CRF简易说明
|
pip install sklearn-crfsuite
一个序列到另外一个序列,这是NLP做的事,也叫seq to seq
NLP是深度学习模型,
机器学习模型中能处理序列前后关系的还有HMM,但HMM只考虑前后依赖
CRF可考虑上下文,但还是一个序列到序列
CRF对数据集的要求 - python 列表 - 元素为字符串 - 训练集与标签,元素个数要对上 [["准备","吃饭"]] -- ["走起","<PAD>"] 标签只有一个单词,用个标签补一下 数据矩阵化时,通常都对齐,不足的填补一下 |
X=[["你","几点","上班"],["你","几点","下班"],["你","开心","吗"]]
y=[["八点","半","<PAD>"],["五点","半","<PAD>"],["别","问","这个"]]
X_train = []
for val in X:
X_train.append([str(x.encode('utf-8')) for x in val])
y_train = []
for val in y:
y_train.append([str(x.encode('utf-8')) for x in val])
from sklearn_crfsuite import CRF
import numpy as np
# 定义CRF模型
crf = CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
# 训练模型
crf.fit(X_train, y_train)
# 就简单点,直接拿训练做测试
X_test = X_train
# 预测
y_pred = crf.predict(X_test)
for val in y_pred:
print([eval(v).decode('utf-8') for v in val])
['八点', '半', '<PAD>'] ['八点', '半', '<PAD>'] ['别', '问', '这个']
注意,第二句预测的不对,看来上下文处理能力还是没有RNN强
三句话,第一个单词就是你,最后一个序列预测正常,说明有一定上下文处理能力
如果我把数据集改为下面的内容,即针对错误,增加五点半出现的概率
X=[["你","几点","上班"],["你","几点","下班"],["你","几点","下班"],["你","开心","吗"]]
y=[["八点","半","<PAD>"],["五点","半","<PAD>"],["五点","半","<PAD>"],["别","问","这个"]]
预测结果为,充分显示了CRF按概率办事的特点
['五点', '半', '<PAD>']
['五点', '半', '<PAD>']
['五点', '半', '<PAD>']
['别', '问', '这个']
总结 CRF处理序列的能力差: 概率大者会被选择 |
|
x*x +2*x+1
X = [
[1, 1, 0, 2, 0, 0],
[0, 1, 1, 0, 4, 0],
[0, 0, 1, 1, 0, 8],
[0, 3, 0, 0, 1, 1],
]
X_train = []
y_train = []
for word_index in X:
X_train.append([str(x) for x in word_index])
y_train.append([str(x*x +2*x+1) for x in word_index])
from sklearn_crfsuite import CRF
import numpy as np
# 定义CRF模型
crf = CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
# 训练模型
crf.fit(X_train, y_train)
# 就简单点,直接拿训练做测试
X_test = X_train
# 预测
y_pred = crf.predict(X_test)
print(np.array(y_pred))
[['4' '4' '1' '9' '1' '1'] ['1' '4' '4' '1' '25' '1'] ['1' '1' '4' '4' '1' '81'] ['1' '16' '1' '1' '4' '4']] y_train [['4', '4', '1', '9', '1', '1'], ['1', '4', '4', '1', '25', '1'], ['1', '1', '4', '4', '1', '81'], ['1', '16', '1', '1', '4', '4']] 为什么公式会预测的这么准?
因为公式完全,100%是一对一/多对一,
即对于给定的x,有唯一的y与之对应,
从概率的角度讲,
1对应4的概率是100%,
0对应1的概率是100%,
...
不重不漏,相互独立,准的不能再准了...
即只要能满足,对于x有唯一的y,
别说一元2次方程了,
不管这公式有多复杂,都100%预测正确
|
CRF
|
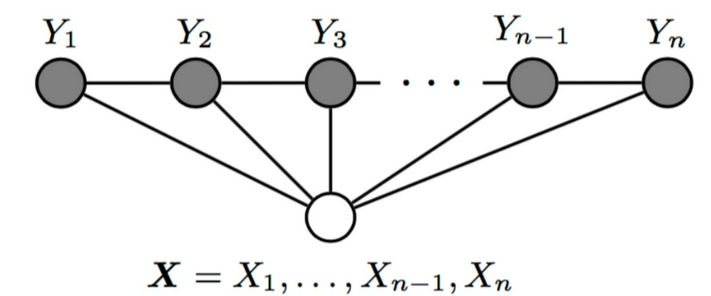
条件随机场CRF模型 条件随机场(CRF)是一种用于建模 输入序列与输出序列 之间的依赖关系的 统计模型。 CRF广泛应用于各种自然语言处理任务,如词性标注、命名实体识别和语义角色标注等。 CRF的主要优点是能够明确地建模观测数据与标签之间的依赖关系, 同时考虑整个序列的上下文信息。
CRF基于图模型,其中输入序列表示为节点,依赖关系表示为边。
CRF的主要目标是学习一个条件概率分布,用于预测输出序列中的标签。
具体而言,给定输入序列𝑥和输出序列𝑦,CRF试图通过最大化条件概率𝑃(𝑦|𝑥)来学习权重参数。
|
|
优点:处理简单的映射关系没有问题
1.模型表现力强:CRF能够对标记之间的依赖关系建模,因此能够处理更加复杂的序列标注任务。
2.预测准确率高:CRF对于模型训练和预测都采用了统计学习的方法,所以预测准确率相对比较高。
3.可解释性强:CRF的特征函数定义比较直观,因此可以帮助我们理解模型的预测过程。
缺点
1.训练速度比较慢:CRF需要对整个训练集进行参数估计,时间复杂度较高,对于大规模数据集训练过程比较缓慢。
2.特征选择比较困难:CRF的性能比较依赖于特征函数的选择和设计,因此需要手动设计特征函数。
3.对于没有显式标记的数据来说准确率会比较低。
|
|
处理简单的映射关系没问题的 条件随机场(Conditional Random Fields,CRF)是一种机器学习模型,用于处理序列标注问题。 在给定一组输入随机变量条件下,CRF可以预测另外一组输出随机变量的条件概率分布。这种模型在自然语言处理(NLP)和图像处理等领域有着广泛的应用。 以自然语言处理中的命名实体识别(Named Entity Recognition,NER)为例,CRF可以用于识别文本中的实体,如人名、地名、组织名等。在这个任务中,输入随机变量可以是文本中的单词或字符,输出随机变量则是每个单词或字符的实体标签。 假设我们有一个简单的命名实体识别任务,输入文本为“John Doe works at Google in Mountain View”,目标是识别出人名“John Doe”和公司名“Google”。我们可以使用CRF来完成这个任务。
首先,我们需要定义特征函数,用于提取输入文本中的特征。例如,我们可以定义以下特征函数:
如果当前单词的首字母大写,则特征值为1,否则为0。
如果当前单词的前一个单词是介词(如“at”、“in”等),则特征值为1,否则为0。
然后,我们可以使用这些特征函数来构建CRF模型。在训练阶段,我们使用标注好的数据来训练模型,学习条件概率分布P(Y|X),其中X是输入序列(文本中的单词或字符),Y是输出序列(实体标签)。在测试阶段,给定一个新的输入序列,我们可以使用训练好的CRF模型来预测其对应的输出序列。
具体来说,对于每个位置i上的单词或字符,CRF会计算一个状态转移概率矩阵Mi(x),其中Mi(x)[j,k]表示在状态j下,下一个状态为k的概率。同时,CRF还会计算一个发射概率矩阵E(x),其中E(x)[j,l]表示在状态j下,输出标签为l的概率。在给定输入序列X和初始状态y0=start的情况下,CRF可以使用动态规划算法计算出最可能的状态序列Y,即使得条件概率P(Y|X)最大的序列Y。
以上就是使用CRF进行命名实体识别的基本流程和示例。
通过调整特征函数和模型参数,我们可以进一步提高CRF在命名实体识别等任务上的性能。
|
参考
人工智能基础部分18-条件随机场CRF模型的应用