charbot torch demo
Chatbot Tutorial https://pytorch.org/tutorials/beginner/chatbot_tutorial.html?highlight=seq2seq Author: Matthew Inkawhich In this tutorial, we explore a fun and interesting use-case of recurrent sequence-to-sequence models. We will train a simple chatbot using movie scripts from the Cornell Movie-Dialogs Corpus.
语料及数据加工
序列对与词典
1. 这里的语料是一部电影中的人物对话 2. 从这些对话中抽出一对对语句 3. 在这个过程,收集不重复单词的集合 4. 去除低频,高频以及停用词 5. 特殊字符删除,特殊文本转码等 6. 句子单词个数超过10个的部分,截断 最终输出结果有二: 1. 词典 2. 序列对 列表
新加三个标记
# ===============================================================
#----------------------------------
# 上面为对原始数据的处理
# 下面是数据转数字处理:文本转索引,批次,是公共的
# 输入:实际长度
# 输出:mask, max_target_len
# 最后再按问句长度做一个降维处理
#-------------------------------------
# ===============================================================
import os
import itertools
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
import csv
import random
import codecs
from ai.params import DATA_ROOT
from ai.box.d1 import pkl_load,pkl_save
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import csv
import random
import codecs
import re
import os
# 编码问题
import unicodedata
# 版本兼容
from io import open
from pprint import pprint as pp
USE_CUDA = torch.cuda.is_available()
"""
检测是否有GPU
"""
device = torch.device("cuda" if USE_CUDA else "cpu")
print(device)
"""
构建字典
"""
# 定义几个必备的 token
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
class Voc(object):
"""
每添加一个句子,更新一次字典;
封装有 word2index,index2word以及 词频 word2count
"""
def __init__(self, name):
self.name = name
"""
字典名称
"""
self.trimmed = False
"""
是否舍弃低频词,
False:不舍弃
"""
self.word2index = {}
self.word2count = {} # 词频
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count SOS, EOS, PAD
def addSentence(self, sentence):
# 英文分词 -- “ ”
# 不用特殊工具
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
"""
添加新词
"""
if word not in self.word2index:
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
self.word2count[word] += 1 #单词个数加1
def trim(self, min_count):
"""
Remove words below a certain count threshold
"""
if self.trimmed:
return
self.trimmed = True
keep_words = []
for k, v in self.word2count.items():
if v >= min_count:
keep_words.append(k)
# Reinitialize dictionaries
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count default tokens
for word in keep_words:
self.addWord(word)
data_dir = os.path.join(DATA_ROOT, "chatbox1")
data_voc_pairs = os.path.join(data_dir,"tmp_voc_pairs.pkl")
voc,pairs = pkl_load(file_path=data_voc_pairs)
# 这些word2index的index是从3开始的
print(voc.word2index["hello"]) #787
print(voc.index2word[0]) #PAD
print(len(pairs)) #53165
print(pairs[0]) #['there .', 'where ?']
数据加工
|
句子转索引向量
1. 英文分词,以空格拆分即可
2. 根据voc.word2index将某个词转为索引
3. 在每句话的后面加 一个结束标记
# 定义几个必备的 token
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
def indexesFromSentence(voc, sentence):
"""按句子将文本转为索引向量
单词 -- 索引,并在句子后面加上结束符
[i am a good boy.] --- [34, 13, 53, 634, 12, .... 2]
"""
return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]
这要验证的是序列到序列模型,
该序列是一个生成模型,
根据已有的信息,在序列的尾部补啊补,补啊补
什么时候结束?
就是遇到结束标记,所以每句话后面要加一个结束标记
生成模型是保留高频词,去除低频词
分类模型是去除高频词
|
|
开始结束标记 开始与结束标记理论上只需要解码器有就可以, 当然了,编码器有这个也没什么不良影响 针对解码器, 开始标记与结束标记的不同在于, 开始标记的序列索引位置为0,全是0,因为它位于每句话的开头, 而结束标记因每句话的长度不定,其索引位置无法固定 关键是,批次化计算要求shape对齐,会有补0这么一个操作, 把一个批次中所有句子补成一样长 所以,编码器序列 在句子转索引向量时加上 对后面代码的编写方便一些 而开始标记可以在编码时加上,也可以在训练时加 这里indexesFromSentence方法没有加开始标记, 但在训练解码器时,为每句话都加上了开始标记
|
import torch
from torch import nn
import itertools
def zeroPadding(lst, fillvalue=0):
"""批次化处理,补零并完成序列长度与批次维度的转换
[b, max_len] -- [seq_len, b]
params:
-----------------------------
l:索引向量
"""
return list(itertools.zip_longest(*lst, fillvalue=fillvalue))

补0,行转列 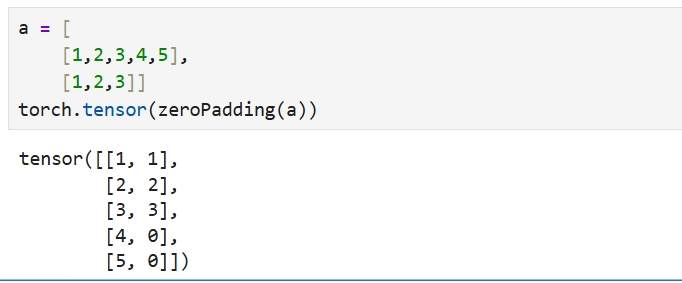
相当于使用列向量表示一个句子 |
|
补0对齐,转换维度--[seq_len,batch_size]
def inputVar(l, voc):
"""对问句进行批次化处理
输出:
- padVar ,shape=[seq_len, batch_size]
- lengths,批次维度中每个序列未补0时的长度
params:
-----------------------------
- 一个批次问答对中的问句列表,比如 [[i am a boy], [dog], [good morning]] [b, max_len]
- seq_len为当前这个批次中序列的最大长度
"""
# 语句变索引序列
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
# 对齐,将每句话补零,并将shape转换为[seq_len, batch_size]
padList = zeroPadding(indexes_batch)
padVar = torch.LongTensor(padList)
# 求每句话的长度
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
return padVar, lengths
lengths是为了从padVar提取单词, - 要舍弃补的数据 - 舍弃句尾标记的EOS - 只要单词数据 转换前是单词列表,[batch_size,seq_len],是单词,是汉字 转换后是索引列表,[seq_len,batch_size],是数字,是整数 |
因为对于对齐数据,进行了补0操作, 因此要标记哪些位置是数据,哪些位置不是
def binaryMatrix(l, value=PAD_token):
"""构建掩码
原来有数据的地方:为 1,将来变为 True
原来没有数据的地方:为0, 将来变为 False
params:
-----------------------------
- l: 索引向量
"""
m = []
for i, seq in enumerate(l):
m.append([])
for token in seq:
if token == PAD_token:
m[i].append(0)
else:
m[i].append(1)
return m
标记数据只针对了输出语句
def outputVar(l, voc):
"""
输出语句处理
"""
# 句子变索引序列
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
# 补零对齐,并转换维度,[seq_len,batch]
padList = zeroPadding(indexes_batch)
# 求掩码 [max_len, batch_size]
mask = binaryMatrix(padList)
mask = torch.BoolTensor(mask)
# [max_len, batch_size]
padVar = torch.LongTensor(padList)
# 本批次的最大长度
max_target_len = max([len(indexes) for indexes in indexes_batch])
return padVar, mask, max_target_len
答句向量化处理 - 输入前[batch_size,seq_len],元素是单词 - 经过词转index,补0对齐,转换维度 - 输出为[seq_len,batch_size] mask - 标记哪些位置是单词,有单词的位置将来才参与损失函数的计算 - 无单词的位置,是补的,是凑形状的,不参与损失计算 max_target_len - 训练过程是按批次进行的 - 对于编码器是按批次计算的,一次计算就结束了 - 对于解码器,是一个单词一个单词训练的,是一个for循环,循环的次数就是max_target_len |
|
|
批次处理
数据批次处理是为了模型训练 - 所以数据的格式是为模型更好训练服务的 batch2TrainData
def batch2TrainData(voc, pair_batch):
"""把一个批量的问答对,转为一个训练数据
return
-------------------
- input,shape=[seq_len, batch_size]
- lengths,shape=[batch_size],每个批次序列单词长度
- output,shape=[seq_len, batch_size]
- mask,码表,数据为True,PAD为False
- max_target_len,最大序列单词个数,即最大序列长度
"""
# 按问句长度对批次降序排列
pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)
# 将问句和答句拆分开
input_batch, output_batch = [], []
for pair in pair_batch:
input_batch.append(pair[0])
output_batch.append(pair[1])
# 将问句变为张量
inp, lengths = inputVar(input_batch, voc)
# 将答句变为张量
output, mask, max_target_len = outputVar(output_batch, voc)
return inp, lengths, output, mask, max_target_len
|
pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)
- 这句话对批次数据进行了排序
- 在深度学习通常是要打乱数据的顺序
这是因为在编码器模型的设计中用到了
# Pack padded batch of sequences for RNN module
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
该函数要求数据有序
------------------------------------------------------------------------------------
|
|
|
|
|
|
|
参考