有可能的联盟组合:
包括参与者单独行动、两两组合、三人组合等,直到所有参与者都参与的联盟。
边际贡献:
对于每个联盟组合,计算参与者加入该联盟时的边际贡献,
即该联盟在参与者 加入前后的价值差。
权重:
每个联盟组合的权重反映了该组合在实际合作中出现的可能性或重要性。
权重通常与联盟组合的大小(即参与者的数量)有关。
最终, Shapley值是通过 将所有可能的联盟组合中参与者的 边际贡献与相应权重相乘,并求和得到的。 这确保了每个参与者的贡献都得到了公平而准确的衡量。 |
Shapley值具有以下几个重要的性质和特点: 公平性: Shapley值通过考虑参与者在所有可能的联盟组合中的边际贡献, 为参与者分配了合理的收益份额,从而实现了利益的公平分配。 唯一性: 在满足一定公理条件(如效率性、对称性、可加性等)的前提下, Shapley值是唯一确定的分配方式。 适用性广泛: Shapley值不仅适用于经济学领域, 还被广泛应用于机器学习、广告、投资组合管理等领域, 用于解释复杂模型的输出或评估不同特征的贡献。 Shapley值基于以下四个公理 效率(Efficiency): 所有参与者分配到的收益之和应该等于合作带来的总收益。 对称性(Symmetry): 如果两个参与者对任何可能的联盟的贡献相同,那么他们应该获得相同的收益。 空参与者(Dummy Player): 如果一个参与者对任何可能的联盟的贡献都是零,那么这个参与者应该获得的收益也是零。 可加性(Additivity): 如果可以将两个不同的游戏合并成一个,那么在合并后的游戏中, 每个参与者获得的收益应该是他在两个独立游戏中获得的收益之和。 应用实例 以一个简单的合作博弈为例,假设有三个参与者A、B、C, 他们可以组成不同的联盟并获得相应的收益。 通过列出所有可能的联盟及其收益, 计算每个参与者参与不同联盟的边际贡献和权重, 最终可以得到每个参与者的Shapley值。 这个值反映了每个参与者在合作过程中的贡献程度,并为他们分配了合理的收益份额。 在机器学习领域,SHAP(SHapley Additive exPlanations)方法基于Shapley值的概念, 通过计算特征对模型预测的边际贡献来解释复杂机器学习模型的输出。 这使得SHAP成为解释“黑箱”模型的重要工具之一。 综上所述,Shapley值是博弈论中一个重要的概念, 它用于衡量合作博弈中各个参与者的贡献程度,并为他们分配合理的收益份额。 通过考虑参与者在所有可能的联盟组合中的边际贡献和权重, Shapley值实现了利益的公平分配,并广泛应用于多个领域。 Shapley值在经济学、政治学和其他领域有许多应用,包括: 成本分配:Shapley值可以用于分配合作游戏中的成本。 利润分配:Shapley值可以用于分配合作游戏中的利润。 资源分配:Shapley值可以用于分配合作游戏中的资源。 决策:Shapley值可以用于评估玩家的贡献对决策过程的影响。 |
给定一个合作游戏,Shapley值将每个玩家的价值分配,以反映他们对游戏的贡献。 该值根据每个玩家的边际贡献计算,考虑玩家的相互作用。 形式上,Shapley值定义如下: 让 G = (N, v) 是一个合作游戏, 其中 N 是玩家的集合,v 是特征函数,它将每个玩家子集的值分配。 Shapley值是一个向量 φ = (φ1, φ2, ..., φn),它将每个玩家 i 在 N 中的价值分配。 Shapley值的计算步骤如下 1. 边际贡献mi: 对于每个玩家 i 在 N 中,计算玩家 i 对游戏的边际贡献,记为 mi。 这是通过考虑包含玩家 i 的所有可能玩家子集, 并计算玩家 i 在这些子集中和不在这些子集中游戏的值差异来实现的。 2. 计算玩家 i 的平均边际贡献,记为 μi。 这是通过对玩家 i 在 所有可能玩家子集中计算的边际贡献 进行平均 来实现的。 3. 玩家 i 的 Shapley值 为 φi = μi / (|N| - 1), 其中 |N| 是游戏中的玩家数量。 
Shapley值的计算考虑了每个参与者在所有可能的联盟中的边际贡献, 并对这些边际贡献进行了加权平均。 权重由参与者在联盟中的位置决定,即参与者加入联盟的顺序。 Shapley值确保了收益的分配满足上述四个公理,从而实现了一种公平的分配。 |
在博弈论中,除了Shapley值以外,还有其他几种分配公平收益的方法,主要包括:
1. **核心(Core)**:
核心是合作博弈论中的一个重要概念,它定义了一个分配集合,其中的分配不被联盟内的任何子集所反对。换句话说,如果分配X在核心内,那么没有任何联盟能够通过重新分配收益来提高所有成员的支付。核心中的分配被认为是帕累托有效的,意味着没有联盟成员可以在不降低其他成员收益的情况下提高自己的收益。这种分配方式强调了公平性和联盟的稳定性。
2. **核仁(Nucleolus)**:
核仁是合作博弈中的另一个解决方案概念,它通过最小化最大剩余(excess)来寻找一个公平的分配方案。核仁是一个向量,它使得所有联盟的剩余(即联盟价值与分配给联盟成员的价值之差)之和最小。核仁试图找到一个分配,使得最不满意的联盟的剩余尽可能小。
3. **班扎夫权利指数(Banzhaf Power Index)**:
班扎夫权利指数是一种衡量参与者在合作博弈中权力或影响力的方法。它基于参与者对联盟的边际贡献,即参与者加入或离开联盟时对联盟价值的影响。班扎夫权利指数通过计算参与者在所有可能的联盟中的边际贡献来确定其权力大小。
这些方法各有特点和适用场景,研究者可以根据具体的博弈情况和需求选择合适的分配方法。
|
TreeShap
import numpy as np
import pandas as pd
import lightgbm as lgb
import shap
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载乳腺癌数据集
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练LightGBM分类器
train_data = lgb.Dataset(X_train, label=y_train)
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'boosting_type': 'gbdt',
'num_leaves': 5,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'max_depth': 5
}
gbm = lgb.train(params, train_data, num_boost_round=100, valid_sets=[train_data])
# 预测测试集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
y_pred_binary = (y_pred > 0.5).astype(int)
accuracy = accuracy_score(y_test, y_pred_binary)
print(f"Accuracy: {accuracy}")
|
展示单个数据/样本 基于其所有特征的 SHAP 贡献 这有助于我们更好地理解模型如何做出预测, 并且可以帮助我们在进行模型选择或优化时识别哪些特征是最重要的。 shap.force_plot() 将会生成一个力导图,它显示每个特征对于当前数据点的贡献。 力导图两侧分别显示了当前数据点的 SHAP 值, 以及全局基线(即所有特征值取中点的情况下的预测结果)的值。 由于每种特征都被赋予了一个颜色和长度,因此可以方便地查看哪些特征对模型的预测影响最大。 另外,通过调整样本和特征,您可以查看模型对于不同输入的响应方式。 shap.force_plot(base_value, shap_values, features) # 使用SHAP解释模型 explainer = shap.TreeExplainer(gbm) shap_values = explainer.shap_values(X_test) # 初始化SHAP的JavaScript可视化库(只需运行一次) # shap.initjs() i=0 shap.force_plot(explainer.expected_value, shap_values[i, :], X_test.iloc[i, :],matplotlib=True,show=True) 
base line
- 基线,它是模型预测的均值
- explainer.expected_value # 1.2551877246746528
- 也叫目标变量期望值,它是模型在所有训练数据上预测结果的均值
- 它相当于所有特征取均值模型的预测结果,理论上它们结果应该一样,
- 一个特征取均值,然后该特征变大或变上,再观察模型的结果是向1靠近还是向0靠近
当说到“所有特征值都取平均(或基线)”时,确实是指对每个特征(即数据表中的每一列)计算其平均值。然而,这并不意味着所有样本的特征值都会变成这个平均值,而是在进行 SHAP 值计算或解释模型预测时,有一个假设或参考点,即如果所有特征都取它们的平均值,模型会预测出什么样的目标变量值。
这个平均值(或基线值)是作为一个参考点来使用的,它并不代表实际数据集中任何具体样本的特征值。相反,它是用来帮助解释特定样本的预测结果是如何相对于这个平均预测结果变动的。
现在,让我们逐步分析您的疑问:
特征值的平均值:
是的,对每个特征(列)计算平均值是这一步的一部分。
所有样本的特征值是否都一样:
不,实际上在数据集中,每个样本的特征值都是独特的。计算特征的平均值是为了得到一个参考点,而不是将所有样本的特征值都设置为这个平均值。
模型预测的目标变量是否都一样:
不,即使所有特征都取平均值,模型预测的目标变量值(在这个参考点下的预测)是一个单一的数值(即基线值或期望值),但它并不代表实际数据集中任何具体样本的预测结果。实际样本的预测结果会根据其特征值的不同而有所不同。
目标变量的期望值:
目标变量的期望值(或基线值)是在所有特征都取平均值时,模型预测的目标变量的值。这个值是通过模型对整个训练数据集进行预测,并计算这些预测值的平均值得到的。它反映了在没有考虑任何特定样本特征的情况下,模型预测的平均水平。
希望这能帮助您更好地理解这些概念。
在进行 SHAP 值计算时,
重要的是要理解这些平均值或基线值是如何作为参考点来使用的,
以及它们是如何帮助解释特定样本的预测结果的。
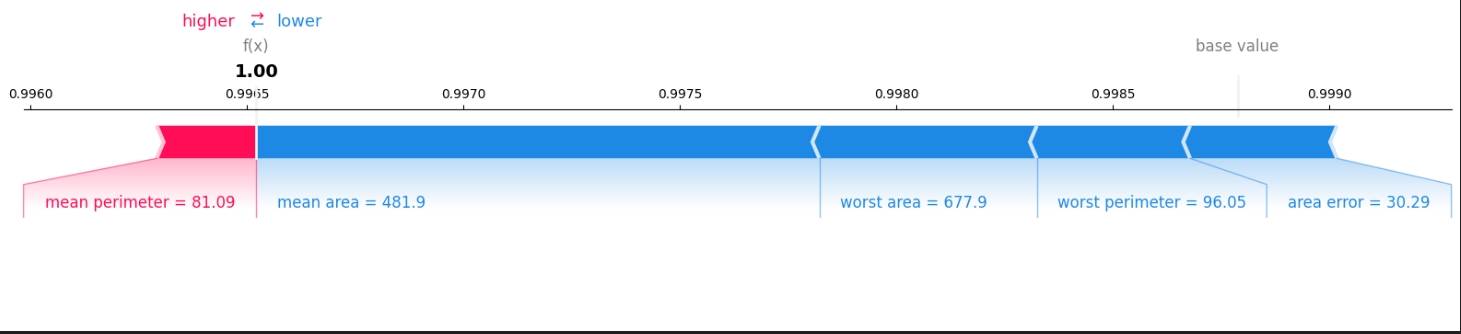
base line 的意义 在base line 为基准,观察特征的值变大或变小,对模型输出结果的影响 对0-1二分类问题, 可以观察特征的值的变化,是让模型更倾向于1还是更倾向于0 high 和 low 在 SHAP 的 force_plot 中, high 和 low 通常表示特征值对于模型预测结果的正向或负向影响。 具体来说,如果一个特征的 SHAP 值位于 high 区域, 它意味着该特征的值增加了模型的预测输出(对于分类任务,可能是增加了属于某一类的概率); 相反,如果位于 low 区域,它减少了模型的预测输出。 high 与 low 的分界线并不代表模型的预测结果,而是表示特征值对预测结果的影响方向。 值的大小的问题 二分类问题模型预测的值应该是在[0,1]之间 但基线所在线上数据显然超出了[0,1]的范围, 这是算法内部映射的问题,该线的上数据与模型的预测有对应关系,但并不是模型的预测结果 该线的主要目的,是为反映 特征取值 与 模型偏离基线的程度 之间的关系 - 用于观察主要是哪些特征影响了模型,使之偏离了基线 - 不需要关注base line所在线上的数值大小 - 那些数值主要意义在于,相对基线偏离了多少, - 比如,下面这张图,|-5.17 - base line | > |4.10 - base line | - 就表示下图所对应的样本特征比上图样本对应的特征对模型的影响大, - 因为它让模型偏离base line的距离远 
base line 线下面的key=value中的key指特征 |
|
如果shap_values返回了3个维度:三维数组的每个维度对应于:单个样本、单个类别(或回归)、两个特征 如果例子中,输出三维数组的每个维度对应于:单个样本、单个类别(或回归)、两个特征。 这是因为,有时模型的预测结果可能是输出多类别的,而shap对每个类别都会输出一组value 输出三维数组的每个维度对应于:单个样本、单个类别(或回归)、两个特征。 只取标签为1的特征的shap value即可 [0,1,:] 如果是2维,直接取shap_values[0]即可取出一个样本 |
|
|
|
|
机器学习模型评估概述
完整解读!机器学习模型评估指标!
------------------------------------------------------------------------ |
|
|
|
|
|
|
|
|
无监督
import numpy as np import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import shap import matplotlib.pyplot as plt from tpf.mlib import COPODModel model = COPODModel() model = COPODModel() # 加载数据集 data = load_iris() X = data.data y = data.target # 训练SVM模型 model = COPODModel() # 初始化SHAP解释器 explainer = shap.KernelExplainer(model.predict_proba, X) # 计算SHAP值 shap_values = explainer.shap_values(X) shap_values
i=0
row_shap_value = shap_values[i, :] #1维
row_data = X[i, :] #1维
shap.force_plot(explainer.expected_value, row_shap_value,row_data,matplotlib=True,show=False)
plt.savefig('a.png', bbox_inches='tight')
|
# 初始化SHAP的JavaScript可视化库(只需运行一次)
shap.initjs() #如果设置matplotlib=True,则可不用设置这一步
i=0
row_shap_value = shap_values[i, :] #1维
row_data = X[i, :] #1维
shap.force_plot(explainer.expected_value, row_shap_value,row_data,matplotlib=True,show=False)
plt.savefig('a.png', bbox_inches='tight')
#这一步保存图像,在python脚本中运行可以保存图像,而在jupyter中无法保存图像,但可以显示
plt.savefig('a.png', bbox_inches='tight')
|
|
|
|
|
|
|
在使用 SHAP (SHapley Additive exPlanations) 库中的 KernelExplainer 时, 第二个参数的选择(即背景数据集)是一个重要的决策点。 这个参数决定了特征值在解释模型预测时所用的参考分布。 背景数据集的选择 KernelExplainer 的第二个参数应该是一个背景数据集, 这个数据集用于计算特征值在模型预测中的边际贡献。 通常,这个数据集的选择取决于你的目的和上下文: 训练集: 使用训练集作为背景数据集可以反映模型在训练数据上的行为。 这有助于理解模型是如何基于训练数据做出预测的。 优点:与模型训练的数据分布一致,可以反映模型在训练过程中的学习。 缺点:可能无法很好地泛化到未见过的数据(如测试集)。 测试集: 使用测试集作为背景数据集可以反映模型在未见过的数据上的行为。 这有助于评估模型在真实世界应用中的表现。 优点:更接近实际应用场景,可以更好地评估模型的泛化能力。 缺点:如果测试集与训练集分布差异较大,可能导致解释结果不稳定或难以理解。 explainer = shap.KernelExplainer(svm_model.predict_proba, X_test) 你选择了 X_test 作为背景数据集。这意味着 SHAP 值将基于测试集的特征分布来计算。 这通常是一个合理的选择,特别是当你想要评估模型在测试集上的表现时。 然而,如果你的测试集非常小或者与训练集分布差异很大,可能需要重新考虑这个选择。 KernelExplainer背景数据官方解释 data : numpy.array or pandas.DataFrame or shap.common.DenseData or any scipy.sparse matrix The background dataset to use for integrating out features. To determine the impact of a feature, that feature is set to "missing" and the change in the model output is observed. Since most models aren't designed to handle arbitrary missing data at test time, we simulate "missing" by replacing the feature with the values it takes in the background dataset. So if the background dataset is a simple sample of all zeros, then we would approximate a feature being missing by setting it to zero. For small problems, this background dataset can be the whole training set, but for larger problems consider using a single reference value or using the ``kmeans`` function to summarize the dataset. Note: for the sparse case, we accept any sparse matrix but convert to lil format for performance. 数据:numpy.array或pandas。DataFrame或shap.common。DenseData或任何学科稀疏矩阵 用于集成特征的背景数据集。 确定影响如果某个特征被设置为“缺失”,则模型输出中的变化观察到。 由于大多数模型的设计不是为了在测试中处理任意缺失的数据时间,我们通过将特征替换为它在背景数据集。 因此,如果背景数据集是一个全零的简单样本,那么我们可以通过将其设置为零来近似缺失的特征。 对于小问题,这个背景数据集可以是整个训练集, 但对于更大的问题,可以考虑使用单个参考值或使用“kmeans”函数对数据集进行汇总。 注意:对于稀疏情况,我们接受任何稀疏矩阵,但转换为lil格式 |
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import shap import matplotlib.pyplot as plt # 加载鸢尾花数据集 iris = load_iris() X = pd.DataFrame(iris.data) y = iris.target # 将数据集分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42) # 训练逻辑回归模型 model = LogisticRegression() model.fit(X_train, y_train) # 计算SHAP值 explainer = shap.Explainer(model, X_train) shap_values = explainer(X_test) # 绘制SHAP图(全局特征重要性,这里以摘要图为例) shap.summary_plot(shap_values, X_test, plot_type='bar') plt.show() 示例二 此处的shap_values的 values与base有差异,但不大 |
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import shap
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
# X = pd.DataFrame(iris.data, columns = iris.feature_names)
X = pd.DataFrame(iris.data)
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 训练SVM模型
svm_model = SVC(kernel='linear', probability=True)
svm_model.fit(X_train, y_train)
# 计算SHAP值
class MyModel():
def __init__(self,model):
self.model = model
def predict_proba(self, X):
c2 = self.model.predict_proba(X)
if c2.ndim == 2:
y_probs = c2[:,1]
else:
y_probs = c2
return y_probs
model = MyModel(svm_model)
explainer = shap.KernelExplainer(model.predict_proba, X_train)
shap_values = explainer.shap_values(X_test)
shap_values
explainer = shap.KernelExplainer(model.predict_proba, X_test) shap_values = explainer.shap_values(X_test) shap_values |
|
|
|
|
深度学习
#### seqone预测 - 重要在于 explainer = shap.KernelExplainer(model.predict_proba, X)中的 model.predict_proba
import torch
from torch import nn
from tpf.mlib.seq import SeqOne
from torch.nn import functional as F
a = torch.randn(64,512) #模拟2维数表
seqone = SeqOne(seq_len=a.shape[1], out_features=2)
seqone(a)[:3]
import shap
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from tpf import pkl_load,pkl_save
import joblib
import sys
from tpf import log
def lg(msg,log_file_path = "/tmp/train.log"):
if log_file_path is None:
log_file_path = "../train.log"
# 超过max_file_size大小自动重写,即超过10M就自动清空一次
log(msg,fil=log_file_path,max_file_size=10485760)
import numpy as np import pandas as pd from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split # 加载乳腺癌数据集 data = load_breast_cancer() X = pd.DataFrame(data.data, columns=data.feature_names) y = pd.DataFrame(data.target,columns=['target']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
seqone = SeqOne(seq_len=X_train.shape[1], out_features=2)
class MyModel():
def __init__(self, model_path, alg_type="seqone"):
"""统一算法模型处理
- 因有多种算法模型,这里统一模型的预测方法为predict_proba
- 仅输出0-1二分类问题中1-异常类别的概率
"""
self.model_path = model_path
self.alg_type = alg_type
def predict_proba(self, X):
lg(f"model_path={self.model_path}")
model = SeqOne(seq_len=X.shape[1], out_features=2)
y_probs = self.cls2_dl_proba(X, model_path=self.model_path, model=model)
return y_probs
@staticmethod
def model_load(model_path, model=None, params=None):
"""深度学习参数文件以.dict保存
"""
if model_path.endswith(".dict"):
if model is None:
lg(f"加载深度学习模型的参数{model_path}\nparams={params}")
if "seqone" in model_path.lower():
seq_len = params["seq_len"]
lg(f"model_path={model_path},seq_len={seq_len}")
model = SeqOne(seq_len=seq_len, out_features=2)
model.load_state_dict(torch.load(model_path,weights_only=False))
else:
model = pkl_load(file_path=model_path, use_joblib=True)
return model
@staticmethod
def model_save(model, model_path):
if model_path.endswith(".dict"):
lg(f"深度学习模型参数保存...{model_path}")
torch.save(model.state_dict(), model_path)
else:
pkl_save(model, file_path=model_path, use_joblib=True)
def cls2_dl_proba(self, data, model_path=None,model=None):
"""二分类问题,深度学习预测,为1的概率值
- 适用返回2列概率的场景,包括深度学习
"""
if model_path is None:
print("the model_path should not be None")
sys.exit()
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = self.model_load(model_path=model_path, model=model)
model.to(device=device)
model.eval()
with torch.no_grad():
if isinstance(data,torch.Tensor):
X = data
else:
X = torch.tensor(np.array(data)).float()
lg(f"{data[:3]}")
X=X.to(device=device)
y_pred = model(X)
y_pred = F.softmax(y_pred,dim=1)
y_porbs = y_pred.cpu().detach().numpy()
if isinstance(y_porbs, np.ndarray) and y_porbs.ndim == 1:
return y_porbs
return y_porbs[:, 1]
model_path = "seqone.pkl.dict" MyModel.model_save(model=seqone,model_path=model_path) model = MyModel(model_path=model_path,alg_type="seqone") model.predict_proba(X_test)
aa = torch.tensor([[2,8],[3,7]]).float()
F.softmax(aa,dim=1)
tensor([[0.0025, 0.9975],
[0.0180, 0.9820]])
X = X_test[:3]
这一步执行是可以执行,但数据超过30行时,计算量很大 # 初始化SHAP解释器 explainer = shap.KernelExplainer(model.predict_proba, X) # 计算SHAP值 shap_values = explainer.shap_values(X) shap_values.shape
i=0
row_shap_value = shap_values[i, :] #1维
# row_data = X[i, :] #1维
row_data = X.iloc[0] #X是pandas数表且带列名,生成的图像中才会有列名=值,如果是np.array则只有值
shap.force_plot(explainer.expected_value, row_shap_value,row_data,matplotlib=True,show=False)
plt.savefig('a.png', bbox_inches='tight')
图看看样子就行,因为模型没有训练,随机初始化进行的预测
|
|
|
|
|
|
|
|
参考