rsnet论文
Deep Residual Learning for Image Recognition Kaiming He Xiangyu Zhang Shaoqing Ren Microsoft Research Jian Sun arXiv:1512.03385v1 [cs.CV] 10 Dec 2015 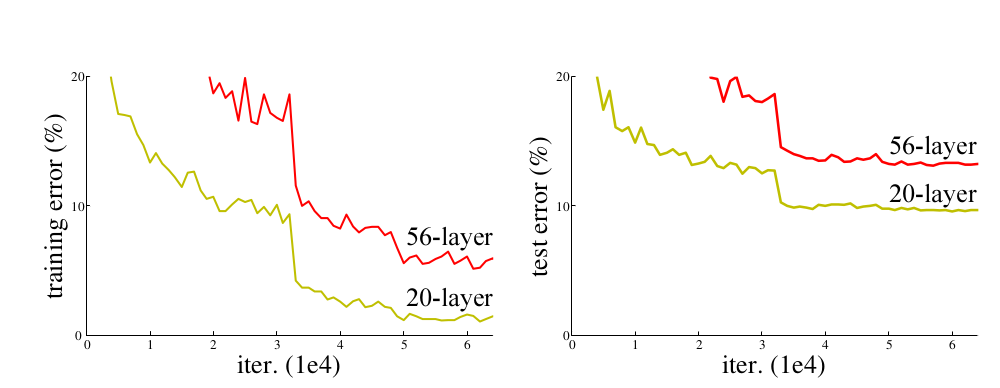
Figure 1.
Training error (left) and test error (right) on CIFAR-10
with 20-layer and 56-layer “plain” networks.
The deeper network has higher training error, and thus test error.
residual 英/rɪˈzɪdjuəl/ 美/rɪˈzɪdʒuəl/ 残差
n.剩余;残余物;残渣 adj.残留的;剩余的
|
当网络比较深时,梯度回传,传不回去了,消失了 - 梯度回传,就是链式求导法则 - 一层层地求导,无数个小数连乘,结果就消失了,没有了, - 或者说当前的计算机无法计算了,因为浮点数小数点后的有效位数不是无限的, - 比如float32,小数点后只有7位有效数字 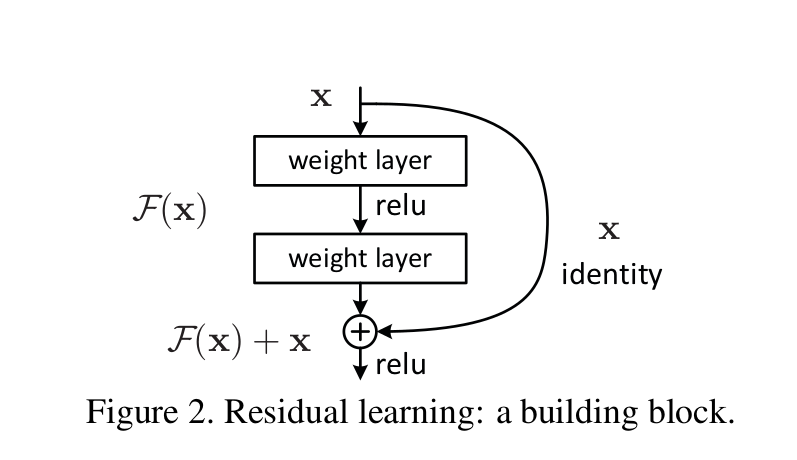
resnet将一系列计算下来的,还存在的,少量的残留信息,加到当初计算之前,原生的信息上
|
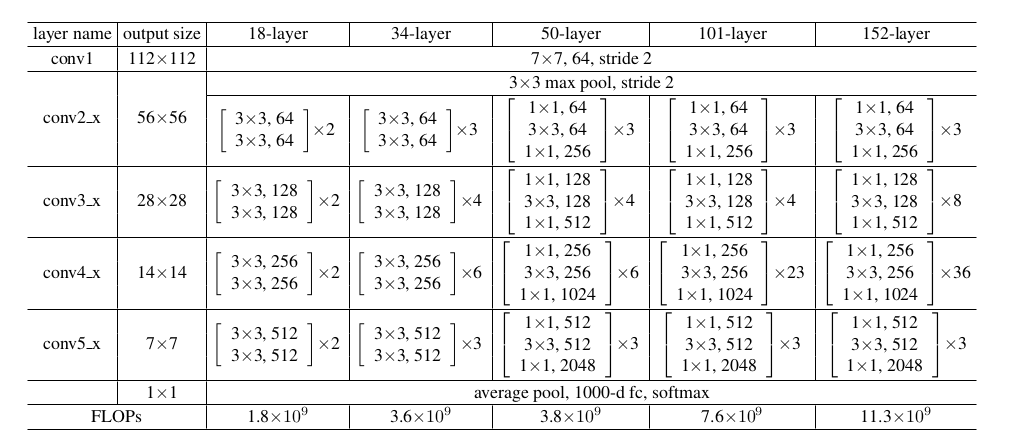
Table 1. Architectures for ImageNet. Building blocks are shown in brackets (see also Fig. 5), with the numbers of blocks stacked. Down-sampling is performed by conv3 1, conv4 1, and conv5 1 with a stride of 2. 
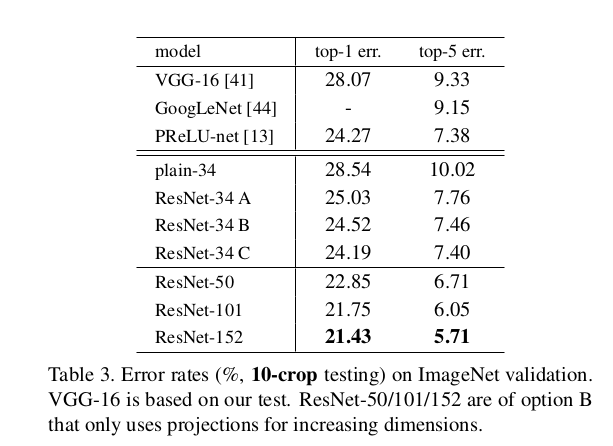
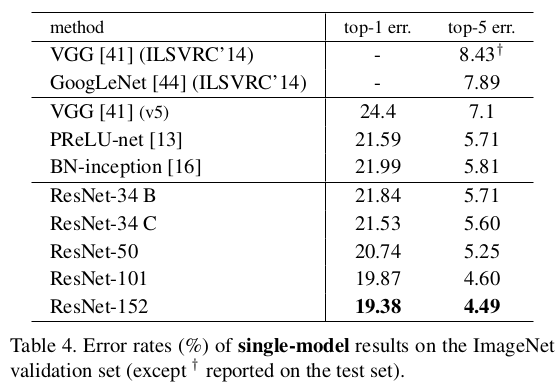
主要看 ResNet-50,ResNet-101 两个网络 |
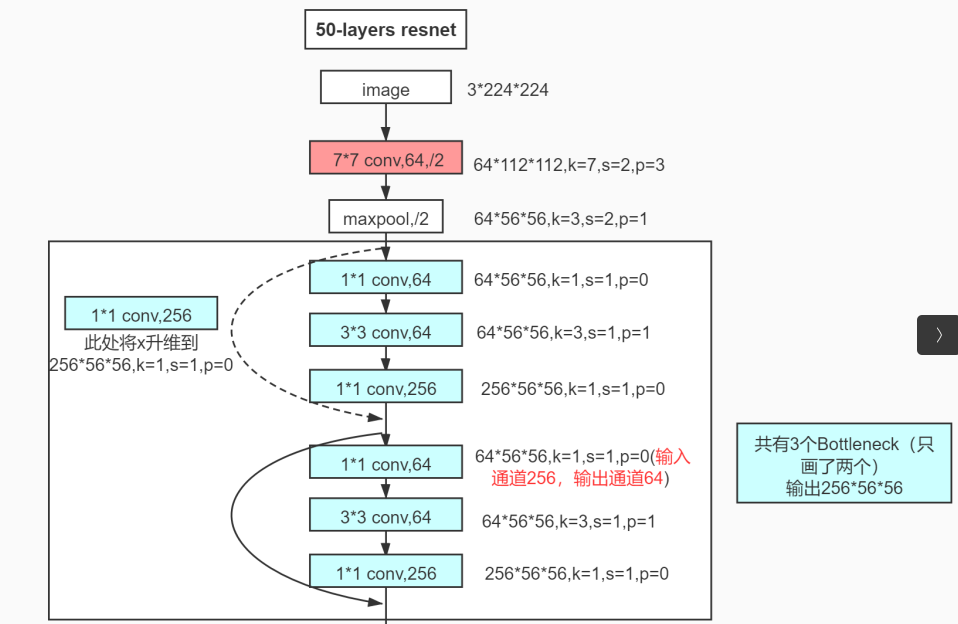
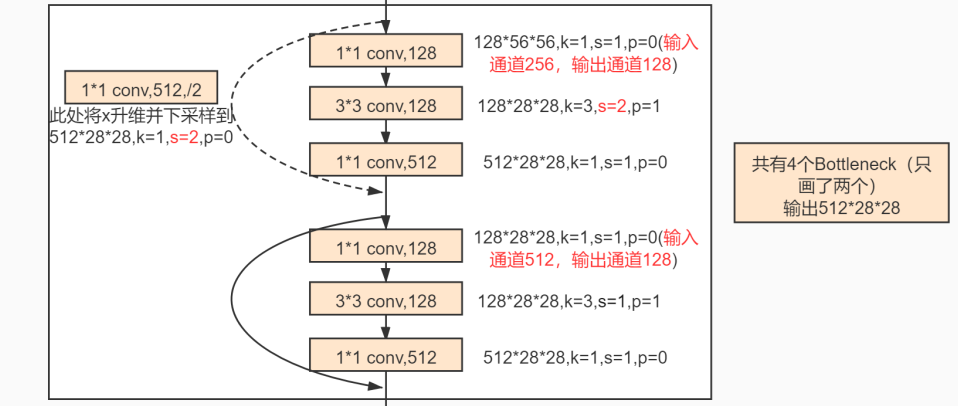
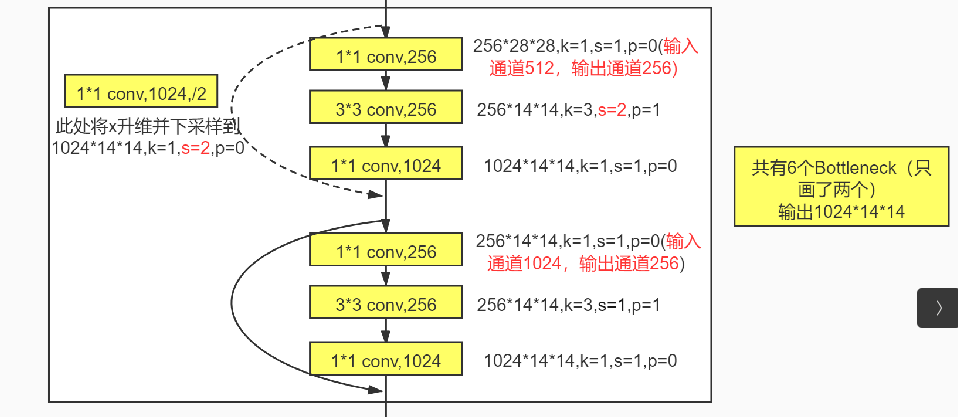
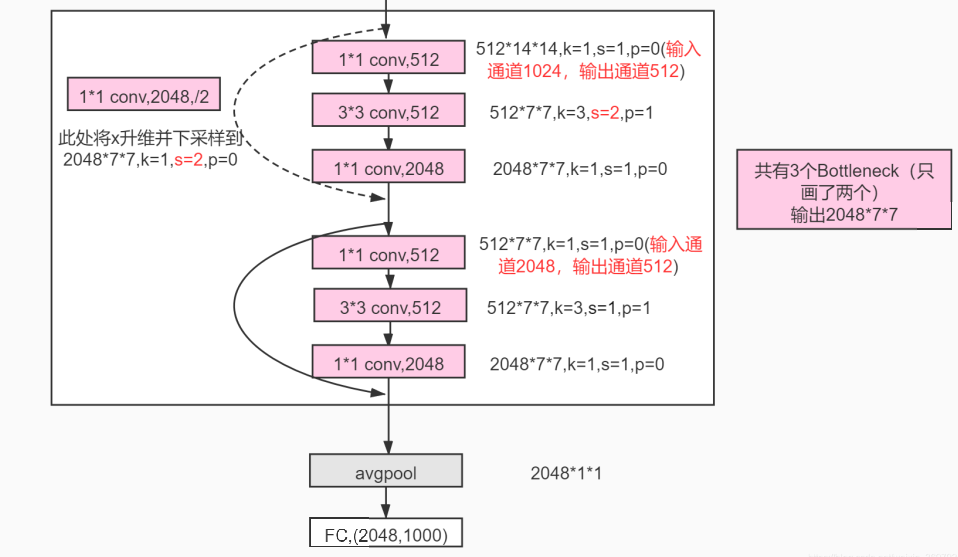
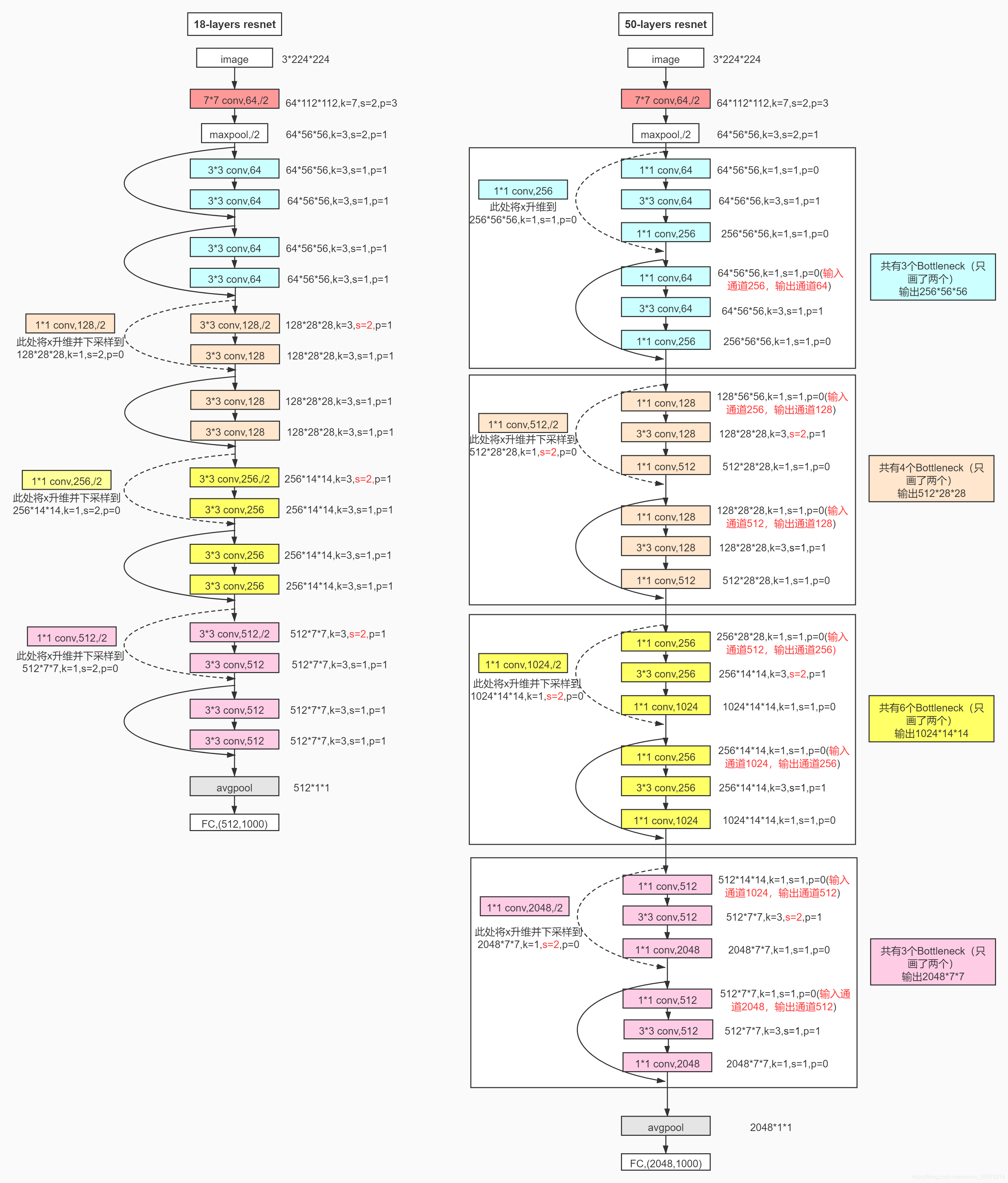
主线 - 使用全连接保留了所有的信息,一点点的信息都没有舍弃 辅助 - 使用卷积提取特征将信息+到主线上,提供变化 |
rsnet网络
|
快速收缩特征图,降低信息量,特征图shape收缩 kernel=3,step=1,padding=1:特征图shape不变 kernel=3,step=2,padding=1 特征图shape(的边)收缩为原来的一半(面积为原来的四分之一) 
step=2,一次走两步,跨越两个点,将两个点变为一个点,特征图shape减半
面对将224*224*3=150528的信息量归于1000个分类的局面,
resnet先卷积step=2收缩一次,后maxpool step=2收缩一次
两次收缩后,特征图由224*224变成56*56=3136,
认为这3000多的信息量,足以做1000的分类
这是粗选,后面开始进入精选
|
|
短接 虚线短接,为主数据流 做一次卷积 再加回去 实线短接,为主数据流 直接 再加回去 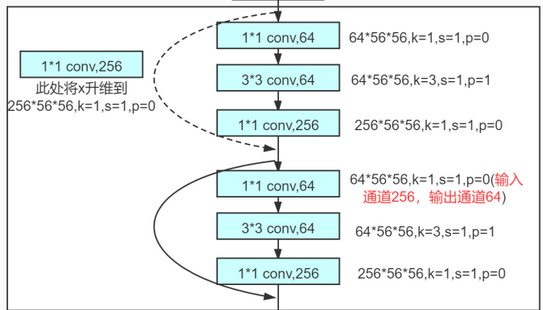
有了短接,弱化了梯度消失的缺点,小核多层设计的优势就充分展现出来了 另外,k=1,s=1,p=0,使用卷积去做全连接,相当于流处理... 多尺度
在inception中,多尺度的应用是相同的层数,不同的核大小的数据融合
resnet吸收了多尺度的思想,但应用的方式不一样,
在resnet中,主要指不同的层数,这也是短接中的“短”的意义所在
一个是浅层,或者干脆就是原数据,另外一个是经过了多层计算的数据
- 总体的效果是,在保住梯度的前提下,对数据进行了微调
- 这与RNN中保留一条主线,同时又加入当前元素的做法类似,也是多尺度的运用
- RNN多是处理文本的,通常说包含了上下文信息,
- 但从信息处理/数据的角度看,就是原数据+新数据
- 总体看,就是数据的微调
- 在resnet的网络中,也不是上来就微调,而是先快速收缩,粗粒度过滤后才进行的微调
- 先粗后细,这个技巧的光芒,被“短接”给掩盖了...
虚线与实线 整个模型特征数是先升后降, 所以要想将开始的原数据与后面多层变换后的数据进行融合, 就需要先将数据的维度变换到相同的维度, 同时,这是要进行“短”接,所以模块的“短”的那一部分,只是进行一个简单的全连接, 目的就在于提升数据的维度 这就是虚线的作用 实线连接的两个环节,维度是一样的,因此连全连接都不需要了,直接融合
|
k=1,s=1,p=0 一层全连接 k=3,s=2,p=1 一层降采样 k=1,s=1,p=0 一层全连接 这是resnet的一个基本结构, k=1,s=1,p=0 核为1:一次卷住一个数据 步长1:一次移动一步 不补0:因为一次计算一个数据,且一次只走一步,图像长度为几,就走几步,不需要补0 图像中每个数据都参与了运算,这实际就是全连接, 并且变换之后的特征图大小与原图大小一致 k=3,s=2,p=1 为简化问题,假定图像长度为4,x=4 核为3:一次卷住三个数据 步长2: 一次移动二步,问题是只有四个数据,卷住了三个,只剩下一个,移动不了两步, 为了能够移动这两步,需要补0 p=1: 表示在图像的两边各补一个0,图像长度加2,4+2=6, 这下图像可以向前移动一步两个数据,到了3+2=5的位置, 还剩下一个0,无法凑齐一步,舍弃 计算公式 (x+2p-k)/s + 1 = (4+2*1-3)/2 + 1 =3/2 + 1 =1+1 =2 前面一次移动1个数据,特征图与原图大小一致 现在一次移动2个数据,特征图降为原图一半, 变相实现了降采样, 降采样通常由MAXPOOL实现,MAXPOOL本身是没有参数的,只是多选一, resnet使用卷积进行降采样,是带参数的, 意味降怎么降由参数决定, 这也许是resnet很深但信息丢失不严重的另外一个原因 |
|
消失的maxpool 后面的大模块没有使用maxpool, 在当时,2015年,maxpool可是相当的流行,现在依然如此, 能排除maxpool,不用它,必定是有它的理由的, 个人猜测这是因为模型开始进行了快速的收缩, 每个样本的信息量剩下3000多,而最后还要进行1000分类,信息量不算多, 再用maxpool怕是会信息丢失严重,这仅是个人猜测...如有雷同,纯属巧合... 随着特征变换,尤其是特征由少变多时, 64 -- 256 -- 512 -- 1024 那么特征shape就需要降低,不然信息量会极速膨胀 基于前面的推论,剩下3000多的信息量,不想再丢弃了 还有其他的方法,不用maxpool,即不丢失信息的情况下,收缩特征shape吗? 卷积就可以, - 一次取一个核, - 就是按固定的步长取一个窗口的做法,就是一个采样的方法, - 步长取大一点,就是下采样,没错,采样,才是核心 - maxpool的采样方式简单粗暴了一些,直接选最大的 - avgpool的采样方式没有舍弃任何信息,但何尝不就是固定了参数的卷积呢 - 换句话说,avgpool就是简化版的卷积,或者说他们的思想是一样的 - 所以k=3,s=2,p=1的设计,本来就有,收缩特征shape的作用
|
|
对比RNN 如果说图像领域的卷积自带特征shape收缩的特技,那么RNN怎么玩? RNN本质可是全连接啊... 如果让特征由少变多,特征图不收缩,还是全连接的情况下,好像玩不下去了... RNN是如何解决这个问题,注意力也是全连接,它又是怎么解决的, 更复杂的transformer使用RNN时,又是如何解决这个问题的? RNN,注意力,transformer处理的都是文本, 文本由句子组成,一句话就是一个样本,一句话的单词个数,就是特征shape 50就算长的了,在初始阶段,一句话20个单词,就很长了 也就是说,文本的特征shape不会像图像那样,动不动就成百上千个像素... 所以,文本的特征shape本身就不大, 如果一句话上百个单词,那普通人一口气也说不完, 既然说不完,那么一句话就不会有上百个单词... 再说特征的个数,特征应该取多少个? 对于文本来说,特征取多少的目的是什么? 特征,特征,就在这个“特”字, 特别,与众不同,能与其他同类事物区分开即为特 那么一个向量取多少维表示一个单词,可以让这个单词与其他单词区分开? 默认情况下,取100-300维,个人认为100维都太多了, 这可是2的100次方,还是数据只取0与1两个数的情况, 然而,实际的数据可以是浮点数,可以有正负,甚至是虚数 0.0003与0.1的差异是非常大的 100个这样的数,其表征的能力无疑是非常强大的 但考虑到这世界上语言种类的多样性,就这样吧... 这意味着,文本处理中样本对应的向量,不需要太多的维数, 通常512维就到底, 通常,向量以128维进入模型,也有先升后维的思想,但都不超过512维 像CV一样,网络有很多层, 也像resnet一样,每个模块都有一个升降,然后反反复复调用这个模块, 但特征数总体不超过512维, 文本处理中,通常有一个隐藏层,比如256层, 整个模型网络,以256为主线,特征数在其附近不断变换, 像有张力的网络一样,一收一张,256就是那个平衡位置... 至于特征图shape,整个文本类网络,特征图shape不变... 即一个句子有多少个单词,不变,不够时...补 所以RNN不存在信息量过大情况 - 特征数不会变的过大,一般不超过512 - 特征图shape一直不变 所以,在RNN网络中,没有maxpool也没啥大问题, 或者说,这就不算个问题,或者没有这个问题... |
|
|
四大模块
k=1,s=1,p=0 一层全连接,全连接没得说,必须k=1
k=3,s=2,p=1
- 一层降采样,要降,扔一半,
- 那么k=3实际上包含了扔掉的信息,
- 严格来说,这不算扔,并不像maxpool那样直接舍弃数据
- 而信息被压缩了,s=2是小于3的,而k=3,仍然有一格信息重叠
- 而第1个大模块中的k=3,s=1,p=1是信息的一种融合变换,当然了,专业名称是卷积
k=1,s=1,p=0 一层全连接
这是resnet的一个基本结构,
第一个大模块,s=1,不是s=2,意味着只是信息的整合,而没有舍弃
从后面的大模块开始s=2,不断舍弃信息,同时特征数不断上升
然后就是模块的不断重复,不断重复下面这个过程
- 维度变换
- 卷积提取特征
|
|
resnet第2-4个大模块
先跳过第一个大模块,从第2个大模块开始:
上来先一个三层小组合
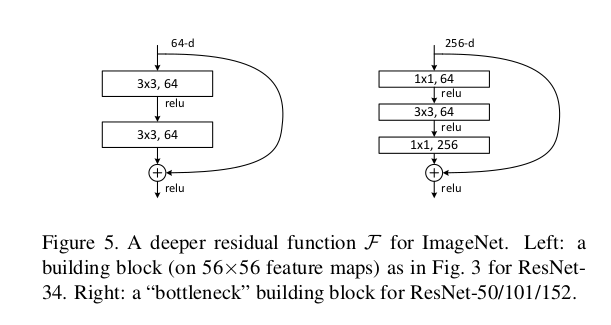
k=1,s=1,p=0 一层全连接,将通道数降一半,意思将扩大的通道数即数据维度降低,即抑制维度的膨胀,然后取出主要的信息
k=3,s=2,p=1 一层降采样,缩小特征图,因为维度总体在膨胀,实际上每张特征图的信息量必定是在减少的,
k=1,s=1,p=0 一层全连接,将通道数升四倍,进行一个维度扩大/膨胀,这是卷积网络中常用的先扩大再缩小的方法
短接操作,将上面三层小组合与线性变换后的x进行一次短接
短接后再跟上几个三层小组合,每个三层小组合都会与数据x本身进行一次短接
k=1,s=1,p=0 一层全连接,将通道数降一半,意思将扩大的通道数即数据维度降低,即抑制维度的膨胀,然后取出主要的信息
k=3,s=1,p=1 一层卷积,不改变特征图,这是典型的卷积核设计,
k=1,s=1,p=0 一层全连接,将通道数升四倍,进行一个维度扩大/膨胀,这是卷积网络中常用的先扩大再缩小的方法
第一个三层小组合与第二个三层小组合有以下区别:
1. 第一个完成了特征图的缩小,在卷积中特征图是必定要缩小的,
因为通道维度在不断扩大,势必造成每个通道对应特征图信息量减少
2. 短接的对象不一样;为什么不一样,下面的纯属个人猜测,如同雷同,纯属巧合:
第一次短接最接近数据的源头,其信息失真度最小,
我们知道一次线性变换就是从一个维度看数据,是数据在某个维度的展现,
将不同维度数据相加/融合,就是多尺度的概念
这里解释的不是短接,解释的是为什么两次短接的对象不一样,第一次体现了多尺度,
后面的短接全是x本身,
如果前面第一步是多尺度融合,那么后面的就相当于对数据x进行多次调整,
可以理解为x才是那个主线,
每个小三层都从其他维度变换计算一次,然后再加回x这个主线,
由于主线x的存在,就算某个小三层变换的方向偏了,或者网络过于深入,
最后也能回来,梯度不会消失
3. 后面的小三层为什么不进行多尺度了?
可能是因为后面的小三层所在网络已经很深了,信息早已不是原来的信息了,不合适使用多尺度了
4. 后面的小三层为什么不收缩特征图了?
在卷积神经网络中,通常一层卷积都会跟上一个MAXPOOL,
就是卷一次提取特征,再用MAXPOOL提到主要结构
resnet只在各个大模块的第一个小三层进行了降采样,其他的小三层而没有,只是线性变换
resnet诞生于图像分类比赛,这个比赛项目最终的分类是1000类,
resnet50有50层网络,每个大模块降一次,降到最后的全连接有2048个维度,这已经很接近1000类这个维度了
只需要一次全连接就转换过来了
由于最终有1000个分类,虽然resnet多次提升了维度,但每个模块降一次,也把维度快降到最终类别的维度了
|
|
resnet第1个大模块 resnet第1个大模块的输入是64维,并不像后面的大模块那样, 上来先降, 因为64维并不算多, 这也说明在设计一个模块的时候,要根据自己的实际情况, 要适当地变通 很多神经网络开始是升维,最后降维,而resnet有多次的升降, 升降 降升 降升 降升 四个大模块 |
|
特征图收缩占比
resnet有很多模块,大模块不断重复,大模块又分两个小模块
这两个小模块的作用也不一样
有s=2的就叫它特征图shape收缩,
k=3,s=1,p=1的就叫它特征变换
特征图shape收缩 与 特征变换的比例并不是1:1,而是
1:2
1:3
1:5
1:2
除了开头连续两次特征图shape收缩外,
后面每个大模块收缩一次,主体是特征变换...
信息量 特征图shape的边降为一半,面积降到原四分之一,信息量减去四分之三 这时,只有特征数提升四倍才能维持一个大模块在起始位置维数一致,才可以短接 若是特征数只升不降,那么特征数过多,向量就会过长,这是没有必要的,也不利于计算机计算 因此大模块接口对接时,特征数降一半; 但要只是这样的话,这网络不算太深,基本提现不出短接的价值, 于是,大模块内又增加了小模块的循环,尤其是311标准提取特征的循环... 大模块 输入 输出 2 128*56*56=401408 512*28*28=401408 3 256*28*28=200704 1024*14*14=200704 4 512*14*14=100352 2048*7*7=100352 avgpool 2048*1*1 FC 1000 |
|
|
|
|
resnet 短接
|
短接是为了解决梯度消失的问题 随着深度学习层数变多,梯度在多重0-1之间的数据上进行运算,类似 0.1*0.1*0.1*...* 这是越乘越小,然后数据就没有了,这就是梯度消失 短接后的梯度计算 0.1 + 0.1*0.1*0.1*... 那个深层次梯度消失没关系,短接网络的梯度还在 整个resnet四个大模块,梯度起主要作用的是每个大模块第一个小三层 从梯度不消失的角度看,resnet50虽然有50层网络, 但主要梯度不消失的计算只有四层,即每个大模块第一个小三层 w = w - 0.001*data.grad data.grad提供了数据改变的方向 可以认为梯度消失慢的层的参数改变快, 而梯度快消失那些网络层的参数在以非常慢的速度在改变, 即每个大模块的第一个小三层在以非常快的速度调整着参数, 每个大模块后面的小三层在以非常慢的速度调整着参数
相加之后,参数数据改变了,同时梯度也没有消失...
|
自然思路下,短接是相加,那么直接 + 一下就好了 但落实下去就会发现,网络网络有许多的层,每个层的特征维度不一样,就没法加 要相加,就需要两个矩阵的维度/shape一致, 同时,这是不同层数上数据矩阵的相加, 那么就必然会出现一条线的不同的节点位置有相同维数的设计 并且这个短接必定是贯穿整个网络的, - 任何一段网络缺少短接,就会导致整个网络的梯度消失 - 那么前面的短接就失去了意义 从数据的变化上看,短接的线,涉及的层数不深,数据变化不大 每个短接都会附加一段更深的网络,以增加网络的复杂度
后续如果网络变得更加复杂,在这个已有的思路基础上,可以有两个方向
- 每个短接不再是附加一段网络,可以是多段不同的网络设计
- 短接的这条线,也可以采用更丰富的设计方式,不再是一个全连接维度变换就完事了
|
|
|
|
|
|
|
resnet 实现
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
# from torch.utils.data import DataLoader
# from torchvision import datasets
# from torchvision.transforms import Compose
# from torchvision.transforms import Resize
# from torchvision.transforms import ToTensor
# from torchvision.transforms import Normalize
class SmallBlock(nn.Module):
"""
三层一模块
"""
def __init__(self, in_channel, out_channel, stride, first=False):
"""
params
-----------------------
- in_channel: 模块输入通道数
- out_channel:模块输出通道数
- stride:每个模块第二层步长,如果有短接层,也指短接层的步长
- first:是否为resnet中每一个大模块中的第一个小模块;若是则有一个短接操作,反之直接与输入数据x短接
"""
# 中间模块是输出模块通道数的四分之一
middle_channel = out_channel//4
self.first = first
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(in_channels=in_channel, out_channels=middle_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=middle_channel),
nn.ReLU(),
nn.Conv2d(in_channels=middle_channel, out_channels=middle_channel, kernel_size=3, stride=stride, padding=1),
nn.Conv2d(in_channels=middle_channel, out_channels=out_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channel)
)
self.short = nn.Sequential(
nn.Conv2d(in_channels=in_channel,
out_channels=out_channel,
kernel_size=1,
stride=stride,
padding=0),
nn.BatchNorm2d(num_features=out_channel)
)
def forward(self, x):
# 短接分支
if self.first: # 第一个模块与变换后的x短接
h1 = self.short(x)
else:
h1 = x # 后续模块与x本身短接
# 主分支
h2 = self.main(x)
# 短接操作
h = h1 + h2
o = F.relu(h)
return o
"""
定义模型
"""
class ResNet50(nn.Module):
"""
自定义ResNet
"""
def __init__(self):
super().__init__()
# 头部
self.head = nn.Sequential(
# (224 +2*3 - 7)/2 + 1 = 112.5 = 112
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
# (112 + 2*1 - 3)/2 + 1 = 56.5 = 56
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 第一个大模块,三个小三层,输出256*56*56
self.block1 = nn.Sequential(
SmallBlock(in_channel=64, out_channel=256, stride=1, first=True),
SmallBlock(in_channel=256, out_channel=256, stride=1),
SmallBlock(in_channel=256, out_channel=256, stride=1),
)
# 第二个大模块,四个小三层, 输出512*28*28
self.block2 = nn.Sequential(
SmallBlock(in_channel=256, out_channel=512, stride=2, first=True),
SmallBlock(in_channel=512, out_channel=512, stride=1),
SmallBlock(in_channel=512, out_channel=512, stride=1),
SmallBlock(in_channel=512, out_channel=512, stride=1)
)
# 第三个大模块,六个小三层,输出1024×14×14
self.block3 = nn.Sequential(
SmallBlock(in_channel=512, out_channel=1024, stride=2, first=True),
SmallBlock(in_channel=1024, out_channel=1024, stride=1),
SmallBlock(in_channel=1024, out_channel=1024, stride=1),
SmallBlock(in_channel=1024, out_channel=1024, stride=1),
SmallBlock(in_channel=1024, out_channel=1024, stride=1),
SmallBlock(in_channel=1024, out_channel=1024, stride=1)
)
# 第四个大模块,六个小三层,输出2048×7×7
self.block4 = nn.Sequential(
SmallBlock(in_channel=1024, out_channel=2048, stride=2, first=True),
SmallBlock(in_channel=2048, out_channel=2048, stride=1),
SmallBlock(in_channel=2048, out_channel=2048, stride=1),
)
# 2048×1×1
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
# classifier
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=2048, out_features=1000)
)
def forward(self, x):
# [B, 3, 224, 224] - [B, 64, 56, 56]
x = self.head(x)
# [B, 64, 56, 56] - [B, 256, 56, 56]
x = self.block1(x)
# [B, 256, 56, 56] - [B, 512, 28, 28]
x = self.block2(x)
# [B, 512, 28, 28] - [B, 1024, 14, 14]
x = self.block3(x)
# [B, 1024, 14, 14] - [B, 2048, 7, 7]
x = self.block4(x)
# [B, 2048, 1, 1]
x = self.avgpool(x)
# [B, 2048] -- [B, 1000]
x = self.classifier(x)
return x
|
|
cifar10
from tpf.datasets import local_cifar10_train
from torch.utils.data import DataLoader
train_dataset=local_cifar10_train()
train_dataloader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
from tpf.datasets import local_cifar10_test test_dataset = local_cifar10_test() test_dataloader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False) |
from tpf.datasets import local_cifar10_train from torch.utils.data import DataLoader train_dataset=local_cifar10_train() train_dataloader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
model = ResNet50()
for X,y in train_dataloader:
print(X.shape,y.shape) #torch.Size([32, 3, 224, 224]) torch.Size([32])
y_out = model(X)
print(y_out.shape) #torch.Size([32, 1000])
break
|
|
|
|
|
resnet实现·版本2
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import Compose
from torchvision.transforms import Resize
from torchvision.transforms import ToTensor
from torchvision.transforms import Normalize
class ConvBlock(nn.Module):
"""
第一个短接模块
"""
def __init__(self, in_channel, out_channels, stride):
"""
in_channel: 1个数
out_channels:2个数
"""
super(ConvBlock, self).__init__()
self.stage = nn.Sequential(
# Conv1
nn.Conv2d(in_channels=in_channel, out_channels=out_channels[0], kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channels[0]),
nn.ReLU(),
# Conv2 注意stride
nn.Conv2d(in_channels=out_channels[0], out_channels=out_channels[0], kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(num_features=out_channels[0]),
nn.ReLU(),
# Conv1 注意stride
nn.Conv2d(in_channels=out_channels[0], out_channels=out_channels[1], kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channels[1])
)
self.short_cut = nn.Sequential(
nn.Conv2d(in_channels=in_channel,
out_channels=out_channels[1],
kernel_size=1,
stride=stride,
padding=0),
nn.BatchNorm2d(num_features=out_channels[1])
)
def forward(self, x):
# 短接分支
h1 = self.short_cut(x)
# 主分支
h2 = self.stage(x)
# 短接操作
h = h1 + h2
# 最终ReLU
o = F.relu(h)
return o
class IdentityBlock(nn.Module):
"""
第二个短接模块
"""
def __init__(self, in_channel, inner_channel):
"""
in_channel: 1个数
inner_channel:1个数
"""
super(IdentityBlock, self).__init__()
self.stage = nn.Sequential(
# Conv1
nn.Conv2d(in_channels=in_channel, out_channels=inner_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
# Conv2 注意stride
nn.Conv2d(in_channels=inner_channel, out_channels=inner_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
# Conv1 注意stride
nn.Conv2d(in_channels=inner_channel, out_channels=in_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=in_channel)
)
def forward(self, x):
# 主分支
h = self.stage(x)
# 短接操作
h = h + x
# 最终ReLU
o = F.relu(h)
return o
class ResNet50(nn.Module):
"""
自定义ResNet
"""
def __init__(self):
super(ResNet50, self).__init__()
# 头部
self.head = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# stage1
self.stage1 = nn.Sequential(
ConvBlock(in_channel=64,out_channels=[64, 256], stride=1),
IdentityBlock(in_channel=256, inner_channel=64),
IdentityBlock(in_channel=256, inner_channel=64)
)
# stage2
self.stage2 = nn.Sequential(
ConvBlock(in_channel=256,out_channels=[128, 512], stride=2),
IdentityBlock(in_channel=512, inner_channel=128),
IdentityBlock(in_channel=512, inner_channel=128),
IdentityBlock(in_channel=512, inner_channel=128)
)
# stage3
self.stage3 = nn.Sequential(
ConvBlock(in_channel=512,out_channels=[256, 1024], stride=2),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256)
)
# stage4
self.stage4 = nn.Sequential(
ConvBlock(in_channel=1024,out_channels=[512, 2048], stride=2),
IdentityBlock(in_channel=2048, inner_channel=512),
IdentityBlock(in_channel=2048, inner_channel=512)
)
# 在某种程度,可以部分实现输入任意大小的图像
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
# classifier
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=2048, out_features=1000)
)
def forward(self, x):
# [B, 3, 224, 224] -- [B, 64, 56, 56]
x = self.head(x)
# [B, 64, 56, 56] -- [B, 256, 56, 56]
x = self.stage1(x)
# [B, 256, 56, 56] -- [B, 512, 28, 28]
x = self.stage2(x)
# [B, 512, 28, 28] -- [B, 1024, 14, 14]
x = self.stage3(x)
# [B, 1024, 14, 14] -- [B, 2048, 7, 7]
x = self.stage4(x)
# [B, 2048, 1, 1]
x = self.avgpool(x)
# [B, 2048] -- [B, 1000]
x = self.classifier(x)
return x
data = torch.randn(2,3,224,224)
model = ResNet50()
model(data)
|
|
打包数据
# 定义数据预处理
transforms = Compose(transforms=[Resize(size=(224, 224)),
ToTensor(),
Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])])
# train_dataloader
train_dataset = datasets.CIFAR100(root="cifar100", train=True, transform=transforms, download=True)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
# test_dataloader
test_dataset = datasets.CIFAR100(root="cifar100", train=False, transform=transforms, download=True)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False)
|
# 检测是否有GPU device = "cuda:0" if torch.cuda.is_available() else "cpu" device # 构建模型 resnet50 = ResNet50() # 参数搬家 resnet50.to(device=device) # 定义损失函数 loss_fn = nn.CrossEntropyLoss() # 定义优化器 optimizer = torch.optim.SGD(params=resnet50.parameters(), lr=1e-3) 过程监控
def get_acc(dataloader, model=resnet50):
"""
测试准确率
"""
model.eval()
accs = []
with torch.no_grad():
for X, y in dataloader:
# 数据搬家
X = X.to(device=device)
y = y.to(device=device)
# 正向推理
y_pred = model(X)
# 结果解析
y_pred = y_pred.argmax(dim=1)
# 准确率计算
accs.append((y_pred == y).float().mean().item())
return round(np.array(accs).mean(), ndigits=3)
训练
def train(dataloader=train_dataloader, model=resnet50, loss_fn=loss_fn, optimizer=optimizer, epochs=5):
"""
训练过程
"""
print(f"自然概率:{get_acc(dataloader=test_dataloader)}")
for epoch in range(1, epochs+1):
model.train()
for X, y in dataloader:
# 数据搬家
X = X.to(device=device)
y = y.to(device=device)
# 正向传播
y_pred = model(X)
# 计算损失
loss = loss_fn(y_pred, y)
# 梯度清空
optimizer.zero_grad()
# 反向传播
loss.backward()
# 向前优化一步
optimizer.step()
# 此处添加模型保存代码(注意命名,不要把老的模型覆盖了)
print(f"Epoch: {epoch}, Tran_Acc:{get_acc(dataloader=train_dataloader)}, Test_Acc:{get_acc(dataloader=test_dataloader)}" )
train() 自然概率:0.0 Epoch: 1, Tran_Acc:0.082, Test_Acc:0.083 Epoch: 2, Tran_Acc:0.127, Test_Acc:0.126 |
|
|
|
|
resnet实现·版本3
- 修改 - 第2个大模型,去掉了一个全连接 - 感觉第2个全连接也可以去掉
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import Compose
from torchvision.transforms import Resize
from torchvision.transforms import ToTensor
from torchvision.transforms import Normalize
定义模型
class ConvBlock(nn.Module):
"""
第一个短接模块
"""
def __init__(self, in_channel, out_channels, stride):
"""
in_channel: 1个数
out_channels:2个数
"""
super(ConvBlock, self).__init__()
self.stage = nn.Sequential(
# Conv1
nn.Conv2d(in_channels=in_channel, out_channels=out_channels[0], kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channels[0]),
nn.ReLU(),
# Conv2 注意stride
nn.Conv2d(in_channels=out_channels[0], out_channels=out_channels[0], kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(num_features=out_channels[0]),
nn.ReLU(),
# Conv1 注意stride
nn.Conv2d(in_channels=out_channels[0], out_channels=out_channels[1], kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channels[1])
)
self.short_cut = nn.Sequential(
nn.Conv2d(in_channels=in_channel,
out_channels=out_channels[1],
kernel_size=1,
stride=stride,
padding=0),
nn.BatchNorm2d(num_features=out_channels[1])
)
def forward(self, x):
# 短接分支
h1 = self.short_cut(x)
# 主分支
h2 = self.stage(x)
# 短接操作
h = h1 + h2
# 最终ReLU
o = F.relu(h)
return o
class IdentityBlock(nn.Module):
"""
第二个短接模块
"""
def __init__(self, in_channel, inner_channel):
"""
in_channel: 1个数
inner_channel:1个数
"""
super(IdentityBlock, self).__init__()
self.stage = nn.Sequential(
# Conv2 注意stride
nn.Conv2d(in_channels=in_channel, out_channels=inner_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
# Conv1 注意stride
nn.Conv2d(in_channels=inner_channel, out_channels=in_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=in_channel)
)
def forward(self, x):
# 主分支
h = self.stage(x)
# 短接操作
h = h + x
# 最终ReLU
o = F.relu(h)
return o
class ResNet50(nn.Module):
"""
自定义ResNet
"""
def __init__(self):
super(ResNet50, self).__init__()
# 头部
self.head = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# stage1
self.stage1 = nn.Sequential(
ConvBlock(in_channel=64,out_channels=[64, 256], stride=1),
IdentityBlock(in_channel=256, inner_channel=64),
IdentityBlock(in_channel=256, inner_channel=64)
)
# stage2
self.stage2 = nn.Sequential(
ConvBlock(in_channel=256,out_channels=[128, 512], stride=2),
IdentityBlock(in_channel=512, inner_channel=128),
IdentityBlock(in_channel=512, inner_channel=128),
IdentityBlock(in_channel=512, inner_channel=128)
)
# stage3,在1024的维度上做了最多的变换
self.stage3 = nn.Sequential(
ConvBlock(in_channel=512,out_channels=[256, 1024], stride=2),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256),
IdentityBlock(in_channel=1024, inner_channel=256)
)
# stage4
self.stage4 = nn.Sequential(
ConvBlock(in_channel=1024,out_channels=[512, 2048], stride=2),
IdentityBlock(in_channel=2048, inner_channel=512),
IdentityBlock(in_channel=2048, inner_channel=512)
)
# 在某种程度,可以部分实现输入任意大小的图像
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
# classifier
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=2048, out_features=1000)
)
def forward(self, x):
# [B, 3, 224, 224] -- [B, 64, 56, 56]
x = self.head(x)
# [B, 64, 56, 56] -- [B, 256, 56, 56]
x = self.stage1(x)
# print(x.shape)
# [B, 256, 56, 56] -- [B, 512, 28, 28]
x = self.stage2(x)
# [B, 512, 28, 28] -- [B, 1024, 14, 14]
x = self.stage3(x)
# [B, 1024, 14, 14] -- [B, 2048, 7, 7]
x = self.stage4(x)
# [B, 2048, 1, 1]
x = self.avgpool(x)
# [B, 2048] -- [B, 1000]
x = self.classifier(x)
return x
|
|
修改前
class IdentityBlock(nn.Module):
"""
第二个短接模块
"""
def __init__(self, in_channel, inner_channel):
"""
in_channel: 1个数
inner_channel:1个数
"""
super(IdentityBlock, self).__init__()
self.stage = nn.Sequential(
# Conv1
nn.Conv2d(in_channels=in_channel, out_channels=inner_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
# Conv2 注意stride
nn.Conv2d(in_channels=inner_channel, out_channels=inner_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
# Conv1 注意stride
nn.Conv2d(in_channels=inner_channel, out_channels=in_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=in_channel)
)
def forward(self, x):
# 主分支
h = self.stage(x)
# 短接操作
h = h + x
# 最终ReLU
o = F.relu(h)
return o
修改后
class IdentityBlock(nn.Module):
"""
第二个短接模块
"""
def __init__(self, in_channel, inner_channel):
"""
in_channel: 1个数
inner_channel:1个数
"""
super(IdentityBlock, self).__init__()
self.stage = nn.Sequential(
# Conv2 注意stride
nn.Conv2d(in_channels=in_channel, out_channels=inner_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
# Conv1 注意stride
nn.Conv2d(in_channels=inner_channel, out_channels=in_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=in_channel)
)
def forward(self, x):
# 主分支
h = self.stage(x)
# 短接操作
h = h + x
# 最终ReLU
o = F.relu(h)
return o
去掉了下面的全连接
# Conv1
nn.Conv2d(in_channels=in_channel, out_channels=inner_channel, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=inner_channel),
nn.ReLU(),
去掉的理由
提取特征的角度分析
- 全连接与卷积同是提取特征,并无本质的不同,
- 有卷积在就可以了,无需再使用全连接变换维度提取特征
主线角度
- 在主线上已经有一个全连接了
- 辅线上的全连接层有点冗余
以上理由只是个人感觉
去掉的效果
train()
自然概率:0.0
Epoch: 1, Tran_Acc:0.145, Test_Acc:0.142
Epoch: 2, Tran_Acc:0.194, Test_Acc:0.187
前两轮收敛的速度更快了...
|
resnet中,维度的变换 - 有几个地方是同维度变换 - 之后再升,然后再降 这是一个小轮回,有一定理论支撑,但工程效果有待验证 - 当然了,现在transformer已经出来了,内部皆是同维度变换,这一点实践验证了 - 这也间接证明了,这种先升后降,但主体是升的思路,可能有点绕了 - 工程上直接升到一个维度,比如512,然后反反复复提特征即可,不需要再升升降降了 - 这也意味着,去掉第二个全连接,然后增加循环的次数,也是可以行的 以上只是个人想法,resnet现在只是一个demo,后面还有很多知识要学... 时间有限,临时记录一下想法,有时间再回来验证吧... |
|
|
|
|
参考
【计算机视觉 | 图像模型】常见的计算机视觉 image model(CNNs & Transformers) 的介绍合集(十)