Alex时代背景
这是神经网络之父 Geoffrey Hinton 和他的两个学生——Alex Krizhevsky 、Ilya Sutskever——之间的一段对话。对话发生在 2012 年 12 月。对于整个人工智能领域来说,这是非常重要的一个年份。
在这一年的 ImageNet 挑战赛上,Hinton 和 Krizhevsky、Sutskever
提出的深度神经网络 AlexNet 一骑绝尘,
将图像分类的错误率降低了一半,以远超第二名的成绩拿到了比赛的冠军,证明了深度学习的巨大潜力。
深度学习崛起那年,百度差点签下Hinton
https://m.thepaper.cn/baijiahao_11802862

Ilya Sutskever(左)、Alex Krizhevsky(中)和 Geoffrey Hinton(右) ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。 超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象; 在至少一百万个图像中,还提供了边界框。 ImageNet包含2万多个类别; [2]一个典型的类别,如“气球”或“草莓”,包含数百个图像。 第三方图像URL的注释数据库可以直接从ImageNet免费获得; 但是,实际的图像不属于ImageNet。 自2010年以来,ImageNet项目每年举办一次软件比赛, 即ImageNet大规模视觉识别挑战赛(ILSVRC), 软件程序竞相正确分类检测物体和场景。 ImageNet挑战使用了一个“修剪”的1000个非重叠类的列表。 2012年在解决ImageNet挑战方面取得了巨大的突破,被广泛认为是2010年的深度学习革命的开始。 当时,经过50年的刻苦研究,时任多伦多大学教授的Geoffrey Hinton和他的两名博士生Ilya Sutskever、Alex Krizhevsky终于发现,只要借助两样东西就能让神经网络成功识别出图片中的物体:一是数据,也就是海量的图片,因此数据集对他们的研究至关重要;二是强大的计算处理能力。 2012年,他们终于集齐了这两大“利器”:斯坦福大学教授李飞飞创建的ImageNet数据集,初衷就是为了帮助人们研发出可识别图片中物体的技术,并且每一年都会举办公开比赛;另一方面,Alex发现,他写的GPU代码可以训练一个小型卷积网络,并在60秒内输出很不错的结果。 既有Hinton和Ilya、Alex这样愿意潜心做研究的人,再加上海量数据和强大处理能力的加持,可以说,神经网络技术已拥有天时地利人和。然而,当时大多数人并不相信神经网络,并质疑深度学习的原理,认为这只是一个美好的畅想,实际上毫无用处。 不过,在那一年的ImageNet竞赛上,神经网络AlexNet识别物体的准确率远超其他方法,在比赛中一举夺魁,人们由此真正认识并承认神经网络的强大。 除了展示神经网络的强大能量,Hinton和他的团队还积极地将其推广到工业领域。2013年初,以Google、微软、DeepMind、百度等为代表的科技公司纷纷加入了“收购”Hinton三人组公司DNN Research的竞拍战中,最终Google以4400万美元的“天价”将其收入囊中。 李飞飞的创举 Pieter Abbeel:越来越多人也后知后觉地意识到,当初斯坦福的李飞飞教授创办ImageNet挑战赛是多么具有前瞻性,她在深度学习还没有显露曙光的时候就创办了这个比赛。某种程度上,ImageNet比赛是深度学习开始成熟的契机。 Cade Metz:李飞飞的故事也是一个顶住质疑和反对、逆流而上的故事。一开始,李飞飞的导师不支持她建立大型图像数据集,并且认为这是一个糟糕的想法。到了2012年,多伦多大学的Hinton等人在参加ImageNet挑战赛时,将错误率从25%降到了16%。如果没有李飞飞创建的ImageNet数据集,我们就不能看到这一可喜成果的诞生。她和Ilya、Hinton一样都有着坚定的决心。 Pieter Abbeel:没错,我想为不了解学术界的人介绍一点背景。通常而言,在你当上教授后的头6年,你需要先取得一些研究成果,让自己获得声望、站稳脚跟,否则就会面临被辞退的风险。如果你在这6年做得不错,就可以晋升为终身教授,拥有学术自由,想做什么研究都可以。所以,很多人会在头6年先做一些比较有确定性的事,比如研究公认的重大课题,6年后再去做风险更大的研究。 但在李飞飞做教授的那6年里,哪怕周围的人都告诉她,创建数据集是在浪费时间,还不如好好写其他热门方向的论文,她还是坚持自己的想法,认为自己的研究很有价值。她很了不起,行业内的很多了不起的人都是不惧质疑、坚持自我,他们是对的。 Cade Metz:完全同意。像李飞飞这样有勇气对导师说“我明白你的意思,但我还是想这么做”的人,这类故事很值得被报道传扬。各行各业都需要这种精神,作为记者我也深有体会:随大流去报道那些所有人竞相报道的事件很容易,但报道那些没人追踪的、让同行倍感犹豫甚至质疑的事件却很难。在任何领域,坚持自我都是一个宝贵的品质。 天才制造者:独行侠、科技巨头和AI |深度学习崛起十年 https://zhuanlan.zhihu.com/p/517079647 2017年11月前后,谷歌的AutoML项目发展出新的神经网络拓扑结构,创建了NASNet,这是一个针对ImageNet和COCO优化的系统。 据Google称,NASNet的性能超过了以前发布的所有ImageNet性能。 [1] |
2012年的一场竞赛。那是ImageNet的人工智能识别比赛,AlexNet团队赢得第一。 我说,一场学院里的比赛,改变了整个世界的科技版图。 芯片之王,称霸30年的英特尔(Intel)很快就要让位于蛰伏多年的英伟达。 一场比赛而已,是不是吹过了? 又过了一年,我发现我的确错了,错在太保守,我吹得不够用力。 ImageNet是最权威的人工智能大赛。AlexNet不仅拿了第一,而且精确度是第二名的两倍。 它是一个卷积神经网络,一个模仿人类大脑神经元网络的数学系统。 开发者先用CPU训练,发现不给力,要几个月才能完成训练。 于是,换成了英伟达给游戏做图形渲染的GPU,一周就完成了。 英伟达给英特尔当了一辈子马仔。毕竟PC时代,CPU是霸道总裁,游戏显卡是可有可无的小弟。 智能手机来了,黄仁勋想逆天改命,去搞手机芯片,还专程跑到北京用蹩脚的中文给小米雷军站台。 很可惜,英伟达的移动战略失败,老黄眼看着只能继续苟且在英特尔或者高通的阴影里。 谁想到,AlexNet从天而降,在智能时代深度学习的场景里,英伟达GPU大有可为。 公司市值已经抵得上三个英特尔。 一场比赛,让三十年硬件江湖换了姓,已经够吊炸天。 但是没完,ChatGPT问世,正式宣告,那场比赛掀起的革命不止于芯片江湖,软件、互联网、整个科技界,都要翻江倒海。 https://cloud.tencent.com/developer/article/2222661 |
AlexNet由三个人开发,计算机老教授辛顿(Geoffrey Hinton),还有他的两个学生,Alex Krizhevsky和小萨。Alex和小萨,都出生在苏联。 △左:Sutskever;中:Krizhevsky;右:Hinton;图源:多伦多大学 大赛夺魁后,第一个找上门来的竟然是百度。李彦宏非常喜欢,希望深度合作,先提供100万美元研究经费。 但是,也是因为百度太主动,师徒三人发现商机。 他们成了一家公司,没有收入,没有流水,没有业务,只有三个人。 他们要卖掉这家什么都没有的公司,而且,为了利益最大化,方式是——拍卖。 从第一份报价,百度的1200万美元开始。价格一步步上升,来到4400万美元。 只剩下谷歌和微软。两家都势在必得,准备更高的报价。 这时候,有了工程师独特的一面。 三个人不打算让两家巨头再加价,而是开始关心钱之外的事情,最终决定去谷歌。 辛顿老师说,4400万美元三个人平分。但是Alex和小萨坚持老师拿40%。 02 谷歌、微软、Facebook的战争已经全面打响。 谷歌用安卓抢走了微软的”操作系统之王”。微软狠狠砸钱用Bing搜索攻谷歌底盘。谷歌不再是进入互联网的入口,更多人打开电脑第一件事是登录社交网络Facebook。Facebook想争夺更多用户的时间和数据,要和谷歌争一争,谁才是这颗星球上最大的广告商。 三家都试过造手机,要从软件里走出来,掌握硬件的支配权。布林亲自挂帅,去搞谷歌眼镜。轰轰烈烈地推出,苟苟且且地失败。布林又挂帅去搞社交网络,Google+对着Facebook打,又失败。布林嘿嘿一笑,难为我了,我这个人不擅社交。晕倒,你可是公司里人尽皆知的沾花惹草花花公子啊。 如果微软、谷歌、Facebook是魏蜀吴,那么人工智能就是荆州,争荆州,就是争天下。 谷歌用4400万美元,买来一位老教授和两位天才少年。不久,用6.5亿美元,收购只有50人的DeepMind。真是,傲视群雄,笑傲江湖。 尤其是,这两场争夺,最后都是和微软、Facebook单挑。最后都不是钱的问题。最后都是谷歌“不战而屈人之兵”。 辛顿三人,4400万美元,微软说,我还可以加价,给你们很多很多money。三人说,不用了,我们去谷歌。 DeepMind也是,最后就剩谷歌和Facebook。如果选择Facebook的方案,团队每个人分到的现金是谷歌方案的两倍,但是创始团队不要去Facebook,坚持卖给谷歌。 当年的谷歌就是人帅钱多形象好,一句不作恶(Don’t do evil)的价值观口号喊进了天下极客的心里。 而微软是一个老迈的垄断者,大公司病晚期。 Facebook是个莽夫,暴发户,奉行增长高于一切。 马克·扎克伯格不服啊,凭什么你们总看不起我。人工智能,一定要拿下,不惜任何代价。 终于请来了大将——法国人杨立昆。 吊炸天的AlexNet,就是利用了杨立昆的研究成果卷积神经网络,站在了巨人的肩膀上。现在巨人来了。 2016年那场棋局,表面上看是AlphaGo单挑李世石。但是背后,是谷歌单挑Facebook。 Facebook要抢先手,到处宣扬自己在AI上的投入和成果,一点点进展就开发布会,请记者去总部参观。字里行间,就是希望树立起Facebook是人工智能的领导者,话事佬。还抛出一个话题,正在攻克围棋,再过几年Facebook的人工智能就能战胜人类最好的棋手。 △图源:DeepMind 但是谷歌为我们演示了,什么叫人狠话不多。DeepMind是一家几乎没有新闻的公司,有一天突然宣布,在一场闭门比赛里,打败了三届欧洲围棋冠军。 Facebook平时那么高调,扮老大,记者肯定第一时间找它。杨立昆很有信心地说,不可能!以我在行业的地位,如果真的开发出来了,一定会有人告诉我。AI要战胜顶级围棋棋手,还要几年时间。Facebook是领先的。 之后发生的一切,是人类科技史上极端残忍的一幕,是对Facebook的大型鞭尸现场。 AlphaGo大战李世石。第三天,比赛进入高潮,谷歌创始人布林飞到首尔,留下了这张经典照片。 △图:李世石(左一)、布林(右一) AI领导者马克扎克伯格怎么不在这么重要的历史照片里?哦,他在家里看电视呢,尴尬地用脚趾抠地板。 谷歌把竞争对手,收拾得服服帖帖的。 小萨,当年分到4400万美元的30%,去谷歌上班,被分到子公司DeepMind帮忙,搞一个下围棋的项目,为2016年的这场历史性的棋局,做出了基石性的贡献。 |
Alex论文
ImageNet Classification with Deep Convolutional Neural Networks
Alex Krizhevsky
University of Toronto
kriz@cs.utoronto.ca
Ilya Sutskever
University of Toronto
ilya@cs.utoronto.ca
Geoffrey E. Hinton
University of Toronto
hinton@cs.utoronto.ca
杰弗里·辛顿(Geoffrey Hinton)
杰弗里·辛顿(Geoffrey Hinton),1947年12月6日出生于英国温布尔登,2018年图灵奖得主,英国皇家学会院士,加拿大皇家学会院士,美国国家科学院外籍院士,多伦多大学名誉教授。 [1-2] [7]
杰弗里·辛顿于1970年获得剑桥大学实验心理学学士学位;1976年受聘为苏塞克斯大学认知科学研究项目研究员;1978年获得爱丁堡大学人工智能学博士学位。1978年至1980年担任加州大学圣地亚哥分校认知科学系访问学者;1980年至1982年担任英国剑桥MRC应用心理学部科学管理人员;1982年至1987年历任卡内基梅隆大学计算机科学系助理教授、副教授;1987年受聘为多伦多大学计算机科学系教授;1996年当选为加拿大皇家学会院士;1998年当选为英国皇家学会院士;1998年至2001年担任伦敦大学学院盖茨比计算神经科学部创始主任;2001年至2014年担任多伦多大学计算机科学系教授;
2016年至2023年担任谷歌副总裁兼工程研究员;2023年从谷歌辞职。 [2]
杰弗里·辛顿致力于
神经网络、机器学习、分类监督学习、机器学习理论、
细胞神经网络、信息系统应用、马尔可夫决策过程、神经网络、认知科学等方面的研究。 [3]
|
先快速多维度提取特征,同时快速收缩特征图,
结合最后的分类个数,再加1-3层处理,然后分类
相当于将铺在一个大平面上的信息...拆分...到一个个小平面上
最后将整合这些小平面,进行分类
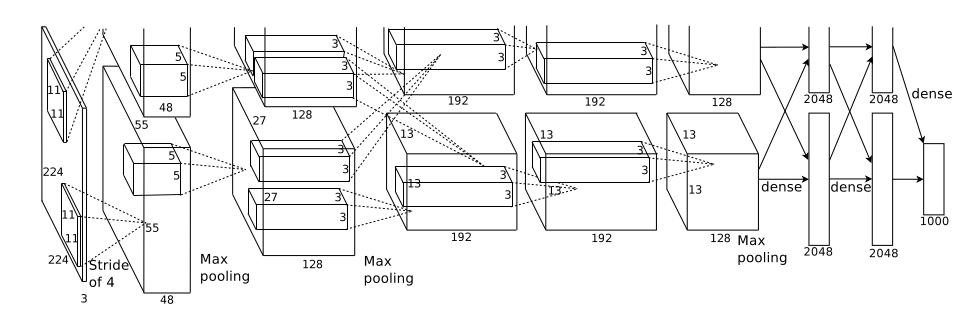
输入是3层特征图为[224,224]的图像,输出是1000个图像分类 maxpool负责收缩特征图 卷积提取特征 这时的卷积核还不是标准的311 |
from torchvision import models import torch from torch import nn from torch.nn import functional as F models.AlexNet()
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
|
import torch
from torch import nn
class AlexNet(nn.Module):
"""
自定义AlexNet
"""
def __init__(self):
# 这是一句必须要写的废话
super(AlexNet, self).__init__()
# 定义提取特征部分
self.features = nn.Sequential(
#(224+2*2 - 11)/4 + 1 = 55
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=11, stride=4, padding=2),
nn.ReLU(),
#(55+0*2-3)/2 +1 = 27
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
#(27+2*2-5)/1 + 1 =27
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
#(27+2*0-3)/2 +1 =13
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
#后面都是311设计,也就是说此网络先是快速收缩了特征图大小,到一定程度后保持不变
#先快速收缩是建立在原特征图224*224比较大的前提下
nn.Conv2d(in_channels=192, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
# 在一定程度上,可以输入任意大小的图像
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(6, 6))
# 定义分类部分
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Flatten(),
# 256*6*6=9126
nn.Linear(in_features=9216, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=10)
)
def forward(self, x):
# 提取特征
h = self.features(x)
# 规范大小
h = self.avgpool(h)
# 做分类
o = self.classifier(h)
return o
imgs = torch.randn(3,1,224,224) model = AlexNet() model(imgs).shape torch.Size([3, 10]) |
# 在一定程度上,可以输入任意大小的图像 self.avgpool = nn.AdaptiveAvgPool2d(output_size=(6, 6)) maxpool是按滑动窗口的方式,也就是卷积的方式取值 AdaptiveAvgPool2d则是,你想要一个什么shape的特征图,直接说,中间怎么算它自己想办法 |
参考