文本分类TextCNN
文本分类模型
import torch
from torch import nn
from torch.nn import functional as F
class TextCNN3(nn.Module):
"""
TextCNN优化,
"""
def __init__(self,num_embeddings, embedding_dim,padding_idx,seq_len):
super().__init__()
self.embed = nn.Embedding(num_embeddings=num_embeddings,
embedding_dim=embedding_dim,
padding_idx=padding_idx)
# [N, C, seq_len] --> [N, C, seq_len-1],[N, C, seq_len-kernel_size+1]
self.gram_2 = nn.Sequential(
nn.Conv1d(in_channels=embedding_dim, out_channels=256, kernel_size=2),
nn.BatchNorm1d(num_features=256),
nn.ReLU(),
nn.MaxPool1d(kernel_size=seq_len-1) # [N, C, 1]
)
# [N, C, seq_len, 1] --> [N, C, seq_len-2, 1]
self.gram_3 = nn.Sequential(
nn.Conv1d(in_channels=embedding_dim, out_channels=256, kernel_size=3),
nn.BatchNorm1d(num_features=256),
nn.ReLU(),
nn.MaxPool1d(kernel_size=seq_len-2) # [N, C, 1]
)
# [N, C, seq_len, 1] --> [N, C, seq_len-3, 1]
self.gram_4 = nn.Sequential(
nn.Conv1d(in_channels=embedding_dim, out_channels=256, kernel_size=4),
nn.BatchNorm1d(num_features=256),
nn.ReLU(),
nn.MaxPool1d(kernel_size=seq_len-3) # [N, C, 1]
)
self.dropout1 = nn.Dropout(p=0.2)
self.fc1 = nn.Linear(in_features=256*3, out_features=2)
def forward(self,X):
# [B,seq_len,embedding_dim]
x = self.embed(X)
# [B, seq_len, embedding_dim] --> [B, embedding_dim, seq_len]
x = torch.permute(input=x, dims=(0, 2, 1))
# print(x.shape) # torch.Size([128, 256, 87])
x1 = self.gram_2(x)
# print(f"x1.shape={x1.shape}") #torch.Size([128, 256, 1])
x2 = self.gram_3(x)
x3 = self.gram_4(x)
x = torch.concat(tensors=(x1,x2,x3),dim=1)
# print(x.shape) # torch.Size([128, 768, 1])
x = torch.squeeze(x)
x = self.dropout1(x)
x = self.fc1(x)
return x
seq_len=10 embedding_dim=100 num_embeddings=3000 padding_idx=0 batch_size = 16 index = torch.randint(high=num_embeddings,size=(batch_size,seq_len)) model = TextCNN3(num_embeddings, embedding_dim, padding_idx, seq_len)
import time
start_time = time.time() # 记录程序开始时间
y=model(X=index)
end_time = time.time() # 记录程序结束时间
tim_ms = round((end_time - start_time)*1000,2)
print("程序运行时间为", tim_ms, "毫秒")
程序运行时间为 6.38 毫秒
import datetime
start_time = datetime.datetime.now() # 记录程序开始时间
y=model(X=index)
end_time = datetime.datetime.now() # 记录程序结束时间
tim = (end_time - start_time)
# print(type(tim)) # class 'datetime.timedelta'
print("程序运行时间为", tim.total_seconds() *1000,"毫秒")
程序运行时间为 6.836 毫秒
TextCNN模型测速
TextCNN模型测速
测速100次
import matplotlib.pyplot as plt
import datetime
tims = []
with torch.no_grad():
for i in range(100):
start_time = datetime.datetime.now() # 记录程序开始时间
y=model(X=index)
end_time = datetime.datetime.now() # 记录程序结束时间
tim = (end_time - start_time)
tims.append(tim.total_seconds() *1000)
plt.plot(tims)
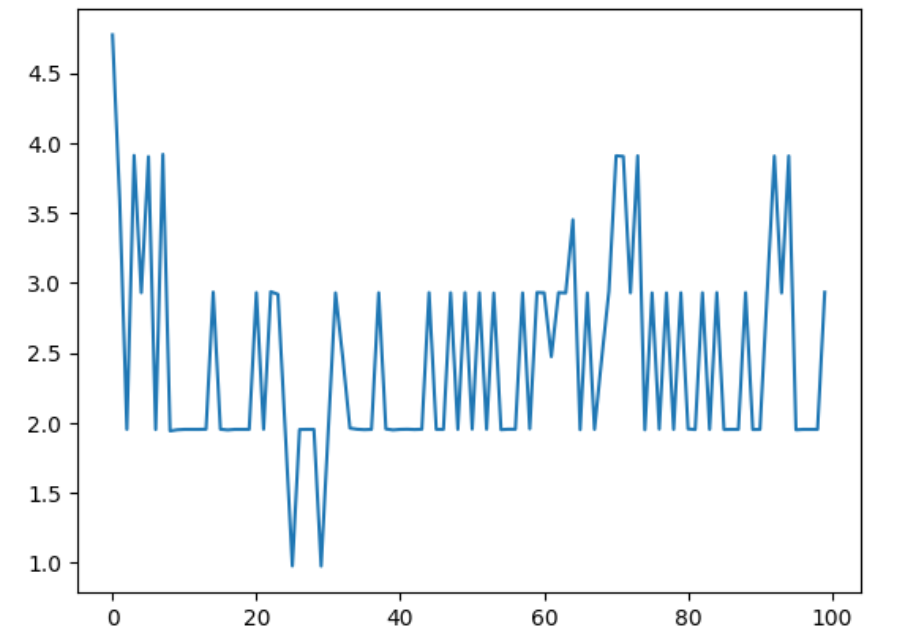
测速1000次
import matplotlib.pyplot as plt
import datetime
tims = []
with torch.no_grad():
for i in range(1000):
start_time = datetime.datetime.now() # 记录程序开始时间
y=model(X=index)
end_time = datetime.datetime.now() # 记录程序结束时间
tim = (end_time - start_time)
tims.append(tim.total_seconds() *1000)
plt.plot(tims)
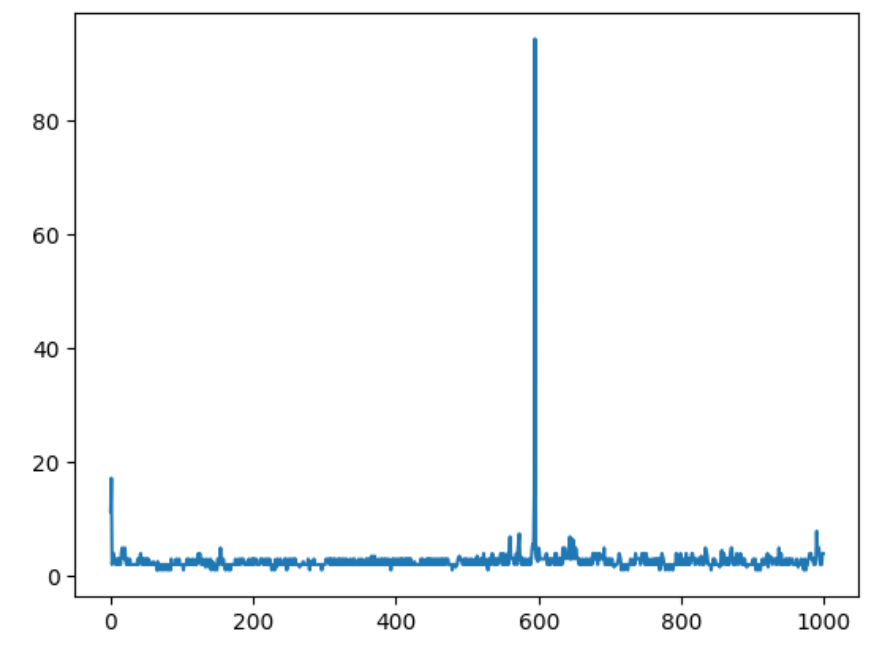
测速10000次
import matplotlib.pyplot as plt
import datetime
tims = []
with torch.no_grad():
for i in range(10000):
start_time = datetime.datetime.now() # 记录程序开始时间
y=model(X=index)
end_time = datetime.datetime.now() # 记录程序结束时间
tim = (end_time - start_time)
tims.append(tim.total_seconds() *1000)
plt.plot(tims)
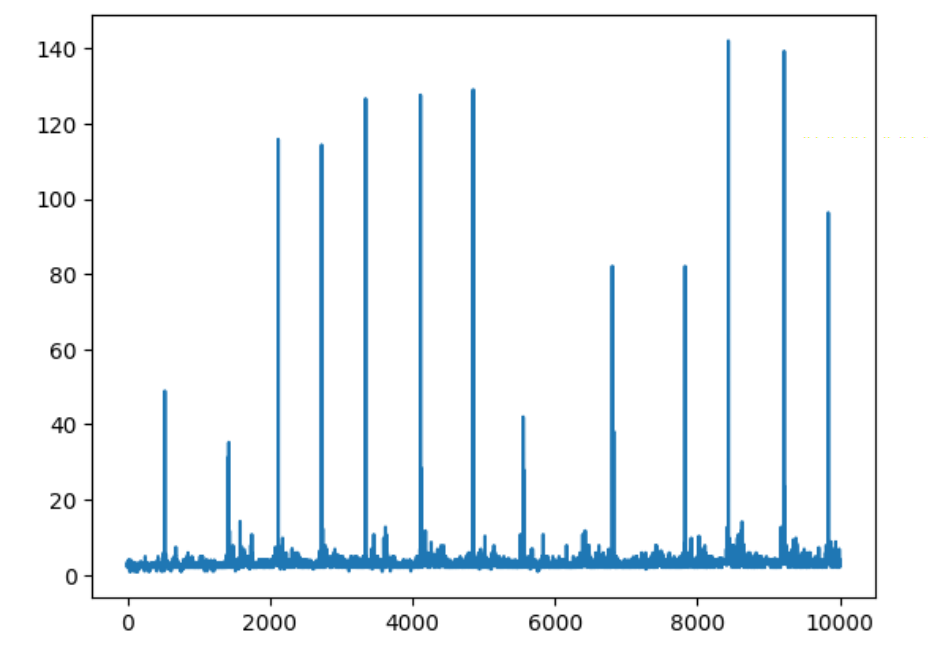
参考
如何在Python中测量程序运行时间