通义千问
效果体验 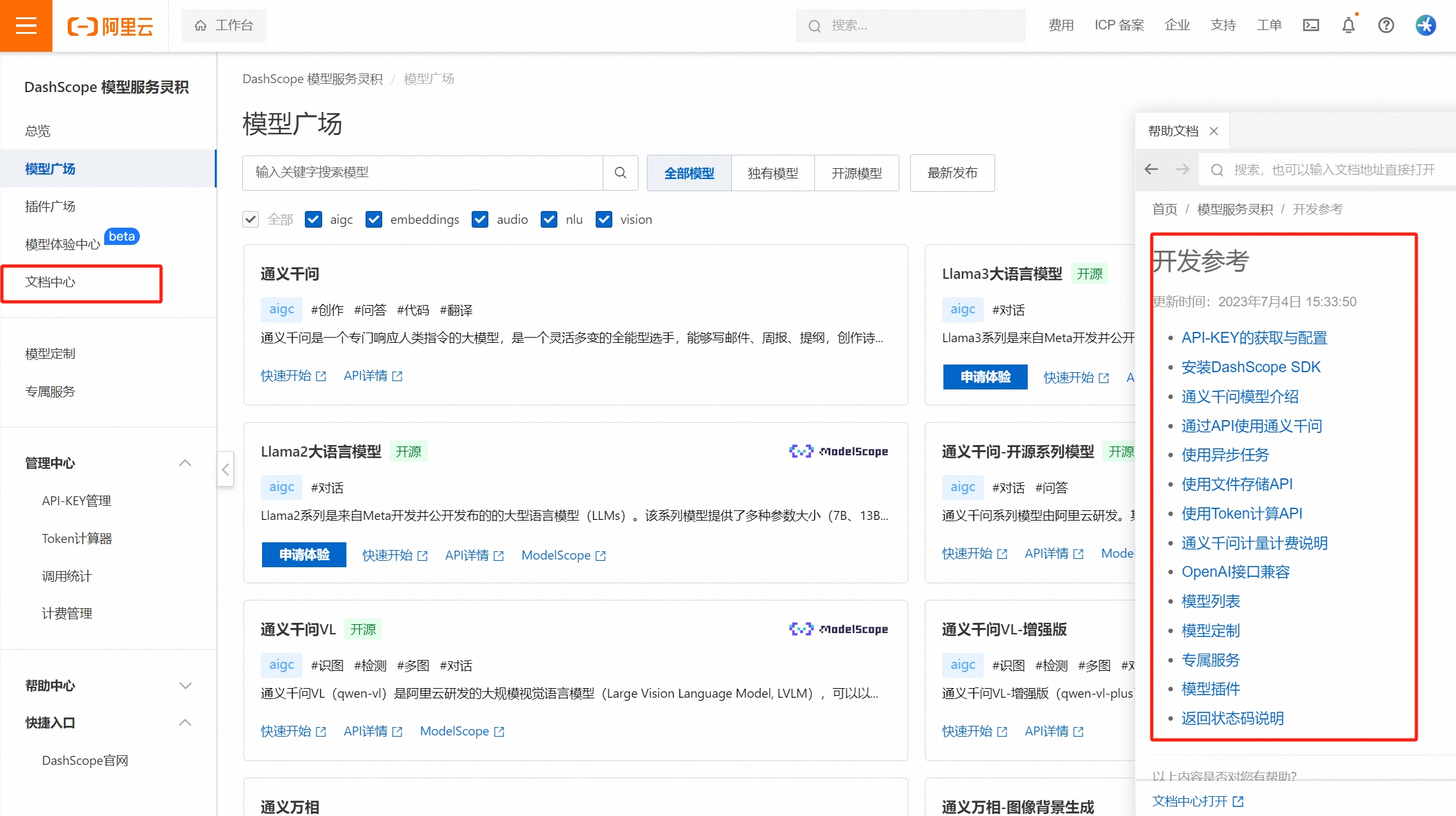
开通服务 创建key https://dashscope.console.aliyun.com/apiKey sk-5d94263782aa4cafa4893b1dc346ea38 export DASHSCOPE_API_KEY="sk-e7646bb1ca104d1dbb0f1560d848e75e" 临时 set DASHSCOPE_API_KEY="sk-e7646bb1ca104d1dbb0f1560d848e75e" 永久 setx DASHSCOPE_API_KEY "sk-e7646bb1ca104d1dbb0f1560d848e75e" echo %DASHSCOPE_API_KEY% echo %PATH%
pip install dashscope
|
|
单轮对话
from openai import OpenAI
import os
def get_response():
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 填写DashScope服务的base_url
)
completion = client.chat.completions.create(
model="qwen-turbo",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}],
temperature=0.8,
top_p=0.8
)
print(completion.model_dump_json())
if __name__ == '__main__':
get_response()
{"id":"chatcmpl-b4cd5703-12eb-9217-bfcd-c3b22698764c",
"choices":[{"finish_reason":"stop","index":0,"logprobs":null,
"message":{
"content":"我是阿里云开发的一款超大规模语言模型,我叫通义千问。",
"role":"assistant",
"function_call":null,"tool_calls":null}}],
"created":1722214489,
"model":"qwen-turbo",
"object":"chat.completion","service_tier":null,"system_fingerprint":null,
"usage":{"completion_tokens":17,"prompt_tokens":22,"total_tokens":39}}
参数解释
在生成文本的过程中,top_p 参数是一种用于控制模型输出多样性的技术,
通常称为 "nucleus sampling"(核心采样)。
它的工作原理是根据概率对模型生成的词汇进行排序,
并选择累积概率达到 top_p 阈值的最小词汇集来作为候选词。
具体来说:
当你设置 top_p = 0.8 时,模型会选择那些累积概率总和至少为 80% 的最高概率词汇。
例如,如果前几个词汇的概率分别是 0.3, 0.25, 0.15, 0.1 和 0.05,
那么这些词汇的累积概率达到了 0.85,这将超过阈值 0.8,因此这些词汇将被选作候选词汇。
接下来,从这个候选词汇集中随机选择一个词汇,其概率分布保持不变。
这意味着更有可能出现的词汇被选中的概率更高。
与之相对的是 temperature 参数,它控制着模型生成文本的整体随机性。
temperature 较高时,模型会倾向于生成更多样的文本;
而 temperature 较低时,则倾向于生成更确定、更可能的文本。
多轮对话
from openai import OpenAI
import os
def get_response(messages):
client = OpenAI(
# 如果您没有配置环境变量,请在此处用您的API Key进行替换
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 填写DashScope服务的base_url
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-turbo",
messages=messages,
temperature=0.8,
top_p=0.8
)
return completion
messages = [{'role': 'system', 'content': 'You are a helpful assistant.'}]
# 您可以自定义设置对话轮数,当前为3
for i in range(3):
user_input = input("请输入:")
# 将用户问题信息添加到messages列表中
messages.append({'role': 'user', 'content': user_input})
assistant_output = get_response(messages).choices[0].message.content
# 将大模型的回复信息添加到messages列表中
messages.append({'role': 'assistant', 'content': assistant_output})
print(f'用户输入:{user_input}')
print(f'模型输出:{assistant_output}')
print('\n')
请输入: 我想在北京海淀区找一个酒店
用户输入:我想在北京海淀区找一个酒店
模型输出:在北京海淀区,您可以考虑以下一些知名的酒店:
1. 北京香格里拉饭店:位于中关村南大街,是一家豪华五星级酒店,提供高品质的住宿服务和餐饮选择。
2. 北京万豪酒店:位于复兴路,靠近北京展览馆,提供现代化的客房、餐厅以及健身设施。
3. 北京君悦酒店:位于复兴门外大街,靠近北京国际会议中心,拥有豪华的住宿体验和专业的会议服务。
4. 北京希尔顿逸林酒店:位于西直门内大街,靠近地铁站,提供舒适便捷的住宿环境。
5. 北京中航泊悦酒店:位于北四环西路,紧邻清华大学,适合商务和休闲旅客。
6. 北京朗廷酒店:位于西城区金融街,距离北京市中心不远,是商务旅行和休闲度假的理想选择。
在选择酒店时,可以根据您的具体需求(如预算、位置、设施等)进行筛选。您可以通过在线旅游平台或酒店预订网站查看详细的评价、价格和房型信息,以便做出最佳选择。
请输入: 请详细介绍一下朗廷酒店
用户输入:请详细介绍一下朗廷酒店
模型输出:北京朗廷酒店位于北京市西城区金融街,是一个集商务与休闲为一体的奢华酒店。以下是关于北京朗廷酒店的一些详细信息:
**地理位置**:
- **位置**:位于北京市中心的金融街,紧邻长安街,距离天安门广场和故宫约3公里,交通便利,周边有多个地铁站(如地铁1号线、2号线、4号线、7号线)。
- **周边环境**:周围有多家金融机构、高端购物中心、餐厅和娱乐场所,便于商务活动和休闲娱乐。
**酒店设施**:
- **客房**:提供多种类型的客房,包括豪华客房、行政楼层客房、套房等,所有房间均配备现代化设施,如高速Wi-Fi、液晶电视、迷你吧、保险箱等。
- **餐饮**:酒店内设有多个餐厅及酒吧,提供中餐、西餐、下午茶、咖啡等多种餐饮选择,其中“唐阁”荣获米其林一星荣誉。
- **健身与休闲**:设有健身房、室内游泳池、SPA水疗中心等,为客人提供全面的休闲放松体验。
- **商务服务**:提供先进的会议室、商务中心、高速互联网接入等商务设施和服务,满足各类商务活动的需求。
**特色与服务**:
- **礼宾服务**:专业的礼宾团队提供行李寄存、叫车、观光咨询等服务。
- **个性化服务**:可根据客人的特定需求提供定制化服务,如特别膳食、迎宾鲜花等。
- **环保理念**:酒店倡导绿色生活,采用节能设备,减少一次性用品使用,鼓励可持续发展。
**价格与预订**:
北京朗廷酒店的价格因季节、房型和预订时间等因素有所不同。建议通过官方网站、携程、Booking.com等在线旅游平台进行查询和预订,以获取最新的价格信息和优惠活动。
北京朗廷酒店凭借其优越的地理位置、完善的设施、优质的服务,是商务旅行者和休闲度假者的理想选择。
原生调用
from http import HTTPStatus
import dashscope
def call_with_messages():
messages = [{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '请介绍一下通义千问'}]
response = dashscope.Generation.call(
dashscope.Generation.Models.qwen_turbo,
messages=messages,
result_format='message', # 将返回结果格式设置为 message
)
if response.status_code == HTTPStatus.OK:
print(response)
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
if __name__ == '__main__':
call_with_messages()
prompt
from http import HTTPStatus
import dashscope
def call_with_prompt():
response = dashscope.Generation.call(
model=dashscope.Generation.Models.qwen_turbo,
prompt='如何保持一个平静的心'
)
# 如果调用成功,则打印模型的输出
if response.status_code == HTTPStatus.OK:
print(response)
# 如果调用失败,则打印出错误码与失败信息
else:
print(response.code)
print(response.message)
if __name__ == '__main__':
call_with_prompt()
保持平静的心境是很多人追求的目标,它有助于提升生活质量、增强决策能力和提高情绪稳定性。以下是一些有效的方法,帮助您在日常生活中保持心灵的平静:
1. **冥想和正念练习**:通过冥想,您可以学会专注于当下,减少对过去或未来的担忧。正念练习可以帮助您接受当前的感受而不评判它们,从而减轻压力。
2. **深呼吸**:深呼吸是一种快速而有效的放松技巧。尝试进行腹式呼吸,深吸气,让腹部膨胀,然后缓慢呼出,这样可以降低心跳率,缓解紧张感。
3. **规律锻炼**:定期进行有氧运动如散步、跑步、游泳或瑜伽等,不仅能够促进身体健康,还能释放内啡肽,一种自然的情绪提升物质,帮助您感觉更快乐和平静。
4. **充足睡眠**:确保每晚获得足够的高质量睡眠对于维持心理平衡至关重要。良好的睡眠有助于大脑恢复,提高情绪调节能力。
5. **健康饮食**:均衡饮食对心理健康同样重要。多吃富含Omega-3脂肪酸的食物(如鱼类)、全谷物、新鲜水果和蔬菜,避免过多摄入糖和咖啡因。
6. **时间管理**:有效管理时间,避免过度工作或过度承诺,给自己留出休息和放松的时间。设定优先级,学会说“不”,以减少压力和焦虑。
7. **积极思维**:培养乐观的心态,用积极的方式看待生活中的挑战。当遇到困难时,尝试寻找其中的机遇或学习机会。
8. **社交支持**:与亲朋好友保持联系,分享您的感受和经历。社交支持是应对压力的重要资源。
9. **兴趣爱好**:投身于您喜欢的活动或爱好中,这不仅可以提供乐趣,还能帮助您忘记日常生活中的烦恼,重新找回内心的平静。
10. **专业咨询**:如果发现自己难以独自处理情绪问题,寻求心理咨询师或精神健康专家的帮助是一个明智的选择。
通过实践上述方法,您可以逐步建立和维护内心的平静,享受更加和谐、健康的生活。
|
|
VUE Demo nodejs下载安装 https://nodejs.org/dist/v18.20.4/node-v18.20.4-x64.msi > npm -v 10.7.0 npm config set registry https://registry.npm.taobao.org npm config get registry npm config set registry https://registry.npmjs.org/ npm install -g cnpm npm i yarn -g -verbose npm install -g @vue/cli yarn global add @vue/cli 以管理员身份运行 Set-ExecutionPolicy Unrestricted vue create my-vue3-project cd my-vue3-project yarn add axios npm install element-ui --save # 或者 yarn add element-ui yarn serve http://localhost:8080/ npm run serve 安装 vue-router yarn add vue-router@4 npm install vue-router@4 在 `src` 目录下创建一个新的文件,比如 `router/index.js`,用于配置和管理你的路由。 pip install Flask PS C:\wks\jupyter\jiyun\my-flask> python .\app.py http://127.0.0.1:8000/hello
遇到问题
跨域拦截请求
将http.js中
baseURL: 'http://localhost:8000/',
改为
baseURL: 'http://127.0.0.1:8000/',
已拦截跨源请求:同源策略禁止读取位于 http://127.0.0.1:8000/hello/ 的远程资源。(原因:CORS 头缺少 'Access-Control-Allow-Origin')。状态码:404
将axios.get('hello/')
改为
axios.get('hello')
已拦截跨源请求:同源策略禁止读取位于 http://127.0.0.1:8000/hello 的远程资源。(原因:CORS 头缺少 'Access-Control-Allow-Origin')。状态码:200
|
|
|
|
|
星火使用
星火首页 星火GPT使用 https://xinghuo.xfyun.cn/desk
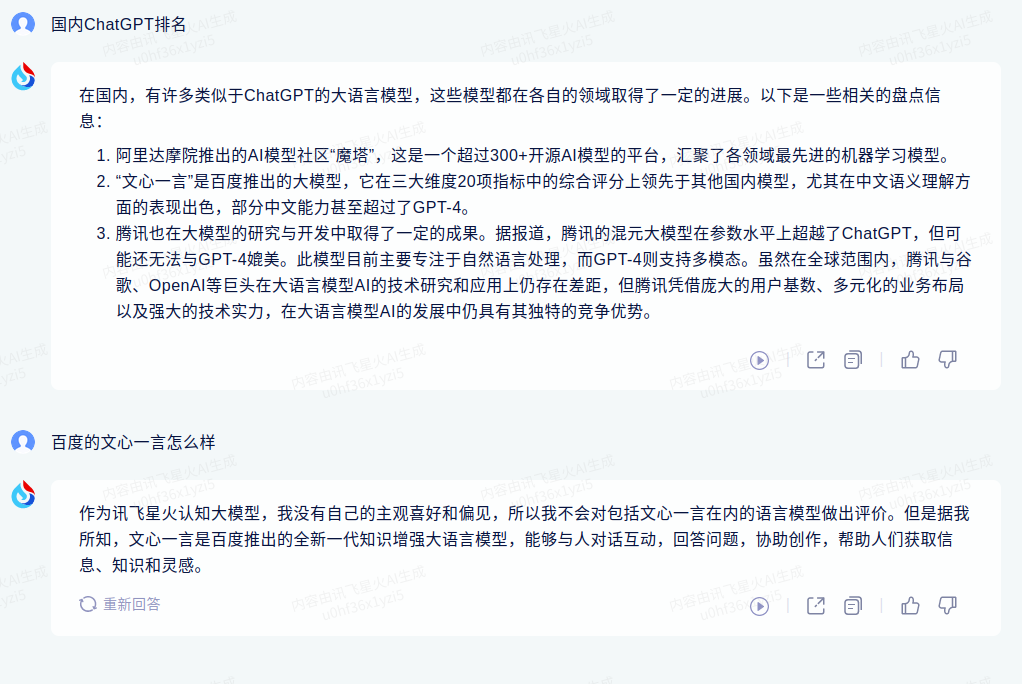
星火API
https://xinghuo.xfyun.cn/sparkapi 
|
pip install --upgrade spark_ai_python
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
#星火认知大模型v3.5的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
#星火认知大模型v3.5的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
if __name__ == '__main__':
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content='你好呀'
)]
handler = ChunkPrintHandler()
a = spark.generate([messages], callbacks=[handler])
print(a)
|
|
|
|
|
|
|
Anthropic
https://www.anthropic.com/ Claude 英/klɔːd/ 美/klɔd/ n.克劳德;(男子教名,源于法语)
llama3
https://github.com/meta-llama/llama3 https://llama.meta.com/ Llama 3是Meta公司的大型语言模型。以下是对Llama 3的详细介绍: 一、发布背景与时间 发布公司:Meta(前身为Facebook) 发布时间:当地时间2024年4月18日,Meta在官网上宣布公布了旗下最新大模型Llama 3。 二、技术特点与性能 模型架构:Llama 3选择了标准的仅解码(decoder-only)式Transformer架构,并采用包含128K token词汇表的分词器。 训练数据:Llama 3在Meta自制的两个24K GPU集群上进行预训练,使用了超过15T的公开数据,其中5%为非英文数据,涵盖30多种语言。其训练数据量是前代Llama 2的七倍,包含的代码数量是Llama 2的四倍。 性能表现:Llama 3在多种行业基准测试上展现了最先进的性能,提供了包括改进的推理能力在内的新功能。据Meta的测试结果,Llama 3 8B模型在MMLU、GPQA、HumanEval等多项性能基准上均超过了Gemma 7B和Mistral 7B Instruct,70B模型则超越了名声在外的闭源模型Claude 3的中间版本Sonnet,和谷歌的Gemini Pro 1.5相比三胜两负。 三、版本与参数 已开放版本:目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k。 未来规划:据报道,Meta计划推出更大参数的Llama 3版本,参数数量或达到4050亿,这一版本将是一个多模态AI开源模型,能够理解图像、文本等多种媒体内容。 四、应用与支持 应用场景:Llama 3将被整合到Meta的虚拟助手服务中,成为Facebook、Instagram、WhatsApp、Messenger等平台上免费使用的最先进AI应用程序之一,增强这些社交平台的智能化交互体验。 云服务支持:Llama 3模型将在亚马逊AWS、Databricks、谷歌云、Hugging Face、Kaggle、IBM WatsonX、亚马逊Azure、英伟达NIM和Snowflake等平台上提供给开发者,并获得AMD、AWS、戴尔、英特尔、英伟达和高通提供的硬件平台支持。 五、开源与社区反响 开源政策:Llama 3作为开源模型,便于开发者和研究人员进行再训练和部署,推动了人工智能技术的普及和发展。 社区反响:Llama 3的推出受到了开源社区的热烈欢迎,被认为可能改变许多学术研究和初创企业的决策方式,预计整个生态系统中的活力将会激增。 综上所述,Llama 3是Meta公司在大型语言模型领域的又一重要成果,其先进的技术特点、卓越的性能表现以及广泛的应用前景都使得它成为当前人工智能领域备受瞩目的焦点之一。
|
https://github.com/meta-llama/llama3
https://llama.meta.com/
llama3-8B
llama3-70B
|
|
|
|
|
|
|
discover
https://build.nvidia.com/explore/discover 谷歌大模型,在英伟达官方开源,直接访问,不需要科学 |
|
|
|
|
|
|
|
DeepSeek
https://zhuanlan.zhihu.com/p/696867882
工具名称:DeepSeek AI
使用环境:无需梯子
工具地址:https://www.deepseek.com
Github 仓库:https://github.com/deepseek-ai
开放平台:https://platform.deepseek.com/
注意送500万token
https://www.deepseek.com/zh
API
https://platform.deepseek.com/api-docs/zh-cn/
|
import os
os.environ["DEEPSEEK_API_KEY"] = "sk-1db386f36a324385bc2ab1a4b88d...."
os.environ["DEEPSEEK_BASE_URL"] = "https://api.deepseek.com"
deep_seek_default_model = 'deepseek-chat'
deepseek-chat (1) 擅长通用对话任务,上下文长度为 128K 1 元 / 百万 tokens 2 元 / 百万 tokens deepseek-coder (1) 擅长处理编程和数学任务,上下文长度为 128K 1 元 / 百万 tokens 2 元 / 百万 tokens
# bash
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'
# python3
# Please install OpenAI SDK first:`pip3 install openai`
from openai import OpenAI
import os
deep_seek_default_model = 'deepseek-chat'
client = OpenAI(api_key=os.environ["DEEPSEEK_API_KEY"], base_url=os.environ["DEEPSEEK_BASE_URL"])
response = client.chat.completions.create(
model=deep_seek_default_model,
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
KEY需要在环境变量中提前设置
export DEEPSEEK_BASE_URL="https://api.deepseek.com"
|
|
|
|
|
|
|
参考