总体流程图
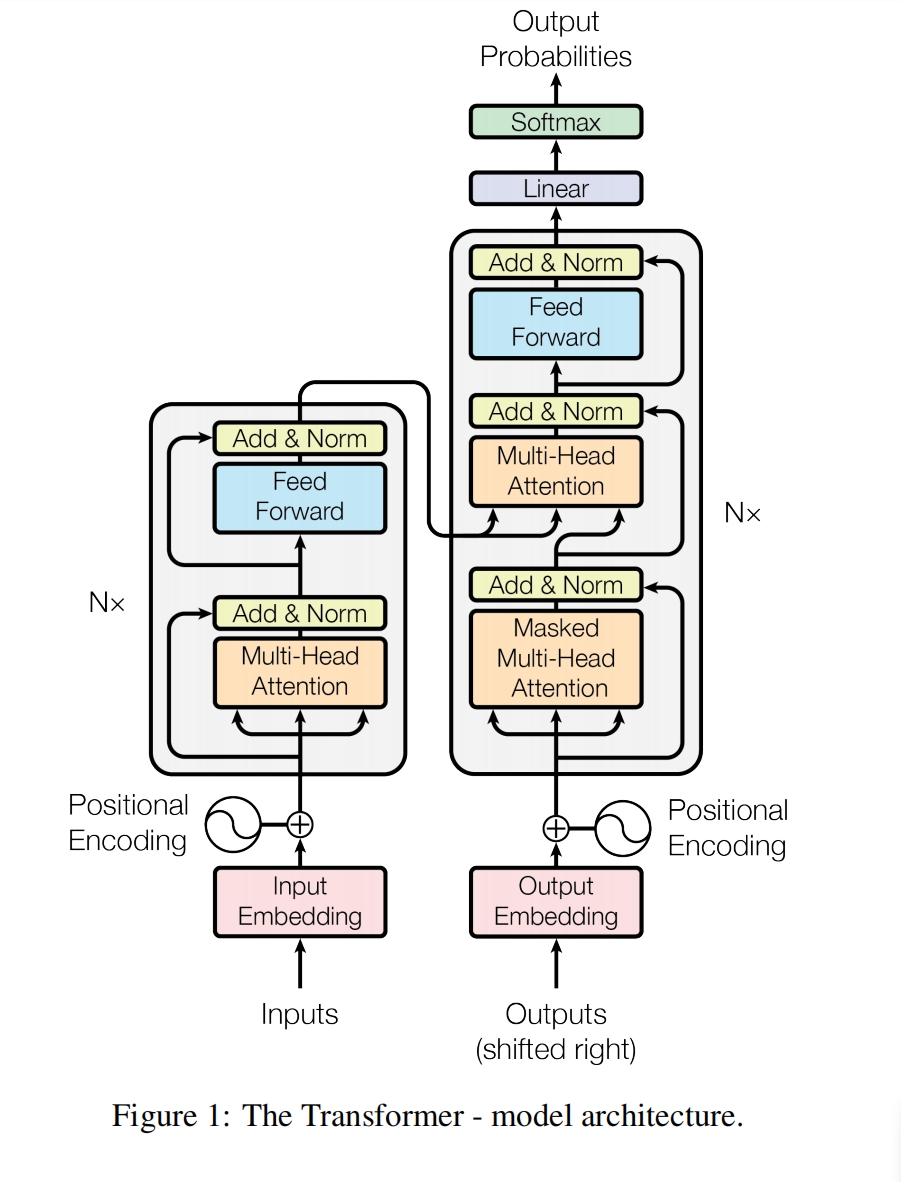
|
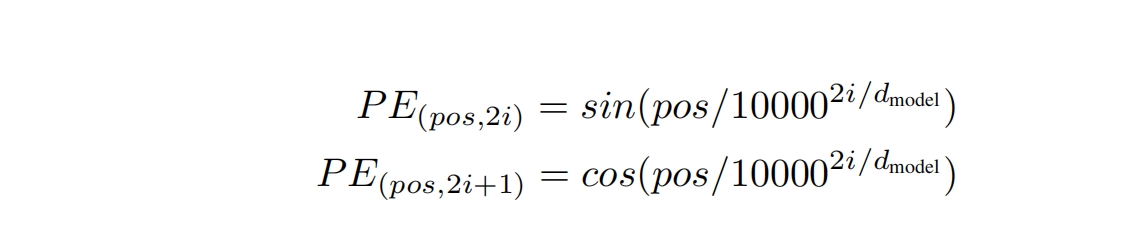
加入周期性变化的位置信息 L 一句话中有多少个单词, pos 表示第几个单词,范围[0,L-1],pos为单词在句子中的位置 单词向量的维度为embedding_dim,i属于[0,embedding_dim-1] i 表示向量维度的位置,第几维 transformer网络中向量特征个数通常是固定的,比如512维 每个小区域会从512变大,但最后小区域结束时,会收缩到512维, 然后不断地循环重复这一系列的小区域, 参数在网络中的特征变化为,在某个特定的维度附近,一张一收,循环往复 这个固定的维度就是d 优点/作用
可以处理任何⻓度的序列:
- 因为编码是通过函数⽣成的,所以理论上可以为任何⻓度的序列⽣成位置编码。
可以捕捉相对位置信息:
- 这种编码⽅式能够让模型捕捉词与其周围词之间的相对位置关系。
可以轻易加到词向量上:
- 这些编码是添加到词嵌⼊向量上的,⽽不是与之相乘,这样简化了模型。
这种位置编码⽅法为模型提供了词在序列中相对位置的信息,
这对于许多NLP任务(如翻译、摘要等)来说是⾮常有⽤的。
下面的部分为个人猜测,如有雷同,纯属巧合
参数在网络中的特征变化为,在某个特定的维度附近,一张一收,循环往复
特别像跳动的音符,音乐播放时那个在一定范围内跳动的曲线,
但语音通常有五个主峰频率,但tranformer的model维度通常一个,d=512,
个人猜测,tranformer后续要想有更强大的表征能力,
这个model维度也应该能够随数据规律而增加/变化才是
|
生成模式 解码训练是一个序列生成一个单词,然后再生成下一个,是一上下三角矩阵 |
解码器X提供KV,解码器为Q X是整个解码器的最终输出 y则是解码器每个小模块(注意力+残差+归一化)的输入 即解码器所有小模块 共用同一个x |
注意力是求特征的,残差是解决梯度消失问题的,整个小模块就是为了能够多次循环求特征 前馈神经网络,线性变换+激活函数,是为了特征变换,将一个维度的特征映射到另外一个维度 注意力中是没有激活函数的,是纯线性变换,且不注重特征在不同维度的变换, 注意力的线性变换是模型维度d的变换, 要求的是相对重要性,侧重于百分比,概率的计算,再与V相乘,化为具体的值 注意力是要分个高下,称一称到底几斤几两,划分成三六九等, 让差异清晰明了...这样方便后续特征变换 其实这就是一个评分模型,通常内积/相似度运算,让重要维度上的数值/评分 大/高一点 前馈神经网络的特征变换,是不同维度的变换 通常是模型维度d -- 2d/4d -- 模型维度d,是有一个一张一收的过程的 特征维度先大后小,这也是神经网络特征变换的一个基本思想 所以,这里的神经网络通常是两层, 一层将特征维度变大,一层将之收缩回来,每层+一个激活函数 |
参考