AI编程
业务,编程,AI,市场营销
多维一体
|
## 市面上有哪些工具
1. [Bito](https://bito.ai/) - 比 Copilot 还多些创新
2. [DevChat](https://www.devchat.ai/) -- 前端开源,同时卖GPT服务
3. [Cursor](https://www.cursor.so/) - AI first 的 IDE。
4. [Tabnine](https://www.tabnine.com/) - 代码补全,个人基础版免费
5. [Tongyi Lingma](https://tongyi.aliyun.com/lingma) -- 代码补全,免费。阿里云相关。
6. [CodeGeex](https://codegeex.cn/) -- 清华智谱 CodeGeex3Pro免费可用
7. [Comate](https://comate.baidu.com/zh) -- 百度有免费试用版
8. [Amazon CodeWhisperer](https://aws.amazon.com/codewhisperer/) - 代码补全,免费。AWS 相关的编程能力卓越。其它凑合
阿里
搜索通义灵码(TONGYI Lingma),找到通义灵码后点击安装。
安装后左侧会出来个图标,点击,然后登录
代码左上位置会有一个小图标,还有个下三角,点击下三角会有几个选项
比如,添加注释,优化等
|
### 工作原理
- 模型层:最初使用 OpenAI Codex 模型,它也是 GPT-3.5、GPT-4 的「一部分」。[现在已经完全升级,模型细节未知](https://github.blog/2023-07-28-smarter-more-efficient-coding-github-copilot-goes-beyond-codex-with-improved-ai-model/)。
- 应用层: prompt engineering。Prompt 中包含:
1. 组织上下文:光标前和光标后的代码片段
1. 获取代码片段:其它相关代码片段。当前文件和其它打开的 tab 里的代码被切成每个 60 行的片段,用 [Jaccard 相似度](https://zh.wikipedia.org/wiki/%E9%9B%85%E5%8D%A1%E5%B0%94%E6%8C%87%E6%95%B0)评分,取高分的
- 为什么是打开的 tabs
- 多少个 tabs 是有效的呢?
1. 修饰相关上下文:被取用的代码片段的路径。用注释的方式插入,例如:`# filepath: foo/bar.py`,或者 `// filepath: foo.bar.js`
1. 优先级:根据一些代码常识判断补全输入内容的优先级
1. 补全格式:在函数定义、类定义、if-else 等之后,会补全整段代码,其它时候只补全当前行
|
AI 能力定律:AI 能力的上限,是使用者的判断力 $\text{AI 能力} = \min(\text{AI 能力}, \text{使用者判断力})$ AI 提效定律:AI 提升的效率,与使用者的判断力成正比,与生产力成反比 $\text{效率提升幅度} = \frac{\text{使用者判断力}}{\text{使用者生产力}}$
解读:
1. 使用者的判断力,是最重要的
2. 提升判断力,比提升实操能力更重要。所谓「眼高手低」者的福音
3. 广阔的视野是判断力的养料
|
### 公司推动使用 1. 先养成提问的习惯 2. 提供基本的编程认知:AI 编程不是神,AI 编程是一个结对编程的小伙伴。 3. 购买好账号,让团队都能使用 4. 真的使用起来
##### 可能得声音:
- AI 提示给我的代码,如果我完全按照他的写就死了...(参考:AI 效能定律)
- AI 也就写写简单的函数,没法完成复杂的架构... (参考: 金字塔架构解析)
- 先以架构师的身份,让 AI 辅助你对对架构进行选型: 通过需求文档和业务文档,让 AI 给出架构的建议
- 然后以开发者的身份,让 AI 辅助你写业务代码 (逐层拆分向下写)
- 我觉得 AI 怎么都不对(参考 Google)
|
### 可本机部署的 Tabby
Tabby:https://tabby.tabbyml.com/
- 全开源
- 可以本机部署,也可以独立本地部署
- 支持所有开源编程模型
### 更多开源编程大模型
1. [Code Llama](https://ai.meta.com/blog/code-llama-large-language-model-coding/) - Meta 出品,可能是开源中最强的 (7B,13B, 34B, 70B)
2. [DeepSeek-Coder](https://github.com/deepseek-ai/DeepSeek-Coder) - 从1B到33B都有
3. 💡[CodeGemma](https://huggingface.co/blog/codegemma) - Google出品,上周才出炉
4. [姜子牙 Ziya-Coding-15B-v1](https://huggingface.co/IDEA-CCNL/Ziya-Coding-15B-v1) - 深圳 IDEA 研究院出品
5. [CodeFuse-CodeLlama-34B](https://huggingface.co/codefuse-ai/CodeFuse-CodeLlama-34B) - 阿里出品
6. [WizardCoder](https://github.com/nlpxucan/WizardLM) - WizardLM 出品
https://tabby.tabbyml.com/docs/installation/windows/ https://agiclass.feishu.cn/docx/ClrVddclboshICxgMmgcOggMnU3 linux/windows通用,首次执行会先下载镜像 docker run --entrypoint /opt/tabby/bin/tabby-cpu -it \ -p 8080:8080 -v $HOME/.tabby:/data \ tabbyml/tabby serve --model StarCoder-1B |
环境搭建
|
安装 pip install --upgrade openai pip install python-dotenv pip install chromadb pip install pysqlite3-binary pip install elasticsearch7 pip install --upgrade langchain pip install --upgrade langchain-openai pip install langchain_community pip install qianfan nltk
pip install nltk
import nltk
nltk.download('punkt') # 英文切词、词根、切句等方法
nltk.download('stopwords') # 英文停用词库
|
|
官方文档 https://platform.openai.com/docs/guides/fine-tuning openai注册时中国的手机号无法验证,但是现在可以跳过手机验证,用邮箱注册,同样不能是国内的,需要海外邮箱,如果你能正常访问到openai的官网的话。 可以去注册下,步骤: 1、注册一个 proton.me 的海外邮箱 2、使用这个邮箱去openai去注册 更详细可以去看 leedu.ac.cn 网站的文章 key注册 运行是需要key的,这个是收费的,但送了20次免费调用的机会 https://devcto.com/app https://docs.devcto.com/quickstart#key |
|
代码中指定Key
from openai import OpenAI
client = OpenAI(
api_key = "sk-sb3A1ZCJXkH1kBtQ894dTwtznKQwtdfORqusPSUQ5",
base_url = "https://api.fe8.cn/v1"
)
# 消息
messages = [
{
"role": "system",
"content": "七三笔记网站是一个介绍AI相关知识的网站" # 注入新知识
},
{
"role": "user",
"content": "七三笔记网站是做什么?" # 问问题。可以改改试试
},
]
# 调用 GPT-3.5
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
# 输出回复
print(chat_completion.choices[0].message.content)
七三笔记网站是一个专门介绍人工智能相关知识的网站。它提供各种关于人工智能技术、应用、发展等方面的文章和资讯。
再次调用
七三笔记网站是一个介绍AI相关知识的网站,它致力于分享人工智能领域的学习资源、技术文章、教程等内容,帮助用户了解和学习人工智能的基础知识和最新发展。
环境配置Key
from openai import OpenAI
# 加载 .env 文件到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 初始化 OpenAI 服务。会自动从环境变量加载 OPENAI_API_KEY 和 OPENAI_BASE_URL
client = OpenAI()
# 消息
messages = [
{
"role": "system",
"content": "七三笔记网站是一个关于AI的学习网站" # 注入新知识
},
{
"role": "user",
"content": "七三笔记是什么网站" # 问问题。可以改改试试
},
]
# 调用 GPT-3.5
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
# 输出回复
print(chat_completion.choices[0].message.content)
七三笔记网站是一个提供关于人工智能(AI)相关学习资源的网站。用户可以在该网站上查找与人工智能领域相关的知识、文章、教程、案例研究等内容,帮助他们更深入地了解和学习人工智能领域的知识。 第二次的回答更好,那是因为第二次给的提示更好,提到了“学习”这两个字。 答案也是以“学习”为核心进行展开的,说明OpenAI理解了“学习”这两个字的含义 |
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
client = OpenAI()
prompt = "请讲一个笑话,关于日常"
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=512,
stream=True
)
for chunk in response:
print(chunk.choices[0].text, end='')
的 有一天,小明看着烤肉摊子上的肉香味,忍不住问老板:“老板,你这里的烤肉为什么这么好吃?” 老板笑着回答:“因为我在肉里面加了秘密配方。” 小明好奇地问:“是什么秘密配方呀?” 老板神秘地说:“就是每块肉都要加上一点老板的汗水。” 小明听了后,差点吐出来,连忙说道:“那我也来一份不加汗水的吧!” 老板哈哈大笑:“抱歉,没有老板的汗水加上去,肉就不会熟了!” 小明顿时无语。 |
pip3 install python-dotenv openai

在执行文件所在的目录,添加一个.env文件
vim .env
OPENAI_API_KEY="sk-sb3A1ZCJXkH1kBtQ894dTwtznKQwtdfORqusPSUQ5YYA4sG" # OpenAI 官方的 key
OPENAI_BASE_URL="https://api.fe8.cn/v1"
test.py
import os
from openai import OpenAI
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 配置 OpenAI 服务
client = OpenAI()
response = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "讲个日常笑话",
}
],
model="gpt-3.5-turbo",
)
print(response)
# print(print(response.choices[0].message.content)) # 更具体的的打印
ChatCompletion(
id='chatcmpl-89DJt7WpBzdxM94pqiuVtPSn2jN4y',
choices=[Choice(finish_reason='stop', index=0, logprobs=None,
message=ChatCompletionMessage(
content="
为你讲一个笑话吧:\n\n
有一天,一只蜗牛去买了一辆新车,他把新车开到了修车厂,
对修车工说:“师傅,请给我的车喷涂一个大大的'S'。”
修车工有些好奇,问道:“为什么要喷涂'S'呢?”
蜗牛答道:“这样我就可以让人看到,说这是一辆超级跑车了!”",
role='assistant',
function_call=None,
tool_calls=None))],
created=1713343248,
model='gpt-3.5-turbo',
object='chat.completion',
system_fingerprint=None,
usage=CompletionUsage(
completion_tokens=129,
prompt_tokens=12,
total_tokens=141))
|
大模型架构
这套生成机制的内核叫「Transformer 架构」。Transformer 仍是主流,但其实已经不是最先进的了。 Transformer - Google - 最流行,几乎所有大模型都用它 - OpenAI 的代码 RWKV - PENG Bo - 可并行训练,推理性能极佳,适合在端侧使用 - 官网、RWKV 5 训练代码 Mamba - CMU & Princeton University - 性能更佳,尤其适合长文本生成 - GitHub 目前只有 transformer 被证明了符合 scaling-law。 
|
|
大模型应用技术架构
大模型应用技术特点:门槛低,天花板高。
纯 Prompt - 一问一答,不问不答 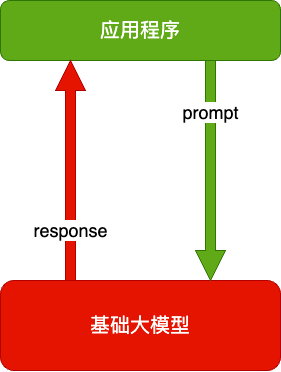
Agent + Function Calling
- Agent:AI 主动提要求
- Function Calling:AI 要求执行某个函数
- 你提一个问题,AI先问你一些这个问题的前提条件你满足哪些
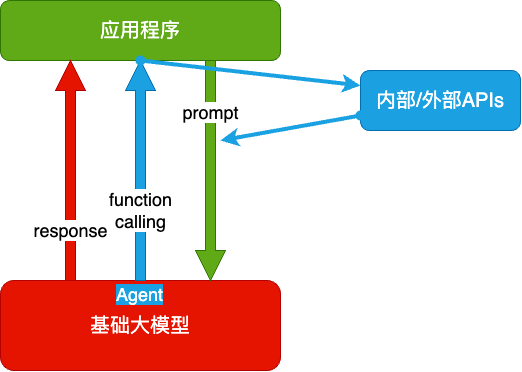
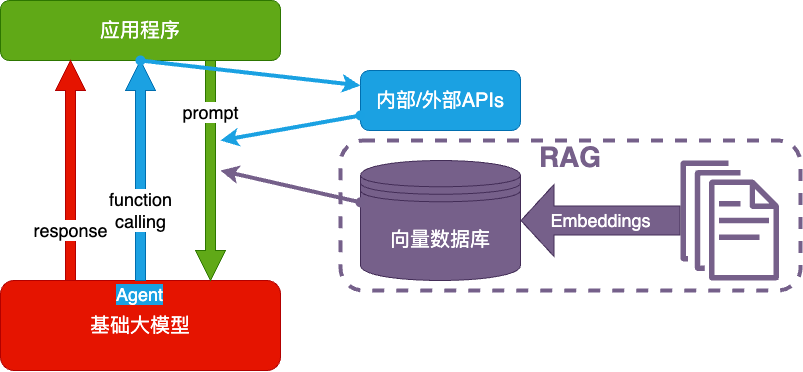
RAG(Retrieval-Augmented Generation)
retrieval 英/rɪˈtriːvl/ 美/rɪˈtriːvl/
n.检索;取回;数据检索;索回
- Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫 向量
- 向量数据库:把向量存起来,方便查找
- 向量搜索:根据输入向量,找到最相似的向量
- 考试答题时,到书上找相关内容,再结合题目组成答案
Fine-tuning(精调/微调) 努力学习考试内容,长期记住,活学活用。 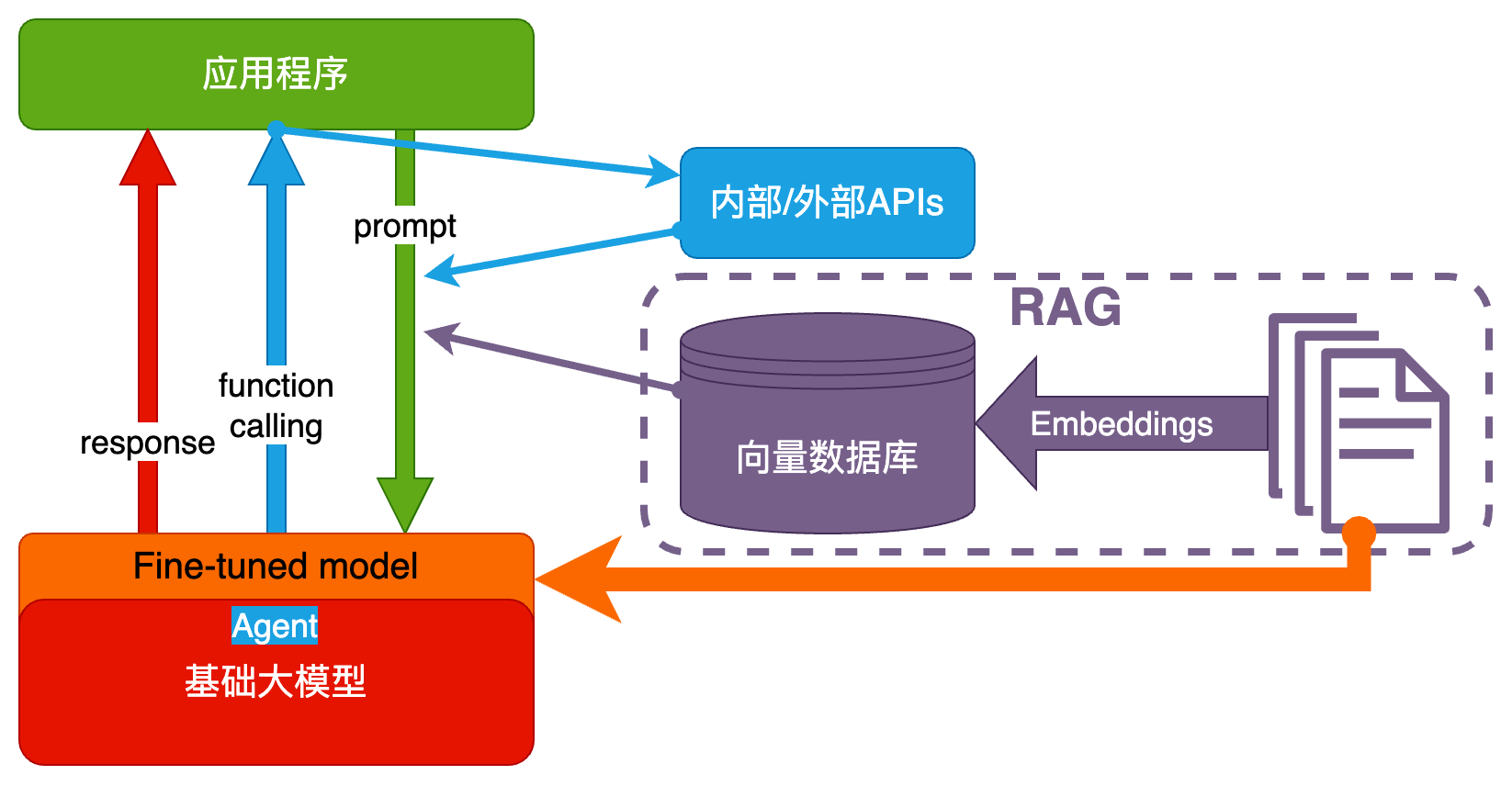
如何选择技术路线 下面是个不严谨但常用思路。 其中最容易被忽略的,是 准备测试数据 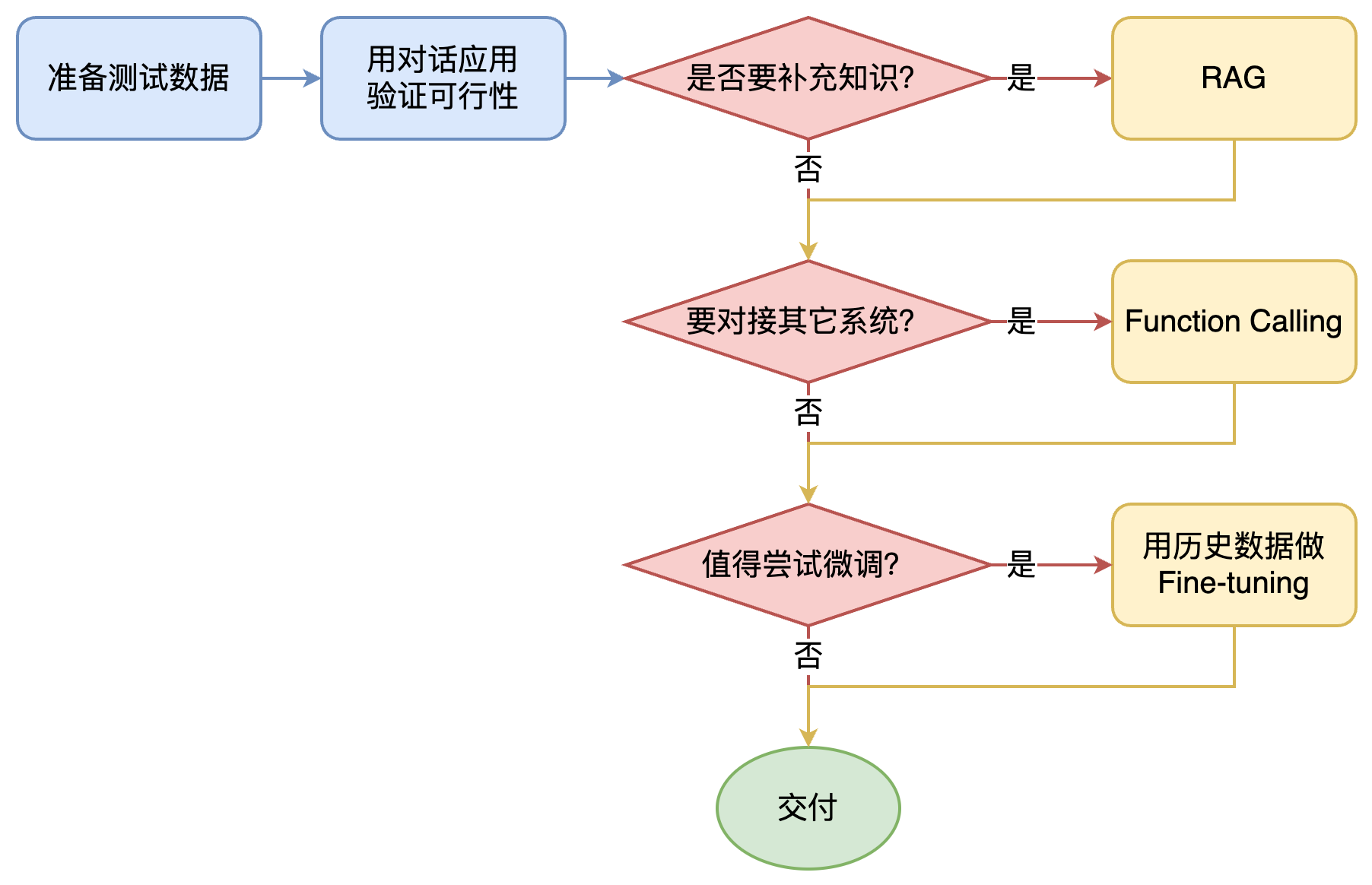
值得尝试 Fine-tuning 的情况:
1. 提高模型输出的稳定性
2. 用户量大,降低推理成本的意义很大
3. 提高大模型的生成速度
4. 需要私有部署
|
合规,安全是首要考虑因素,否则有可能血本无归...
安全指数据安全...
合规,
- 指不违法,
- 要用开源且免费的,
- 公司与组织之间,优先组织,因为公司前期免费,后期一般会收费
推荐:
- 用 ChatALL 做测试,比较高效
- 值得相信的榜单:LMSYS Chatbot Arena Leaderboard
|
1. ChatGPT 是一个基于 GPT(生成式预训练变换器)模型的聊天应用程序。 2. ChatGPT 通常作为一个独立的 web 产品存在,用户可以直接通过网页界面与之互动。 3. ChatGPT 3.5是免费使用的、 GPT4及插件功能需要收费 4. 开通Plus 需要 国外发行的银行卡 OpenAI API - OpenAI API 提供了访问 OpenAI 的多种人工智能模型(包括 GPT-3、GPT-4、Codex 等)的接口。 - API 服务: OpenAI 提供了 API 服务,使开发者能够将其 AI 模型集成到各种应用和服务中。通过这些 API,用户可以访问如 GPT-3 和 DALL-E 这样的强大模型。 - 应用范围: API 在多种场景中得到应用,包括聊天机器人、内容创建、编码辅助、数据分析等。 - ping api.openai.com ChatGPT 与 OpenAI API 的关系 ChatGPT 是面向终端用户的聊天界面产品,而 OpenAI API 则是提供给开发者的工具,用于在各种应用中集成和使用 OpenAI 的 AI 技术。 注意: 注册了ChatGPT 账号,并不代表可以直接免费使用API,通常会赠送一定的额度。 为什么要配置 OpenAI 的 API Base 因为大陆地区是不能访问 https://api.openai.com,所以无法直接使用,需要使用代理。 |
在大模型或人工智能模型的语境中,参数“B”是一个用来量度模型中参数数量的单位。具体来说: “B”代表“Billion”,即“十亿”。 这个单位用来表示模型中的参数量,每个参数用来存储模型的权重和偏差等信息。 例如,当我们说一个模型有“175B”个参数时,这意味着该模型有1750亿个参数。 这样的参数数量通常用来衡量模型的复杂度和其处理信息的能力。 更多的参数通常意味着模型可以更好地理解和生成更复杂、更自然的语言。 类似地,“10b”意味着模型有大约100亿个参数,“13b”意味着模型有大约130亿个参数, 而“70b”则意味着模型有大约700亿个参数。 总结来说,大模型中的参数“B”是一个表示十亿的单位, 用于量化模型中参数的数量,进而反映模型的复杂度和处理能力。 |
|
|
Prompt工程
|
业务特征分解
当人看
一句表达一个意思,清晰明了,无歧义
用简单的模块去拼接出一个完整的意图
- 要有一个宏观的,完整的特征图,不漏
- 每个特征尽量独立,不重
- 表达清晰
模型擅长的格式
不同模型的格式:
1. OpenAI GPT 对 Markdown 格式友好
2. OpenAI 官方出了 Prompt Engineering 教程 ,并提供了一些示例
3. Claude 对 XML 友好。
不断尝试。
有时一字之差,对生成概率的影响都可能是很大的,也可能毫无影响……
重在补充 不要固守「模版」。模版的价值是提醒我们别漏掉什么,而不是必须遵守模版才行。
具体,不抽象,越详细越好
丰富,多场景,多举例,从不同角度去说明
减少歧义,可以明确指出,不要...避免...,明确告诉大模型不要做什么
不断尝试调整
就是 试...
起点低,天花板高
侧重开头与结尾 开头简练地提示自己的观点/目的,想表达什么,想做什么 中间描述细节/步骤/注意事项/不要.../避免... 结尾总结/强调,或者提出自己的问题,通常用户的提问也是放在结尾 丰富的示例
写好一个/多个示例,让大模型比葫芦画瓢,
通过一个个的例子教会大模型该如何去做,
多轮对话
将多轮对答放到prompt中,大模型就能理解对话的上下文
|
角色:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学老师」
指示:对任务进行描述
上下文:给出与任务相关的其它背景信息(尤其在多轮交互中)
例子:必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 in-context learning;实践证明其对输出正确性有很大帮助
输入:任务的输入信息;在提示词中明确的标识出输入
输出:输出的格式描述,以便后继模块自动解析模型的输出结果,比如(JSON、XML)
任务描述,输入输出,组成元素,背景(上下文),专业术语提示 「定义角色」为什么有效? 先定义角色,其实就是在开头把问题域收窄,减少二义性。 大模型对 prompt 开头和结尾的内容更敏感 大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处 https://www.datalearner.com/blog/1051688829605194 非常直观且残酷,2个商业大语言模型 GPT-3.5-Turbo-16K与Claude-1.3-100K 在超长上下文评测任务中表现十分稳定,完胜所有开源模型。 Sebastian Raschka认为,基于transformer的大语言模型架构本身应该不会出现这种偏差。 反而是基于RNN的模型可能会因为序列过长出现这种问题 (因为RNN是按照序列处理的,早先处理的内容可能会被遗忘。 而transformer是按照位置编码,一次性输入,没有先后概念)。 因此,他怀疑可能是大多数人类写的文章内容习惯把重要的信息放在文章的开头和结尾,影响了大模型的训练结果。 Lost in the Middle: How Language Models Use Long Contexts https://arxiv.org/abs/2307.03172 CHARGPT https://askchat.ai/?r=chatgpt&gclid=EAIaIQobChMImtqE_ZbVhQMVEU3CBR1f7QmFEAEYASAAEgL5JfD_BwE
|
|
对话系统的基本模块和思路 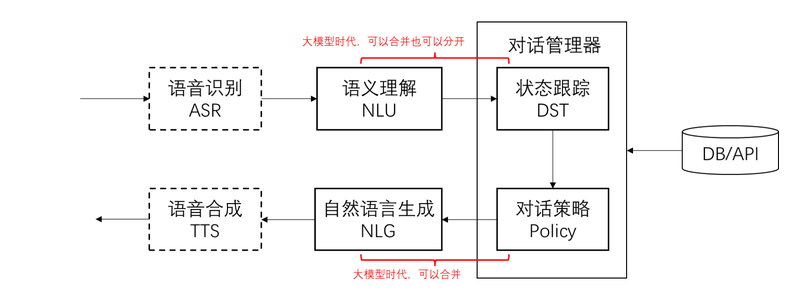
把大模型用于软件系统的核心思路:
1. 把输入的自然语言对话,转成结构化的信息(NLU)
- json
- 类,属性
2. 用传统软件手段处理结构化信息,得到处理策略
3. 把策略转成自然语言输出(NLG)
- json
|
|
|
|
|
Function Calling
|
大模型两大缺陷:
所以:大模型需要连接真实世界,并对接真逻辑系统。
比如算加法:
1. 把 100 以内所有加法算式都训练给大模型,ta 就能回答 100 以内的加法算式,但仍有概率出错
2. 如果问 ta 更大数字的加法,出错概率就会更大
3. 因为 ta 并不懂「加法」,只是记住了 100 以内的加法算式的统计规律
4. Ta 是用字面意义做数学
数学能力最强的软件系统是 Wolfram Alpha,推荐阅读这篇文章了解它和 ChatGPT 原理的不同:[《Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT》](https://writings.stephenwolfram.com/2023/01/wolframalpha-as-the-way-to-bring-computational-knowledge-superpowers-to-chatgpt/)
PS. Wolfram 的书《[这就是 ChatGPT!](https://u.jd.com/p8x8bdp)》是从神经网络层面解释大模型原理的最好读的书。[英文版免费](https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/)
划重点:
把 AI 当人看! 这个过程中,GPT 已经是个 agent 了。 GPTs 与它的平替们
[OpenAI GPTs](https://chat.openai.com/gpts/discovery)
1. 无需编程,就能定制个性对话机器人的平台
2. 可以放入自己的知识库,实现 RAG(后面会讲)
3. 可以通过 actions 对接专有数据和功能
4. 内置 DALL·E 3 文生图和 Code Interpreter 能力
5. 只有 ChatGPT Plus 会员可以使用
推荐两款平替:
字节跳动 Coze(扣子)[中国版](https://www.coze.cn/) [国际版](https://www.coze.com/)
1. 国际版可以免费使用 GPT-4 等 OpenAI 的服务!大羊毛!
2. 中国版发展势头很猛,使用云雀大模型
3. 功能更强大
[Dify](https://dify.ai/)
1. 开源,中国公司开发
2. 功能最丰富
3. 可以本地部署,支持几乎所有大模型
4. 有 GUI,也有 API
有这类无需开发的工具,为什么还要学大模型开发技术呢?
1. 它们都无法针对业务需求做极致调优
2. 它们和其它业务系统的集成不是特别方便
Function Calling 技术可以把大模型和业务系统连接,实现更丰富的功能。
|
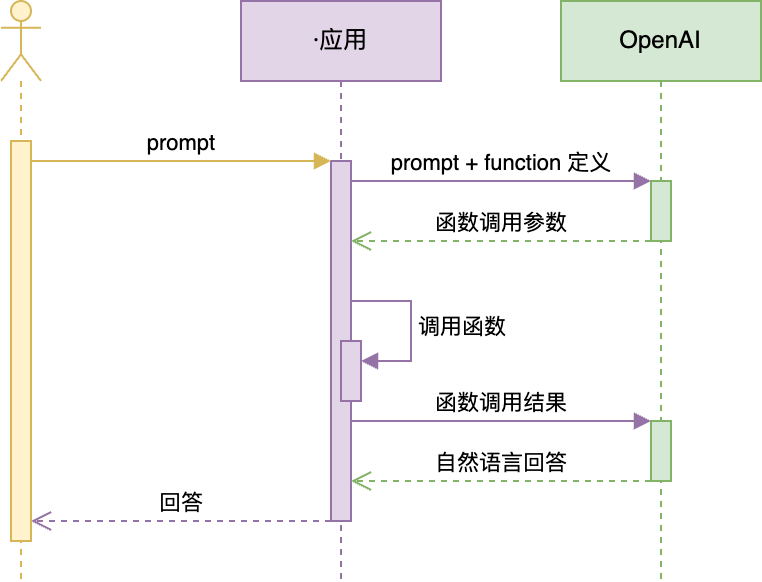
Function Calling 完整的官方接口文档:https://platform.openai.com/docs/guides/function-calling 值得一提:接口里的 `tools`,最初版本叫 `functions`。这是一个很有趣的指向
|
|
|
|
|
|
|
RAG
|
什么是LLM
在人工智能(AI)领域,尤其是在自然语言处理(NLP)分支中,
LLM通常指的是“大语言模型”(Large Language Model)。
这种类型的模型是基于机器学习技术构建的,
通过在海量文本数据上进行训练,它们能够学习并理解自然语言的复杂结构和模式。
大语言模型的核心思想是利用大规模的无监督学习来捕捉语言的统计规律和语义特征,
这使它们能够执行诸如文本生成、问答、翻译和摘要等多种自然语言处理任务。
由于它们通常基于深度学习架构,如Transformer模型,并且在非常大的数据集上进行预训练,
因此它们能够展现出对自然语言的深刻理解和生成能力,
甚至在某些情况下表现出逻辑推理和常识应用的能力。
近年来,随着计算资源的增加和算法的改进,大语言模型的规模和性能都在不断增长,
它们在NLP领域的应用也越来越广泛,成为了推动这一领域发展的关键技术之一。
知名的例子包括OpenAI的GPT-3和GPT-4,以及Meta的类似模型等。
这些模型往往需要大量的计算资源来进行训练,并且在多种下游任务上显示出卓越的表现。
LLM 固有的局限性
LLM 的知识 不是实时的
LLM 的知识 具有通用性,缺少针对性
- LLM 可能不知道你私有的领域/业务知识
检索增强生成(RAG)
RAG(Retrieval Augmented Generation),
通过分片去除大量无用信息检索少量有效信息的方法来增强生成模型的能力。
Retrieval 英/rɪˈtriːvl/ 美/rɪˈtriːvl/ 检索;取回;文献检索
Augmented 英/ɔːɡˈmentɪd/ 美/ɔːɡˈmentɪd/ 增广;扩维
Generation 英/ˌdʒenəˈreɪʃn/ 美/ˌdʒenəˈreɪʃn/ n.一代;产生;一批,
|
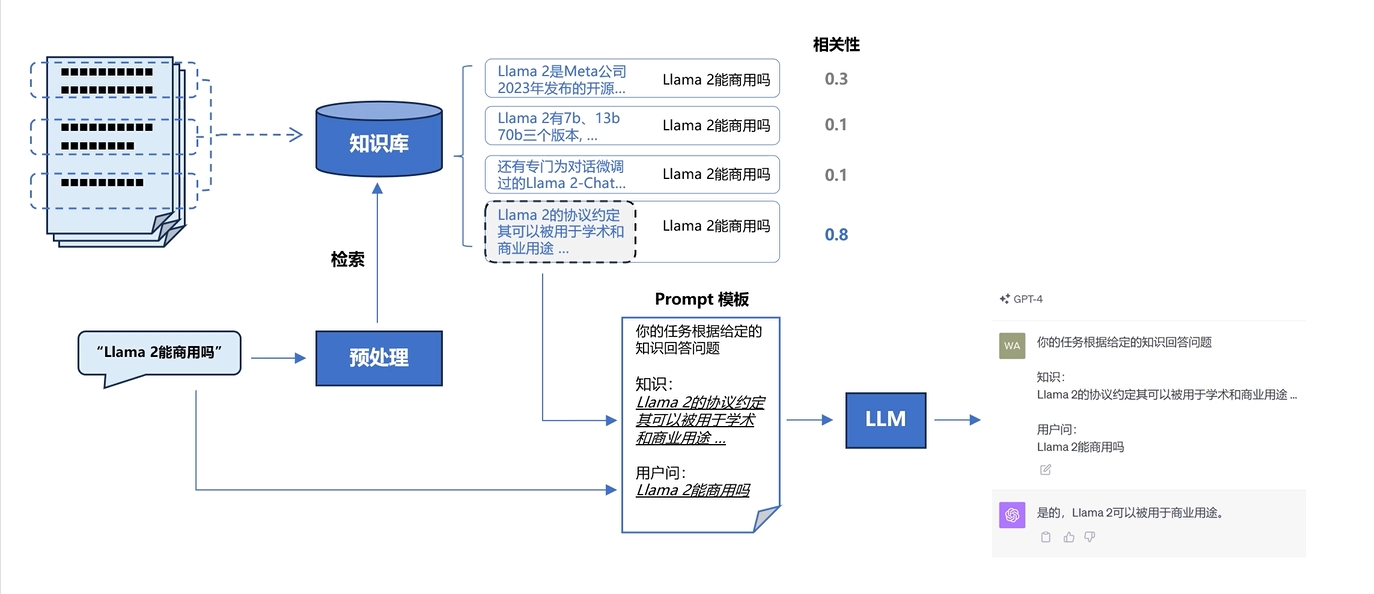
搭建过程: 文档加载,并按一定条件切割成片段 将切割的文本片段灌入检索引擎 封装检索接口 构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复 ES7连接:ubantu环境起Jupyter & es7
from elasticsearch7 import Elasticsearch, helpers
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
import re
import warnings
warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings
# 1. 创建Elasticsearch连接
# xt@qisan:/opt/app/es7/elasticsearch-7.17.4$ cd /opt/tpf/aiwks/code/
# ubantu环境起Jupyter & es7
es = Elasticsearch(
hosts=['http://127.0.0.1:9200'], # 服务地址与端口
verify_certificates=False
# http_auth=("elastic", "aaa"), # 用户名,密码
)
# 2. 定义索引名称
index_name = "index"
# 3. 如果索引已存在,删除它(仅供演示,实际应用时不需要这步)
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
# 4. 创建索引
es.indices.create(index=index_name)
|
pip install pdfminer.six
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphs
paragraphs = extract_text_from_pdf("llama2.pdf", min_line_length=10)
for para in paragraphs[:4]:
print(para+"\n")
|
安装 NLTK(文本处理方法库)
pip install nltk
from elasticsearch7 import Elasticsearch, helpers
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
import re
import warnings
warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings
import ssl
try:
_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:
pass
else:
ssl._create_default_https_context = _create_unverified_https_context
nltk.download('punkt') # 英文切词、词根、切句等方法
nltk.download('stopwords') # 英文停用词库
Elasticsearch(简称ES)是一个广泛应用的开源搜索引擎: https://www.elastic.co/ 关于ES的安装、部署等知识,网上可以找到大量资料,例如: https://juejin.cn/post/7104875268166123528 关于经典信息检索技术的更多细节,可以参考: https://nlp.stanford.edu/IR-book/information-retrieval-book.html
from elasticsearch7 import Elasticsearch, helpers
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
import re
import warnings
warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings
def to_keywords(input_string):
'''(英文)文本只保留关键字'''
# 使用正则表达式替换所有非字母数字的字符为空格
no_symbols = re.sub(r'[^a-zA-Z0-9\s]', ' ', input_string)
word_tokens = word_tokenize(no_symbols)
# 加载停用词表
stop_words = set(stopwords.words('english'))
ps = PorterStemmer()
# 去停用词,取词根
filtered_sentence = [ps.stem(w)
for w in word_tokens if not w.lower() in stop_words]
return ' '.join(filtered_sentence)
# 1. 创建Elasticsearch连接
es = Elasticsearch(
hosts=['http://192.168.73.11:9200'], # 服务地址与端口
verify_certificates=False
# http_auth=("elastic", "aaa"), # 用户名,密码
)
# 2. 定义索引名称
index_name = "index"
# 3. 如果索引已存在,删除它(仅供演示,实际应用时不需要这步)
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
# 4. 创建索引
es.indices.create(index=index_name)
# 5. 灌库指令
actions = [
{
"_index": index_name,
"_source": {
"keywords": to_keywords(para),
"text": para
}
}
for para in [
"今天天气不错",]
]
# 6. 文本灌库
helpers.bulk(es, actions)
|
|
|
|
|
RAG-Vec
|
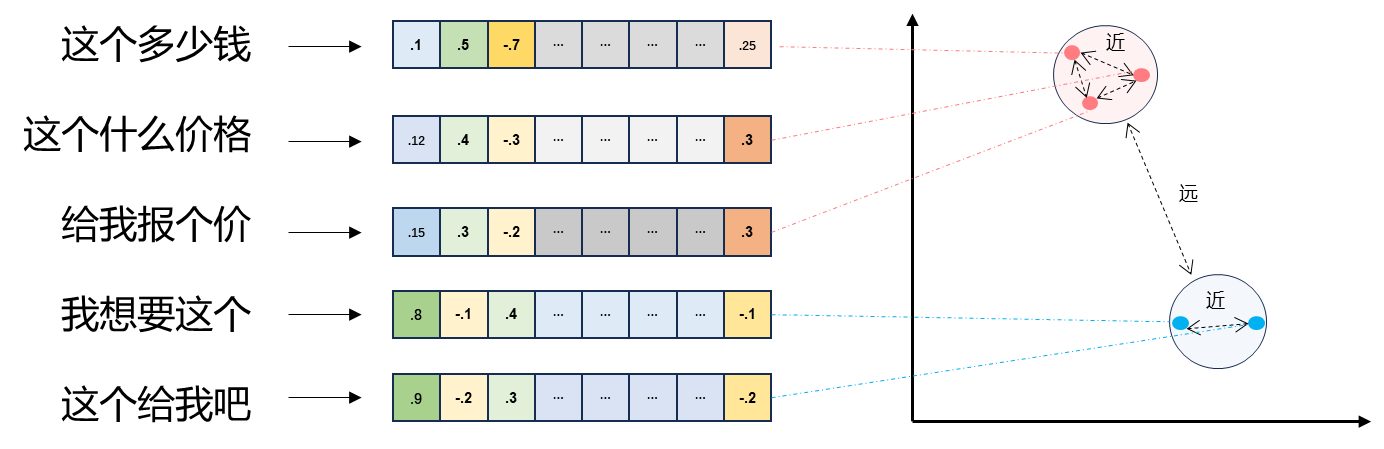
文本向量化
1. 将文本转成n个浮点数:每个数对应一个维度
2. 一个数组 对应 n维空间的一个点,文本向量 又叫 Embeddings
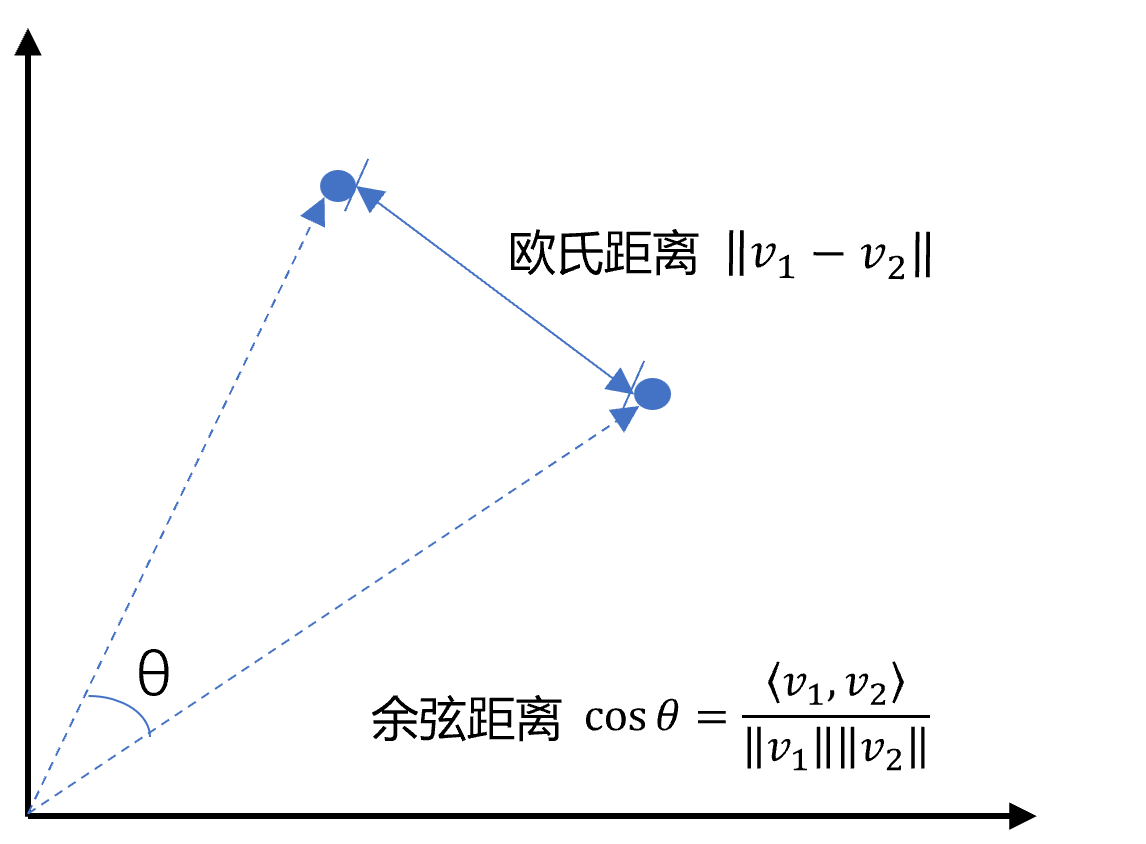
3. 向量之间可以计算距离,距离远近对应 语义相似度 大小
sbert文本向量化
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Our sentences to encode
sentences = [
"This framework generates embeddings for each input sentence",
"Sentences are passed as a list of string.",
"The quick brown fox jumps over the lazy dog."
]
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
embedding.shape
(384,)
扩展阅读: https://www.sbert.net
向量相似度 pip install chromadb pip install pysqlite3
|
|
向量数据库
|
|
|
|
|
|
|
|
AutoAgent
不要对要素的取值/定义做任何假设,确保你的信息来自给定的数据源。不要编造信息。DO NOT MAKE UP ANY INFORMATION!!!
- 当一个概述/定义/要素GPT无法理解时,GPT就会像人一样,从它能理解的事物中选一个最大概率的事物
- 这往往是不对的,该句话要求它不理解的时候,不要假设,不要随意就下结论,而是再去找,再去确定,直接找到准确的结果
-
已经明确获得取值的子概念,将其取值完整备注在子概念后。
- 当问题过长时,加上这句话,就不会遗忘关键的,已确定的信息
6. 如果执行某个指令或工具失败,尝试改变参数或参数格式再次调用。
- 有时候工具选对了,但参数选错了
9. 已经得到的信息,不要反复查询。
- 防止进行死循环
15. 不要向用户提问。
- 不是所有的智能体都不能向用户提问,
- 只是该方案设计是如此
|
|
|
|
|
|
|
|
Fine-tuning
fine 英/faɪn/ 美/faɪn/
adj.好的;(表示满意)很好,不错,满意;美好的;健康的;漂亮的;晴朗的;纯的;纤细的;高质量的;精巧的;好看的;(指行为、建议、决定)可接受;值得尊敬的;小颗粒制成的;难以看出的
adv.可接受;够好;蛮不错
fine这里应该是取 精细,好,不错,美好的,可接受等之意
tuning 英/ˈtjuːnɪŋ/ 美/ˈtuːnɪŋ/
v.(给收音机、电视等)调谐,调频道;调整,调节(发动机);(为乐器)调音,校音
n.【无线】调谐;收听;【乐】调音[弦]
fine-tuning: 微调,精调
预训练好处
- 通过完型填空的方式,学习大量的语言,推理空白该是什么
- 是一个语言模型
- 节省了数据成本,训练成本
- 形成一个通用的模型底座
如果有一个通用的底层,再在垂直领域少量的数据训练,就比直接在大量的纯垂直领域数据上训练出来的模型效果还要好 - 解决了垂直领域数据量不足的问题 - 降低了总体成本
大模型
- 参数量巨大,虽然在垂直领域需要的数据少,但需要的计算量巨大
- 为解决该问题,在原有模型的基础上,额外增加一些参数
- 原模型预训练的参数在训练的过程中不变,被冻结
- 如此需要的算力就降低了
这就是微调
微调
大神不建议从提升大模型的性能这个角度发力,包括微调
建议做智能体,AutoAgent
|
首先下载ollamaSetup,安装ollama以后,就用ollama pull 模型就行 或者直接ollama run 模型 就下载到本地了 默认在C盘的当前用户local目录的.ollama目录下 可以移植到其他目录,修改下环境变量即可 原生模型和ollama模型的模型格式不一样的,想做微调的话,还是得下原生的 推理没问题 对,微调的话是的 手撸私有AI大模型——ollama本地部署私有大模型 https://ollama.com/download
|
|
|
|
|
|
|
参考
Huggingface 镜像站