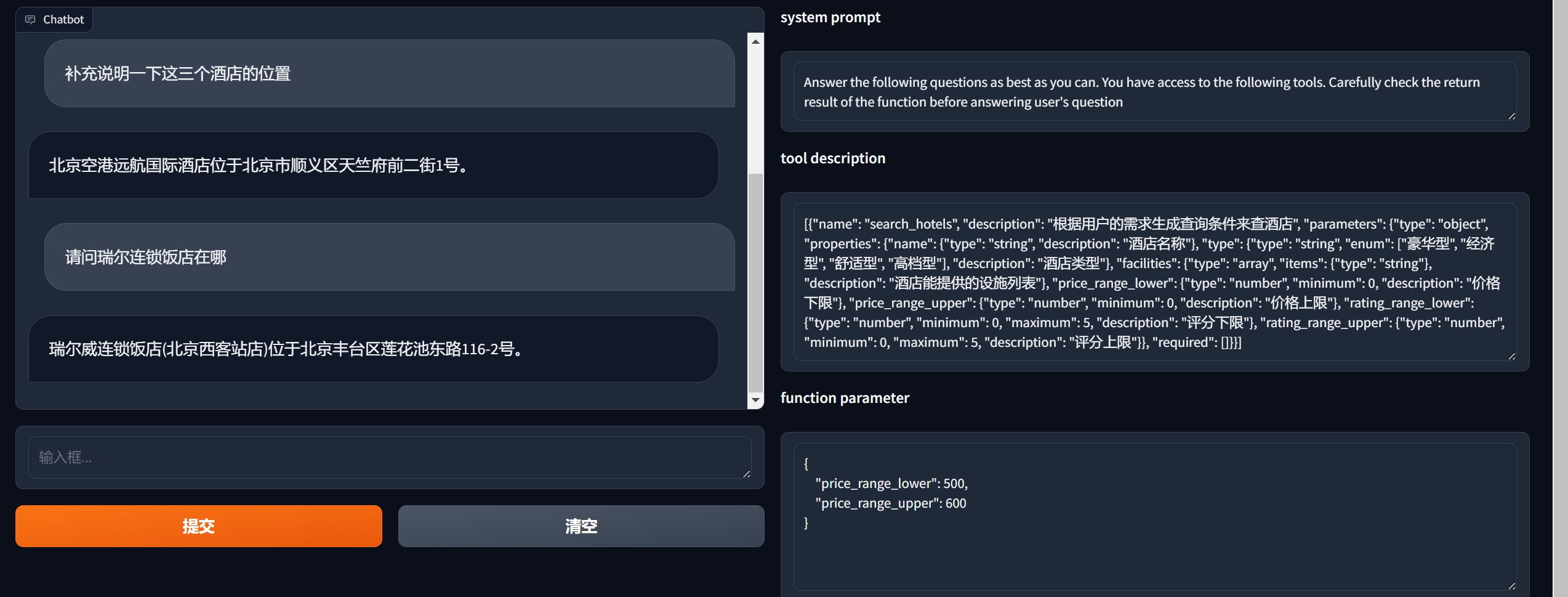
微调方法
标签数据微调、基于特征的微调、蒸馏、基于适配器的微调、提示语微调
标签数据微调:准备自己的打好标签的训练数据,再次训练大模型;
特征微调:
在冻结现有大模型网络参数的基础上,添加一些自己的代码,
可以是添加新的网络结构,或者是在原矩阵的基础上拼接一段自己的矩阵,
重新训练时只改变自己新加的参数,不改变原大模型的参数;
蒸馏:向大模型提问,得到答案,形成训练集,来训练自己的小模型
适配器微调:不改变大模型参数,针对某个场景进行的特征微调,场景不同,适配器不同;
提示词微调:
自然语言的细化,说成大模型能理解的语言,
主要特点是,根据语义不断拆分细化,把大模型当作“一个完全不明白你意思的 人”,
最好是一句话只包括一个不可再拆分的语义,所有潜台词隐含的意思全部转换为明明白白的文字,
这样大模型就能更好地理解你的意思
GPT-3.5-Turbo微调:除了前面通用的微调方法,这是还支持JSON输入
|
微调方法有多种,这是指实际能解决问题的方法,
但实际上,普通人问你会不会微调指的是 会不会调整大模型的参数
- 隐含的期望是你能不能在垂直领域训练一个好用,免费,公司自己的大模型
暂时不说怎么调整参数,但调完参数之后,必须得重新训练,这有两个问题
- 模型训练,这是算法工程师该干的事,涉及大量算法类别的基础知识,虽然不难,但...那是算法层次的
- 效果,微调之后的效果通常不好,大模型重新训练的代价非常之大,并且最后很可能会面临一个较差的效果
- 为什么会这样呢?因为它破坏了原大模型的参数结构
- 原结构下效果是好的,否则也不好意思拿出来,
- 但结构改变之后,是好是坏不好说,通常是坏的
- 最不能破坏的是LLM的语义理解能力
-
所以,你最好得会深度学习算法的一些基础
吴恩达讲AI
https://www.zhihu.com/education/video-course/1556316449043668992
李沐讲深度学习
https://www.zhihu.com/education/video-course/1647604835598092705
微调的场景 如果不是极其特殊的场景,那么就不需要微调了 3版本以上的LLM都具有解决问题的能力 如果一个场景真的非常特殊,通用的能力真的无法满足业务场景,可以微调 - 微调之后,增加了处理特殊场景的能力 - 损失了一部分通用场景的能力 微调
输出的格式,风格
- 如果你感觉现在的对话风格比较生硬,想口语化一些
- 口语化的过程,也是让LLM做的,抽取出来,口语化,再替换回去
- 开头与结束再加一些友好的问候语
- 意思是,在数据上补充了这个能力,
- 放回去的时候,有时候,上下文不连贯,再让LLM对其处理一下,使之连贯起来
补充多轮对话
- 原来只有单轮对话,这样的数据训练出来的模型,多轮对话能力就比较弱,或者说是无法预期
- 需要补充多轮对话进去,进行训练
同义词处理
- 简称,缩写,口语化的指代等等,这些数据也补充进去
- 如果原始数据中没有这些,那么用这些数据训练出来的模型,
- 就无法将口语化简化的叫法与实际的名称对应起来
边界处理
- 有些特征是有范围的,比如价格,要举例让模型学习这些边界
RNN, CNN, 注意力,transformer,NLP,transformer,
chatglm微调示例
https://github.com/THUDM/ChatGLM3/blob/main/finetune_demo/finetune_hf.py
tool 拼接的早期版本
https://github.com/THUDM/ChatGLM3/blob/4568c635e686e8e2053568d041f36c884cab328a/finetune_demo/preprocess_utils.py
|
root@llm:~# pip install peft
PEFT
大模型PEFT的全称是Parameter-Efficient Fine-Tuning,即参数高效微调。
这是一种针对大型预训练模型(如LLM模型)的微调技术,由Hugging Face开源。
PEFT可以在不微调模型所有参数的情况下,
通过微调少量参数就达到接近微调全量参数的效果,
使得在GPU资源不足的情况下也可以微调大模型。
PEFT集成了多种微调大模型的方法,如
Prefix Tuning(前缀微调)、
Adapter Tuning(适配器微调)、
LoRA(Low-Rank Adaptation,低秩适应)等,这些方法各有特点,
但共同之处在于它们都能以较小的参数调整量实现较好的模型性能提升。
具体来说,PEFT的应用场景包括但不限于:
序列分类任务:如文本分类、情感分析等。
标记分类任务:如命名实体识别、词性标注等。
文本生成任务:如机器翻译、文本摘要等。
http://www.huggingface.co 模型库,常见模型,尤其是transformer系列 # pip安装 pip install requests pip install datasets #huggingface pip install transformers # 安装最新的版本 pip install transformers==4.30 # 安装指定版本 # conda安装 conda install -c huggingface transformers # 只4.0以后的版本 |
from peft import get_peft_model, LoraConfig, TaskType, PeftModel
def load_lora_model(model_args, peft_args):
# 加载预训练的chatglm3-6b的tokenizer和model
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
model = model.half()
# 使用peft库配置lora参数
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=peft_args.lora_rank,
lora_alpha=peft_args.lora_alpha,
lora_dropout=peft_args.lora_dropout,
target_modules=["query_key_value"],
)
model = get_peft_model(model, peft_config).to("cuda")
model.enable_input_require_grads()
model.is_parallelizable = True
model.model_parallel = True
model.config.use_cache = False
return tokenizer, model
# 使用peft库配置lora参数
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=peft_args.lora_rank,
lora_alpha=peft_args.lora_alpha,
lora_dropout=peft_args.lora_dropout,
target_modules=["query_key_value"],
)
r=peft_args.lora_rank,
设置秩的大小,8,16
lora_alpha=peft_args.lora_alpha,
超参数,一般是32,64
lora_dropout=peft_args.lora_dropout,
填写dropout函数舍弃的概率值,通常不超过0.5
target_modules=["query_key_value"],
query_key_value表示在QKV上都加,加上那两个低秩矩阵相乘后的矩阵
model = get_peft_model(model, peft_config).to("cuda")
get_peft_model把配置注入了模型,实际上分以下几步
- 从模型中取出现有参数
- 把低秩矩阵相乘后的矩阵参数加到模型参数上
- 让模型重新加载新参数并返回模型
- 需要注意的是
- 重新训练时,原模型的参数是不变的,被冻结
- 每次变化的是低秩矩阵的参数
- 相乘以后,加到原模型参数上,使最终结果发生微小变化
- 这就是LoRA微调,是轻量级微调一个常用方法
task_type=TaskType.CAUSAL_LM: 这个参数指定了任务类型。TaskType.CAUSAL_LM表示这是一个因果语言模型(Causal Language Model)任务,也就是通常所说的自回归语言模型(Autoregressive Language Model)。这种模型会根据前面的文本生成接下来的文本,如GPT系列模型。 inference_mode=False: 这个参数通常用于控制模型是否处于推理模式。False表示当前配置不是为推理而设置的,可能是为了训练或微调。在推理模式下,模型可能会关闭某些仅在训练时需要的特性,如dropout等,以提高推理速度和效率。 r=peft_args.lora_rank: r参数是LoRA技术的核心之一,它表示低秩矩阵的秩(rank)。LoRA通过在预训练模型的某些层上添加可训练的低秩矩阵来实现参数高效的微调。秩的大小控制了这些低秩矩阵的复杂度,从而影响了模型的表达能力和微调所需的计算资源。peft_args.lora_rank是从某个参数集合(可能是命令行参数、配置文件等)中获取的秩的值。 lora_alpha=peft_args.lora_alpha: lora_alpha是LoRA微调中的一个超参数,用于控制低秩矩阵对原始模型参数的影响程度。 它通常是一个标量,用于缩放低秩矩阵的权重。 较大的alpha值会使低秩矩阵对模型的影响更大,反之亦然。 peft_args.lora_alpha是从参数集合中获取的alpha的值。 lora_dropout=peft_args.lora_dropout: lora_dropout是一个可选参数,用于在LoRA微调过程中应用dropout。 Dropout是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出来减少模型的过拟合。 在LoRA微调中,虽然主要目标是微调低秩矩阵, 但也可以在低秩矩阵的权重上应用dropout来进一步增加模型的泛化能力。 peft_args.lora_dropout是从参数集合中获取的dropout率。 target_modules=["query_key_value"]: target_modules参数指定了LoRA微调将应用于哪些模型组件。 在这个例子中,它设置为["query_key_value"], 这通常意味着LoRA微调将应用于Transformer模型中的查询(query)、键(key)和值(value)矩阵。 这些矩阵是Transformer模型中自注意力机制的核心部分,对于模型的性能至关重要。 通过在这些矩阵上应用LoRA微调,可以在不改变预训练模型大部分参数的情况下, 针对特定任务对模型进行定制和优化。 |
|
|
|
|
数据集
|
数据集
汉语对话:酒店,餐饮,打车,地铁等跨领域对话
https://github.com/thu-coai/CrossWOZ
其中的酒店预订部分
https://github.com/thu-coai/CrossWOZ/blob/master/data/crosswoz/database/hotel_db.json
数据增强 针对同一个事物/问题,不同风格的提问 - 客观,死板 - 口语,灵活 这套数据集,是人编写的,按指定格式编写的,对原生的对话进行了整理 - 但就对话而言,是分场景,语气,地域风格的, - 所以,当不同的人/群体使用时,可能还需要补充 其实就是系统性,全方位,全场景覆盖,如果哪个地方没有覆盖到,就可能在哪个地方出问题 所以,关于LLM知识缺陷的补充,已经开始由测试团队负责了, 这正是测试团队的日常工作,由测试团队测试出系统的缺陷,由开发团队完善补充, 然后不断重试这个过程 参考代码 data_augmentation augmentation 英/ˌɔːgmɛnˈteɪʃ(ə)n/ 美/ˌɑgmɛnˈteɪʃən/ n.增强;扩大;增加;增长;加强;提高
|
|
|
|
|
|
|
|
容器构建
chatglm3和llama3的权重下载命令脚本
训好的checkpoints
训练所需的数据集和代码
ssh -p 10024 root@connect.westb.seetacloud.com rsync -e 'ssh -p10024' -avP root@connect.westb.seetacloud.com:/root/autodl-tmp /root/ rsync -e 'ssh -p10024' -avP root@connect.westb.seetacloud.com:/root/miniconda3 /root/ EFJLX0etnAwc sudo apt update sudo apt install less PATH=/root/miniconda3/bin:/usr/local/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin export REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt # cat init_env.sh #! /usr/bin/env bash echo "拷贝checkpoint到数据盘" cp -r /root/checkpoints /root/autodl-tmp echo "完成" cd /root/autodl-tmp echo "开始从modelscope拉取模型预训练权重" echo "下载chatglm3-6b权重,预计十几分钟" git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git cd chatglm3-6b/ git checkout a8079d5ed73707fb7d5aadc4a0da70771c4e7bdb git lfs fetch --include="tokenizer.model" git lfs checkout tokenizer.model git lfs fetch --include="*.bin" git lfs checkout *.bin rm -rf .git # 清除掉.git目录,避免数据盘空间不足 cd /root/autodl-tmp/ echo "下载llama3-8b权重,预计十几分钟" git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git cd Meta-Llama-3-8B-Instruct rm -rf .git # 清除掉.git目录,避免数据盘空间不足 cd /root/autodl-tmp/ echo "完成" echo "从github拉取finetune代码,如网络不稳定导致拉取失败,可以手动重复尝试:" echo "git clone https://mirror.ghproxy.com/https://github.com/agiclass/fine-tuning-lab -b v6" # 进入finetune代码目录中,拉取一下最新代码 cd /root/autodl-tmp/ git clone https://mirror.ghproxy.com/https://github.com/agiclass/fine-tuning-lab -b v6 echo "已准备就绪,可以开始做训练实验或运行webui demo了" finetune的代码托管在github上,大家可以去同步拉取(也欢迎大家来star噢), 地址是 https://github.com/agiclass/fine-tuning-lab 代码在 v6 分支上。 从github拉取finetune代码,如网络不稳定导致拉取失败,可以手动重复尝试 ```bash cd /root/autodl-tmp/ # 如果网络不畅通可以使用ghproxy来代理从github同步代码 # 或从实验室中拿到的已打包好的代码包然后手动传到autodl服务器上 git clone https://mirror.ghproxy.com/https://github.com/agiclass/fine-tuning-lab -b v6 ``` 然后到web demo的目录加载并运行模型 ```bash cd /root/autodl-tmp/fine-tuning-lab/web_demo/ bash chatglm3_lora.sh ## 其他的也是同理 # bash chatglm3_origin.sh # bash chatglm3_pt2.sh # bash llama3_qlora.sh ``` 实验指导 http://127.0.0.1:8888/notebooks/lecture-notes/14-fine-tuning-02/lab/index.ipynb |
|
web调试 cd /root/autodl-tmp/fine-tuning-lab/web_demo/ bash chatglm3_lora.sh ## 其他的也是同理 # bash chatglm3_origin.sh # bash chatglm3_pt2.sh # bash llama3_qlora.sh ----------------------------------------------------------------------------- cp chatglm3_lora.sh chatglm3_lora2.sh /root/autodl-tmp/fine-tuning-lab/chatglm3/output/hotel_lora-20240728-124303/checkpoint-3000 # cat chatglm3_lora2.sh #!/bin/bash MODEL_DIR="/root/autodl-tmp/chatglm3-6b" CHECKPOINT_DIR="/root/autodl-tmp/fine-tuning-lab/chatglm3/output/hotel_lora-20240728-124303/checkpoint-3000" CUDA_VISIBLE_DEVICES=0 python webui_chatglm3.py \ --model_name_or_path $MODEL_DIR \ --checkpoint_path $CHECKPOINT_DIR \ --lora_rank 8 \ --lora_alpha 32 \ --lora_dropout 0.1 ./chatglm3_lora2.sh 将服务的端口映射到指定6006上 
若上面的方法无法使用,则尝试下面的方法 # 比如上一步从autodl控制台上复制下来的ssh命令是: # ssh -p 17844 root@connect.westb.seetacloud.com # 则这一步在前面加上 -L 6006:localhost:6006 # !!! 注意把这里的地址和端口换成你自己的 !!! ssh -L 6006:localhost:6006 -p 17844 root@connect.westb.seetacloud.com 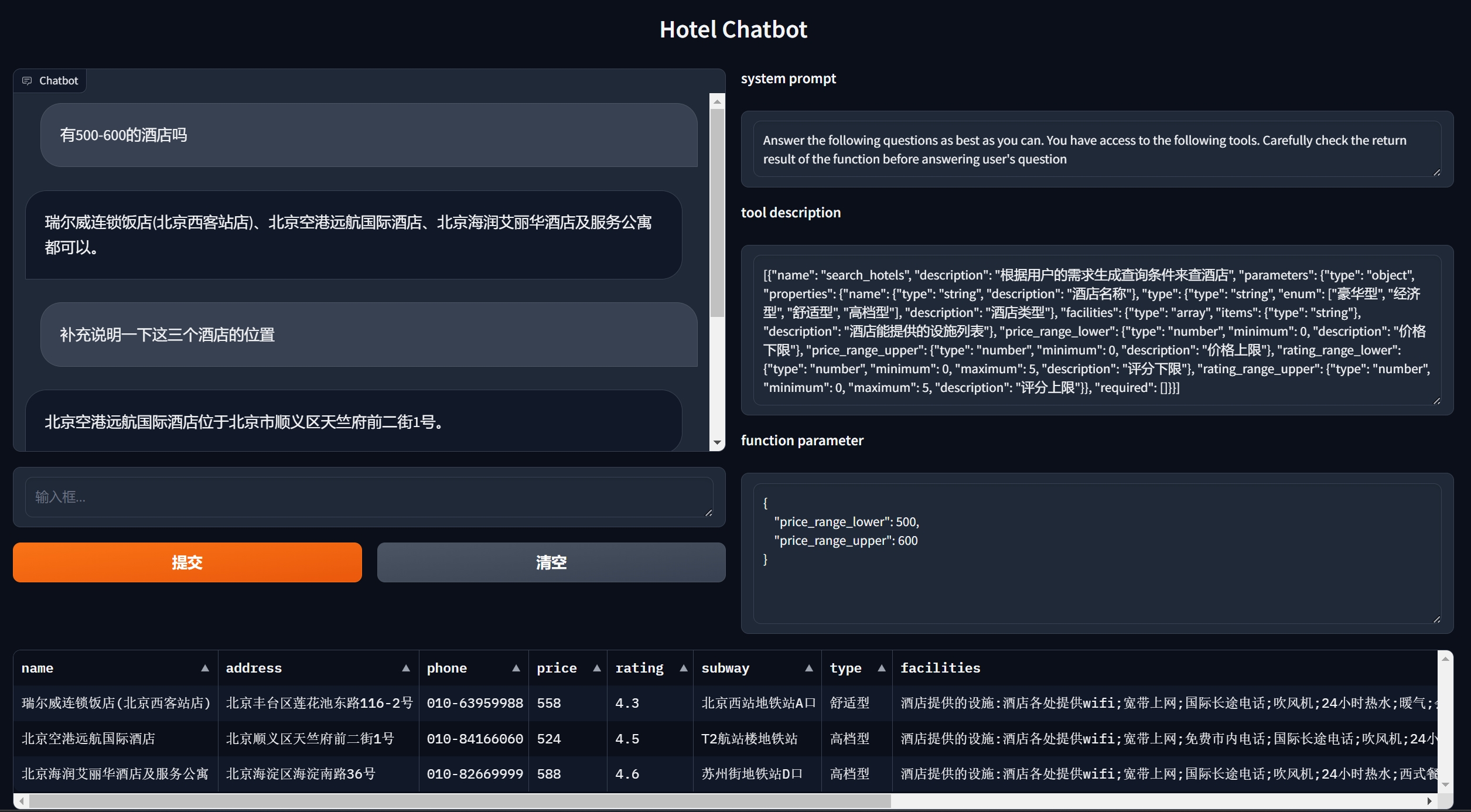
|
数据目录 fine-tuning-lab/data cd chatglm3 sh lora_train.sh ## 训练pt2方式同理 # sh pt2_train.sh nohup ./lora_train.sh > /tmp/train.log 2 > &1 & 会在当前目录创建一个output目录,最终模型输出到这里面 0%| | 7/3204 [00:17 < 2:08:32, 2.41s/it] 微调之后: 参数调整后,输出的路径可能会改变。可以去 fine-tuning-lab/chatglm3 目录里面的 output 目录下查看,里面是训练后的模型。 然后修改 chatglm3_lora.sh 里面的 CHECKPOINT_DIR,指向你想加载的训练后模型。 AutoDL服务器在国内,如果需要访问外网: source /etc/network_turbo |
|
checkpoint-nnn 是训练过程中的中间结果,nnn 数字最大的那个是最终结果 chatglm3/output/hotel_lora-20240728-124303# ls -ltrh total 8.8M drwxr-xr-x 2 root root 301 Jul 28 13:03 checkpoint-300 drwxr-xr-x 2 root root 301 Jul 28 13:23 checkpoint-600 drwxr-xr-x 2 root root 301 Jul 28 13:43 checkpoint-900 drwxr-xr-x 2 root root 301 Jul 28 14:03 checkpoint-1200 drwxr-xr-x 2 root root 301 Jul 28 14:23 checkpoint-1500 drwxr-xr-x 2 root root 301 Jul 28 14:43 checkpoint-1800 drwxr-xr-x 2 root root 301 Jul 28 15:04 checkpoint-2100 drwxr-xr-x 2 root root 301 Jul 28 15:24 checkpoint-2400 drwxr-xr-x 2 root root 301 Jul 28 15:44 checkpoint-2700 drwxr-xr-x 2 root root 301 Jul 28 16:04 checkpoint-3000 -rw-r--r-- 1 root root 460 Jul 28 16:12 tokenizer_config.json -rw-r--r-- 1 root root 12K Jul 28 16:12 tokenization_chatglm.py -rw-r--r-- 1 root root 3 Jul 28 16:12 special_tokens_map.json -rw-r--r-- 1 root root 7.5M Jul 28 16:12 pytorch_model.bin -rw-r--r-- 1 root root 4.9K Jul 28 16:12 training_args.bin -rw-r--r-- 1 root root 4.2K Jul 28 16:12 trainer_state.json -rw-r--r-- 1 root root 995K Jul 28 16:12 tokenizer.model -rw-r--r-- 1 root root 300K Jul 28 16:20 train.log drwxr-xr-x 2 root root 182 Jul 28 16:20 logs /root/autodl-tmp/fine-tuning-lab/chatglm3/output/hotel_lora-20240728-124303/checkpoint-3000 /root/autodl-tmp/fine-tuning-lab/chatglm3/output/hotel_lora-20240728-124303/checkpoint-3000 # ls optimizer.pt rng_state.pth special_tokens_map.json tokenizer.model trainer_state.json pytorch_model.bin scheduler.pt tokenization_chatglm.py tokenizer_config.json training_args.bin cp lora_eval.sh lora_eval2.sh # cat lora_eval2.sh #! /usr/bin/env bash MODEL_DIR="/root/autodl-tmp/chatglm3-6b" CHECKPOINT_DIR="/root/autodl-tmp/fine-tuning-lab/chatglm3/output/hotel_lora-20240728-124303/checkpoint-3000" CUDA_VISIBLE_DEVICES=0 python cli_evaluate.py \ --test_file ../data/test.chatglm3.jsonl \ --model_name_or_path $MODEL_DIR \ --checkpoint_path $CHECKPOINT_DIR \ --lora_rank 8 \ --lora_alpha 32 \ --lora_dropout 0.1
chatglm3# ./lora_eval2.sh
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]/root/miniconda3/envs/agiclass/lib/python3.11/site-packages/torch/_utils.py:831: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:01<00:00, 4.47it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 201/201 [09:13<00:00, 2.75s/it]
score dict: {'slot_P': 94.9097, 'slot_R': 92.926, 'slot_F1': 93.9074, 'bleu-4': 65.3169}
slot_P (Precision, 精确率):
精确率衡量的是模型预测为正类的样本中,真正为正类的样本所占的比例。在命名实体识别或类似的任务中,它表示模型预测出的所有命名实体中,真正属于命名实体的比例。高精确率意味着模型预测结果中,误报(将非命名实体预测为命名实体)的情况较少。
计算公式为:精确率 = 真正例(TP) / (真正例(TP) + 假正例(FP))
slot_R (Recall, 召回率):
召回率衡量的是在所有实际为正类的样本中,被模型正确预测为正类的样本所占的比例。在命名实体识别任务中,它表示在所有真实的命名实体中,模型成功识别出的命名实体的比例。高召回率意味着模型能够找到大多数真实的命名实体,但可能会以牺牲精确率为代价。
计算公式为:召回率 = 真正例(TP) / (真正例(TP) + 假负例(FN))
slot_F1 (F1 Score, F1分数):
F1分数是精确率和召回率的调和平均数,用于综合评估模型的性能。它是精确率和召回率的加权平均值,给予了两者相同的权重。F1分数越高,说明模型的性能越好,即模型在精确率和召回率之间取得了良好的平衡。
计算公式为:F1 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
bleu-4 (BLEU Score, 4-gram Bilingual Evaluation Understudy):
BLEU分数是一种评估机器翻译文本质量的指标,
但也可以用于评估其他文本生成任务(如摘要、对话生成等)的输出质量。
BLEU分数通过计算生成文本与参考文本之间的n-gram(这里是4-gram)共现程度来评估文本的流畅度和准确性。
较高的BLEU分数表示生成文本与参考文本更相似,但需要注意的是,BLEU分数并不完美,它可能无法完全反映生成文本的质量,尤其是当参考文本有多个可能的正确翻译时。
BLEU分数的计算涉及多个步骤,包括计算n-gram的精确度、长度惩罚等。
总结来说,这些指标共同提供了模型在命名实体识别或文本生成任务中性能的全面评估。
高精确率、高召回率和高F1分数通常意味着模型在识别命名实体或生成文本方面表现良好,
而较高的BLEU分数则表明生成的文本与参考文本相似度较高。
|
训练
|
GLM中gradient_accumulation_steps参数
在大模型GLM中,gradient_accumulation_steps参数是一个关键的训练参数,
它指的是在反向传播算法中,每隔多少个batch(或称为mini-batch)会更新一次模型的参数。
传统的反向传播算法会在每个batch更新一次参数,
但使用gradient_accumulation_steps参数可以将多个batch的梯度累积起来,再进行一次参数更新。
这一参数的设置对模型的训练过程有显著影响,主要体现在以下几个方面:
节省显存使用:
在GPU训练深度学习模型时,显存的容量是有限的。
当batch size较大时,一次性将所有的样本放入内存中可能会导致显存溢出。
通过梯度累积,可以将一个大的batch分成若干个小的mini-batch,在每个mini-batch上计算梯度并累积,
从而减少了一次性加载大batch所需的显存。这对于显存容量较小的设备来说尤为重要。
减小梯度更新的频率:在深度学习中,梯度更新的频率会影响模型的收敛速度和稳定性。
如果在每个batch都更新参数,可能会因为噪声导致模型收敛变慢或者发散。
而梯度累积可以将多个batch的梯度进行平均,从而减小变化的幅度,使得模型更加稳定。
处理样本不平衡问题:在一些实际应用中,数据集中的不同类别的样本数量可能存在很大的差异。
如果不平衡的样本在同一个mini-batch中,可能导致模型偏向于多数样本类别。
使用梯度累积的方法可以将不同mini-batch中的样本混合起来,从而更好地平衡不同类别的样本。
然而,gradient_accumulation_steps参数的选择也需要进行调优。
过小的gradient_accumulation_steps会导致梯度的更新频率过高,容易出现收敛不稳定的情况;
而过大的gradient_accumulation_steps则会导致梯度的更新频率过低,可能会增加模型的收敛时间。
因此,在实际应用中,需要根据具体的问题和硬件平台来选择合适的gradient_accumulation_steps参数值,
以达到更好的模型性能和收敛效果。
综上所述,gradient_accumulation_steps参数在大模型GLM的训练中扮演着重要的角色,
它通过累积多个batch的梯度来更新模型参数,从而节省显存使用、减小梯度更新的频率,
并有助于处理样本不平衡问题。
在大模型GLM中,gradient_accumulation_steps参数的具体设置值并不是一个固定的数字,而是需要根据具体的训练任务、硬件资源、数据集大小以及模型复杂度等多种因素来确定的。这个参数的主要作用是控制梯度累积的步数,即在多少个mini-batch的梯度计算完成后,进行一次模型参数的更新。
设置gradient_accumulation_steps的考虑因素:
硬件资源:
GPU显存:如果GPU显存有限,但希望使用较大的batch size来提高训练稳定性或加速训练过程,
可以通过增加gradient_accumulation_steps来实现。
这样可以将大batch分割成多个小mini-batch,逐步累积梯度,
从而在不增加显存负担的情况下模拟大batch的效果。
计算性能:虽然梯度累积可以减少显存使用,
但它也会增加训练的总步数(即需要处理更多的mini-batch),
这可能会增加总的训练时间。
因此,在设置时需要权衡计算性能和显存使用之间的平衡。
数据集大小:
数据集的总大小和每个mini-batch的大小将影响gradient_accumulation_steps的设置。
如果数据集很大,但每个mini-batch的大小较小,
那么可能需要设置较大的gradient_accumulation_steps来确保每次更新都使用了足够多的数据。
模型复杂度:
复杂的模型通常需要更多的数据来训练,
因此可能需要设置较大的gradient_accumulation_steps来确保每次更新都使用了足够的梯度信息。
训练稳定性和收敛速度:
较小的gradient_accumulation_steps值(即更频繁的参数更新)可能会导致模型收敛速度更快,
但也可能增加训练过程中的不稳定性。
相反,较大的值可以提高稳定性,但可能会减慢收敛速度。
示例和实际操作:
在实际操作中,通常会通过试验不同的gradient_accumulation_steps值来找到最优的设置。
这可以通过观察训练过程中的损失函数值、验证集上的性能指标以及训练时间等来进行评估。
例如,如果原始batch size为32,但由于显存限制无法直接设置,
可以将其减小为16或8,
并通过设置gradient_accumulation_steps=2或gradient_accumulation_steps=4
来模拟原始的batch size效果。
这样可以在不增加显存负担的情况下,保持或接近原有的训练稳定性和收敛速度。
结论:
因此,在大模型GLM中,gradient_accumulation_steps参数的具体设置值
是一个需要根据具体情况进行调优的超参数。
没有一个固定的值适用于所有情况,而是需要通过实验和评估来确定最优的设置。
|
#! /usr/bin/env bash
set -ex
LR=2e-4
MAX_SEQ_LEN=3072
DATESTR=`date +%Y%m%d-%H%M%S`
RUN_NAME=hotel_lora
OUTPUT_DIR=output/${RUN_NAME}-${DATESTR}
mkdir -p $OUTPUT_DIR
BASE_MODEL_PATH=/root/autodl-tmp/chatglm3-6b
CUDA_VISIBLE_DEVICES=0 python main_lora.py \
--do_train \
--do_eval \
--train_file ../data/train.chatglm3.jsonl \
--validation_file ../data/dev.chatglm3.jsonl \
--max_seq_length $MAX_SEQ_LEN \
--preprocessing_num_workers 1 \
--model_name_or_path $BASE_MODEL_PATH \
--output_dir $OUTPUT_DIR \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 2 \
--per_device_eval_batch_size 2 \
--num_train_epochs 4 \
--evaluation_strategy steps \
--eval_steps 300 \
--logging_steps 300 \
--logging_dir $OUTPUT_DIR/logs \
--save_steps 300 \
--learning_rate $LR \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout 0.1 2>&1 | tee ${OUTPUT_DIR}/train.log
--per_device_train_batch_size 1 每个GPU上放一个批次
--gradient_accumulation_steps 2 每隔2个批次更新一次梯度
也就是说GPU的个数*per_device_train_batch_size*gradient_accumulation_steps
才是真正意义上的一个批次
|
|
|
|
|
|
|
llama3微调
|
使用peft进行量化
import json
import torch
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
DataCollatorForSeq2Seq,
HfArgumentParser,
TrainingArguments,
Trainer
)
from peft import LoraConfig, TaskType, get_peft_model
from arguments import ModelArguments, DataTrainingArguments, PeftArguments
from data_preprocess import InputOutputDataset
def load_model(model_name):
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
n_gpus = torch.cuda.device_count()
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto", # dispatch efficiently the model on the available ressources
max_memory = {i: '24400MB' for i in range(n_gpus)},
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
bnb_4bit_quant_type="nf4", 4bit量化,按4bit的格式加载模型
|
将LoRA的配置注入模型
model, tokenizer = load_model(model_args.model_name_or_path)
model = get_peft_model(model, lora_config)
#数据规整器
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
padding=True
)
#获取训练集与测试集
if training_args.do_train:
#定义训练器
trainer = Trainer(
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
)
#训练
if training_args.do_train:
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
trainer.train()
#预测
if training_args.do_eval:
trainer.evaluate()
|
# ./lora_eval.sh
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████| 4/4 [00:07<00:00, 1.92s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
100%|███████████████████████████████████████████████████████████████████████████████████████| 560/560 [22:18<00:00, 2.39s/it]
score dict: {'slot_P': 93.6378, 'slot_R': 92.283, 'slot_F1': 92.9555, 'bleu-4': 64.0666}
slot_P (Slot Precision, 槽位精确度) 
slot_R (Slot Recall, 槽位召回率) 

bleu:文本相似度 使用peft将训练好的checkpoint注入模型
import json
import torch
import argparse
from tqdm import tqdm
from peft import PeftModel
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from data_preprocess import build_prompt, parse_json
def load_model(model_name, checkpoint):
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
n_gpus = torch.cuda.device_count()
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
max_memory = {i: '24500MB' for i in range(n_gpus)},
)
model = PeftModel.from_pretrained(model, model_id=checkpoint)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
template = build_prompt(item["context"])
input_ids = self.tokenizer.encode(template, add_special_tokens=False, return_tensors='pt').cuda()
outputs = self.model.generate(
input_ids=input_ids, max_new_tokens=1024,
eos_token_id=terminators,
pad_token_id=self.tokenizer.eos_token_id
)
outputs = outputs.tolist()[0][len(input_ids[0]):]
response = self.tokenizer.decode(outputs, skip_special_tokens=True)
|
|
|
|
|
参考