决策树-示例
iris分类
import joblib
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from tpf.datasets import load_iris
X_train, y_train, X_test, y_test = load_iris()
# 模型定义
model = DecisionTreeClassifier(criterion="gini", max_depth=5)
# 训练
model.fit(X=X_train,y=y_train)
# 预测
model.predict(X=X_test)
# 保存
# 模型保存推荐使用joblib
joblib.dump(model,"model1.pkl")
决策树特征重要性
取一个与列名列表同长的空列表,初始化为0 - list_a
取每次训练后模型对象的列重要性,有贡献的,即非0的,
list_a中同索引位置上元素值+1
经过多轮训练后,list_a中非0元素对应的索引位置是出现过的有贡献的列
并且元素值越大,索引对应的列出现的次数就越多,就越重要
import joblib import numpy as np from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import make_classification # 模型定义 model = DecisionTreeClassifier(criterion="gini", max_depth=10)
# 该列表与原数据X列长度一致,索引一一对应,
#index=0上的元素值记录原数据X第1列c0的重要性
col_feature_importance=[]
def get_feature_col(model, X, y, col_feature_importance=col_feature_importance):
model.fit(X,y)
fti = model.feature_importances_
fti_len = len(fti)
if len(col_feature_importance)==0:
for i in range(fti_len):
col_feature_importance.append(0)
#原列重要性列表 索引倒序排列
feature_index_desc = np.argsort(fti)[::-1]
#将有贡献的列加1,积计,每次有贡献,都+1
for i in range(fti_len):
index_pos =feature_index_desc[i] #原列索引
if fti[index_pos]==0:#直到一个列无任何贡献价值
print(f"前{i+1}列有贡献")
break
else:
#索引位置重要的话,其对应的值加1
col_feature_importance[index_pos] = col_feature_importance[index_pos]+1
#原列的索引
index_0=0
for i in range(fti_len):
index_pos =feature_index_desc[i]
if fti[index_pos] == 0:
print(f"重要性0边界,第{i}列={fti[feature_index_desc[i-1]]},第{i+1}列={fti[index_pos]}\n")
index_0=i
break
return index_0
for i in range(10):
X,y = make_classification(n_samples=1000,n_features=1000,n_classes=2,)
get_feature_col(model, X, y, col_feature_importance=col_feature_importance)
前33列有贡献 重要性0边界,第32列=0.002841686278474346,第33列=0.0 前42列有贡献 重要性0边界,第41列=0.002742788373681267,第42列=0.0 前30列有贡献 重要性0边界,第29列=0.0028047494907260215,第30列=0.0 前28列有贡献 重要性0边界,第27列=0.0027717783308147887,第28列=0.0 前29列有贡献 重要性0边界,第28列=0.0026667626701227906,第29列=0.0 前27列有贡献 重要性0边界,第26列=0.0019895912916985093,第27列=0.0 前34列有贡献 重要性0边界,第33列=0.002792203036202943,第34列=0.0 前16列有贡献 重要性0边界,第15列=0.003862130759609392,第16列=0.0 前40列有贡献 重要性0边界,第39列=0.002742001881910139,第40列=0.0 前30列有贡献 重要性0边界,第29列=0.0027097095899495448,第30列=0.0
len(col_feature_importance)
1000
取非零列,即有贡献的列
def get_used_cols(col_feature_importance, max_cols=200, arise_atleast=1):
"""
params
- arise_atleast=2 至少出现过两次
"""
#取前N个重要列
col_feature_desc = np.argsort(col_feature_importance)[::-1]
# 非0重要性列
col_feature_not0=[]
#取非0重要列
for i in range(len(col_feature_desc)):
index_value_desc = col_feature_desc[i]
importance_value = col_feature_importance[index_value_desc]
if importance_value<arise_atleast:
print(i)
col_feature_not0=col_feature_desc[:i]
break
use_cols = col_feature_not0[:max_cols]
return use_cols
总列1000,10次训练,至少出现过一次的列有263个
used_cols = get_used_cols(col_feature_importance, max_cols=200)
len(used_cols)
263
200
arise_atleast=2,至少出现过两次的列 used_cols = get_used_cols(col_feature_importance, max_cols=200,arise_atleast=2) len(used_cols) 34 34
总共1000次,至少出现过一次列有263个,至少出现过两次的列有34个
可以分别测试使用34个列与使用263个列的效果
- 精度
- 性能
|
|
特征重要性与输入的列位置一一对应 import numpy as np from sklearn.tree import DecisionTreeClassifier from ai.datasets import load_iris X_train, y_train, X_test, y_test = load_iris() model = DecisionTreeClassifier(criterion="gini", max_depth=5) model.fit(X=X_train,y=y_train) # print(model.feature_importances_) """ [0.01667014 0.03000625 0.41991615 0.53340746] """ a = np.random.randint(-3,3,size=120).reshape(-1,1) b = np.random.randint(-3,3,size=120).reshape(-1,1) c = np.random.randint(-3,3,size=120).reshape(-1,1) X_train = np.concatenate([X_train[:,:2],a,X_train[:,2:],b,c],axis=1) model = DecisionTreeClassifier(criterion="gini", max_depth=5) model.fit(X=X_train,y=y_train) m = model.feature_importances_ a=np.argsort(m)[::-1] cols = ["真1","真2","假1","真3","真4","假2","假3"] np.array(cols)[a][:2].tolist() # ['真3', '真4'] |
决策树分类
预测结果与标签的对应关系
import numpy as np from sklearn.tree import DecisionTreeClassifier from ai.datasets import load_iris X_train, y_train, X_test, y_test = load_iris() model = DecisionTreeClassifier(criterion="gini", max_depth=5) model.fit(X=X_train,y=y_train) print(model.predict(X=X_test)) """ [1, 0, 2, 0, 1, 1, 0, 2, 1, 2, 2, 2, 0, 0, 0, 2, 1, 2, 1, 2, 2, 2, 2, 0, 2, 1, 0, 0, 0, 0] """ predict返回的是标签one-hot向量预测类别的索引下标 predict_proba返回的是标签向量 model.predict_proba(X=X_test) """ [[0., 1., 0.], [1., 0., 0.], [0., 0., 1.], [1., 0., 0.], ... ... [1., 0., 0.]] """
主要参数
|
决策树DecisionTreeClassifier的算法原理
决策树是一种类似于树的结构,
其中
每个内部节点表示一个属性上的划分,
每个分支代表一个方向的输出,是二叉树,每个节点最多两个分支,
每个叶节点代表一种类别。
决策树的学习过程包括特征选择、决策树生成和决策树剪枝。
特征选择:
在于选取对训练数据具有分类能力的特征。为了提高决策树学习的效率,就需要决定使用哪些特征来划分特征空间。具体的方法有:信息增益、信息增益比、基尼指数等。
信息增益:表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
信息增益比:是信息增益和特征熵的比值。
基尼指数:表示在特征X的条件下,集合D的纯度。基尼指数越小,表示集合D的纯度越高。
决策树的生成:
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可再分则停止。
这一过程形成的决策树往往对训练数据的拟合很好,
但对未知的测试数据的分类效果可能不理想,
即出现过拟合现象。
因此,需要通过剪枝来解决这个问题。
决策树的剪枝:决策树剪枝的基本策略有“预剪枝”和“后剪枝”。
预剪枝:
是指在决策树生成过程中,对每个节点在划分前先进行估计,
若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点。
后剪枝:
是指先从训练集生成一棵完整的决策树,
然后自底向上地对非叶节点进行考察,
若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点。
|
criterion:
特征选择标准,用于决定不纯度的计算方法,
可选'entropy'(信息熵)或'gini'(基尼系数)。
在实际使用中,两者的效果基本相同。
默认值为'gini'。
splitter:
特征划分标准,可选'best'或'random'。
'best'表示在特征的所有划分点中找出最优的划分点;
'random'表示随机的在部分划分点中找局部最优的划分点。
当样本量不大时,推荐使用'best';
而当样本数据量非常大时,推荐使用'random'以加快训练速度。
默认值为'best'。
max_depth:
决策树的最大深度。
如果模型样本数量多、特征也多时,推荐限制这个最大深度以防止过拟合。
常用的取值范围在10~100之间,具体取值取决于数据的分布。
默认值为None,表示决策树会生长到 衡量不纯度的指标最优 或没有更多的特征 可用为止。
min_samples_split:
内部节点(即判断条件)再划分所需最小样本数。
这个值限制了子树继续划分的条件,
如果某节点的样本数少于min_samples_split,则不会继续划分。
默认值为2。
min_samples_leaf:
叶子节点(即分类)最少样本数。
这个值限制了叶子节点最少的样本数,
如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
默认值为1。
min_weight_fraction_leaf:
叶子节点最小的样本权重和。
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。
默认值为0,表示不考虑权重问题,所有样本的权重相同。
max_features:
在划分数据集时考虑的最多的特征值数量。这个值限制了每次划分时考虑的特征数量,有助于防止过拟合。可选int值或float值(表示百分数)。默认值为None,表示划分时考虑所有特征。
random_state:随机种子数。设置随机数种子可以使得结果可以被复现。默认值为None。
max_leaf_nodes:最大叶子节点数。通过设置最大叶子节点数,可以防止过拟合。默认值为None,表示不限制最大叶子节点数。
min_impurity_decrease:节点划分最小不纯度。这个值限制了决策树的增长,如果节点的不纯度(基尼系数、信息增益等)减小量小于这个阈值,则不会继续划分。默认值为0。
此外,还有一些已被弃用或较少使用的参数,如min_impurity_split(已在0.19版本中被min_impurity_decrease取代)和class_weight(用于指定样本各类别的权重,以防止训练集某些类别的样本过多导致决策树过于偏向这些类别)等。
综上所述,决策树DecisionTreeClassifier的算法原理基于特征选择、决策树生成和剪枝等步骤,并通过多个重要参数来控制模型的复杂度和泛化能力。在实际应用中,需要根据具体的数据集和任务需求来选择合适的参数组合以获得最佳的模型性能。
|
min_samples_leaf: 叶子节点(即分类)最少样本数。 这个值限制了叶子节点最少的样本数, 如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认值为1。 控制了叶子节点上样本的数量,不能过少, 就控制了树的复杂度,不会太过于复杂 |
|
|
|
|
超参数优化
https://baijiahao.baidu.com/s?id=1744930364412914924&wfr=spider&for=pc
|
|
2的0次方+2的1次方+2的2次方+...2的n次方的公式是什么 
2**6=64
2**7=128
通常机器学习中的特征列到不了128,所以max_depth取6就算大的了
max_depth 是指决策树的最大深度,即从根节点到最远叶子节点的最长路径上的节点数。
这个参数主要是用来控制决策树的复杂度,防止模型过拟合。
关于如何根据特征的个数设计 max_depth 的值,这并没有一个固定的规则,
因为最优的 max_depth 取决于数据的具体分布和特性。
但是,有一些通用的策略可以考虑:
开始时不设置 max_depth:
开始时可以让决策树自由生长,不设置 max_depth,观察模型的性能。如果模型过拟合,那么可以考虑设置 max_depth 来简化模型。
根据特征数量尝试不同的 max_depth:
可以尝试设置 max_depth 为特征数量的不同比例,比如特征数量的平方根、对数等,然后观察模型的性能变化。
使用交叉验证:
使用交叉验证来评估不同的 max_depth 对模型性能的影响,从而选择最优的 max_depth。
考虑数据的特性:
如果数据具有很多噪声或者异常值,可能需要设置较小的 max_depth 来防止模型过拟合。相反,如果数据很干净,可以尝试较大的 max_depth。
结合其他参数:
max_depth 只是决策树的一个参数,还可以结合其他参数(如 min_samples_split、min_samples_leaf 等)来共同控制模型的复杂度。
总之,设计 max_depth 的值需要根据具体的数据和任务来尝试和调整,通过交叉验证和模型评估来选择最优的参数组合。
|
|
|
|
|
|
决策树算法
决策树算法中的CART(Classification and Regression Trees)回归树
基本概念 CART回归树是一种用于回归问题的决策树模型。 它采用二分递归分割技术,将当前的样本集分为两个子样本集, 使得生成的每个非叶子节点都有两个分支。 因此,CART算法生成的决策树是结构简洁的二叉树。 特征选择
从数据集中选择一个最优特征,用于划分数据集。
最优特征的选择基于某种准则,如最小平方残差。
对于连续变量,需要将其离散化处理。
通常的做法是按照样本取值大小进行排序,
然后取两个连续取值的中点作为切分点,将数据集划分为两个子集。
决策树生成
根据选定的最优特征和切分点,将数据集划分为两个子集。
递归地在每个子集上重复上述过程,
直到满足停止条件(如子集大小小于某个阈值、混杂度的最大下降值小于一个预先指定的值等)。
在这个过程中,每个非叶子节点都会选择一个最优特征和切分点,
将数据集划分为两个子集,并分别递归地构建左右子树。
预测值计算
对于回归树,每个叶子节点都会计算一个预测值,
该预测值通常是该叶子节点上所有样本目标变量的均值或中位数。
当新样本输入到回归树中时,
它会根据节点的特征和切分点被递归地划分到某个叶子节点上,
然后该叶子节点的预测值就是该样本的预测结果。
剪枝策略
为了避免过拟合,CART回归树通常需要进行剪枝操作。
剪枝的目的是删除一些不必要的子树或叶子节点,以提高模型的泛化能力。
剪枝策略通常包括预剪枝和后剪枝两种。
预剪枝:
在决策树生成过程中,通过提前设置停止条件来限制树的生长。
常见的停止条件包括子集大小小于某个阈值、混杂度的最大下降值小于一个预先指定的值等。
后剪枝:
在决策树生成后,通过某种准则来删除一些不必要的子树或叶子节点。
常见的后剪枝方法包括代价复杂度剪枝(Cost-Complexity Pruning)等。
这种方法通过计算每个非叶子节点的表面误差率增益值来选择是否需要剪枝。
优点与局限性
CART回归树具有计算简单、易于理解、可解释性强等优点。
它能够处理缺失值和异常值,并且既可以处理离散值也可以处理连续值。
然而,CART回归树也存在一些局限性,
如容易出现过拟合现象、对于复杂关系的学习能力有限等。
因此,在实际应用中需要根据数据集的特点和需求来选择合适的模型和参数。
综上所述,CART回归树的原理主要基于特征选择、决策树生成和剪枝策略等步骤。
通过递归地划分数据集并计算每个叶子节点的预测值,CART回归树能够实现对新样本的预测。
同时,为了避免过拟合和提高模型的泛化能力,通常需要进行剪枝操作。
|
|
ID3算法
ID3算法是决策树算法中较早的一种,它使用信息增益作为特征选择的标准。
ID3根据信息增益选择一个特征,之后剔除该特征进行递归计算;
CARD是根据某个指标选择一个特征将数据集分为两类,即生成左右两个子树,之后进行递归计算;
信息增益反映了在给定条件之后不确定性减少的程度,
特征取值越高意味着确定性越高,条件熵越小,则信息增益越大。
ID3算法倾向于选择取值多的属性,
因为它信息增益最大,这会造成构造结点时偏向分支较多的结点。
此外,ID3算法只能处理离散型变量,对样本缺失值比较敏感,且没有剪枝的过程。 C4.5算法 C4.5算法是ID3算法的一个改进版本。 它使用信息增益比来选择划分属性, 从而克服了ID3算法在选择属性时偏向选择取值多的属性的不足。 信息增益比是对信息增益的一种规范化,它考虑了特征本身的熵, 从而减少了取值多但实际分类效果不好的特征被选中的可能性。 此外,C4.5算法还能够处理连续数值特征,引入了剪枝技术,并可以处理不完整数据。 然而,C4.5算法的效率相对较低, 因为它在构造树的过程中需要对数据集进行多次的顺序扫描和排序。 |
|
随机森林(Random Forest)算法 随机森林(Random Forest)算法: 虽然随机森林不是单一的决策树算法, 但它基于决策树,并通过构建多个决策树来提高模型的准确性和稳定性。 随机森林算法在训练过程中随机选择特征和样本,从而减少了模型的过拟合风险。 随机森林算法具有强大的分类和回归能力,被广泛应用于各种机器学习场景中。 |
基尼(Gini)算法是决策树中的一种,特别是在构建分类决策树时, 基尼指数是衡量数据集分割纯度的一个重要指标。 基尼指数(Gini Index),也称为基尼不纯度(Gini Impurity), 是决策树算法中用于数据分割和特征选择的一个重要指标。 它衡量的是从数据集中随机选取两个样本,其类别标签不一致的概率。 基尼指数越小,数据集的纯度越高。 基尼指数是一个有效的衡量数据集不纯度的指标, 广泛应用于CART(Classification and Regression Trees)决策树算法中。 通过最小化基尼指数,决策树模型尝试提高数据分割的纯度,以此来构建更准确的分类模型。 基尼系数的计算公式为Gini(p) = 1 - Σ(pi)^2, 其中,p表示每个类别的概率,Σ表示对所有类别求和。 基尼系数的取值范围为0到1,0表示节点纯度最高,1表示节点最不纯。
在决策树的构建过程中,基尼系数被广泛应用于节点的选择。
具体来说,需要计算每个特征的划分点,
然后通过计算划分后的子节点的基尼系数,选择基尼系数最小的特征和划分点作为决策树的节点。
这一过程可以概括为:
对于每个特征,计算每个划分点的基尼系数,并选择基尼系数最小的划分点。
选择基尼系数最小的特征和划分点作为当前节点,将数据集划分成两个子集。
对于每个子集,重复步骤1和步骤2,直到满足终止条件(如节点纯度达到100%或达到最大深度)。
通过使用基尼系数进行决策树的节点选择,可以在构建决策树时有效地减少决策的错误率。
基尼系数能够对不同的特征进行比较,并找到最优的划分点,从而提高决策树的泛化能力。
总的来说,基尼算法在决策树中扮演着重要角色,
它通过衡量数据集的不纯度来帮助选择最优的特征和划分点,
从而构建出高效准确的决策树模型。
基尼算法在CART决策树中的应用 特征选择与节点划分: 在CART决策树算法中, 基尼指数(Gini Index)是一个重要的评价指标,特别是在处理分类问题时。 基尼指数用于衡量数据集的不纯度或混杂度, 通过计算数据集中随机选取的两个样本类别不一致的概率来得到。 在构建决策树的过程中, CART算法会遍历每个特征及其可能的划分点,计算划分后子集的基尼指数。 选择使基尼指数最小化的特征和划分点作为当前节点的划分规则, 从而将数据集划分为两个子集, 并递归地对这两个子集应用相同的过程,构建左右子树。 决策树构建: 使用基尼指数作为评价指标,CART算法能够构建出结构简洁、易于理解的二叉决策树。 这种树形结构在分类和回归问题中都具有广泛的应用。 CART决策树算法的特点 二分递归分割: CART算法是一种基于二分递归分割的贪婪算法, 它将当前样本划分为两个子样本,使得生成的每个非叶子节点都有两个分支。 这种二分结构使得CART决策树在处理复杂数据时更加高效。
处理分类与回归问题:
CART算法既可以用于分类问题,也可以用于回归问题。
对于分类问题,通常使用基尼指数作为评价指标;
对于回归问题,则使用平方误差(Squared Error)作为评价指标。
剪枝技术: 为了避免过拟合,CART算法使用剪枝技术来减小模型复杂度、提高泛化性能。 剪枝包括预先剪枝和后剪枝两种方式, 它们通过去掉一些不必要的子树或叶节点来优化决策树的结构。
基尼算法是CART决策树算法在处理 分类问题 时的一个重要组成部分。
它通过计算基尼指数来衡量数据集的不纯度,并帮助CART算法选择最优的特征和划分点来构建决策树。
同时,CART算法本身具有二分递归分割、处理分类与回归问题及剪枝技术等特点,
使得它在机器学习领域具有广泛的应用价值。
|
|
|
策略生成
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载乳腺癌数据集
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.DataFrame(data.target,columns=['label'])
y = y['label']
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(
max_depth=3,
min_samples_leaf=30
)
clf = clf.fit(X, y)
import matplotlib.pyplot as plt
import dtreeviz
import warnings
warnings.filterwarnings("ignore")
viz_model = dtreeviz.model(clf,
X_train=X,
y_train=y,
target_name='label',
feature_names=X.columns,
class_names={0:'good',1:'bad'},
)
v = viz_model.view(fancy=False)
v.show()
v.save("img.svg")

-----------------------------------------------------------------------------------------
|
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载乳腺癌数据集
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.DataFrame(data.target,columns=['target'])
Y = y['target']
from sklearn import tree
clf = tree.DecisionTreeClassifier(
max_depth=3,
min_samples_leaf=50
)
clf = clf.fit(X, Y)
import matplotlib.pyplot as plt
#设置图片的大小,想要清晰的可以设置的大点
plt.figure(figsize=(8,8),dpi=1000)
tree.plot_tree(clf)
plt.show()
# 保存矢量图格式(SVG)
plt.savefig('b.svg', format='svg', bbox_inches='tight')

注意该二叉树,如果按前序遍历的话,读取的顺序为
20,27,1, -2,-2,-2,7,-2,-2
-2 表示叶子节点
|
下面的代码使用乳腺癌训练决策树
```
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载乳腺癌数据集
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.DataFrame(data.target,columns=['target'])
Y = y['target']
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(
max_depth=3,
min_samples_leaf=50
)
clf = clf.fit(X, Y)
```
通过下面的代码可以查看决策树实例clf的属性/方法有
```
[x for x in dir(clf.tree_) if not x.startswith('_')]
```
['apply',
'capacity',
'children_left',
'children_right',
'compute_feature_importances',
'compute_node_depths',
'compute_partial_dependence',
'decision_path',
'feature',
'impurity',
'max_depth',
'max_n_classes',
'missing_go_to_left',
'n_classes',
'n_features',
'n_leaves',
'n_node_samples',
'n_outputs',
'node_count',
'predict',
'threshold',
'value',
'weighted_n_node_samples']
clf.tree_.children_left # array([ 1, 2, 3, -1, -1, -1, 7, -1, -1], dtype=int64)
clf.tree_.children_right #array([ 6, 5, 4, -1, -1, -1, 8, -1, -1], dtype=int64)
clf.tree_.feature #array([20, 27, 1, -2, -2, -2, 7, -2, -2], dtype=int64)
clf.tree_.capacity #9
clf.tree_.threshold #array([16.79500008, 0.13265 , 21.43499947, -2. , -2. , -2. , 0.1527 , -2. , -2. ])
clf.tree_.value
array([[[0.37258348, 0.62741652]],
[[0.08707124, 0.91292876]],
[[0.01519757, 0.98480243]],
[[0.00371747, 0.99628253]],
[[0.06666667, 0.93333333]],
[[0.56 , 0.44 ]],
[[0.94210526, 0.05789474]],
[[0.78 , 0.22 ]],
[[1. , 0. ]]])
clf.tree_.impurity #array([0.46753006, 0.15897968, 0.0299332 , 0.00740731, 0.12444444, 0.4928 , 0.10908587, 0.3432 , 0. ])
clf.tree_.n_node_samples #array([569, 379, 329, 269, 60, 50, 190, 50, 140], dtype=int64)
clf.tree_.n_leaves #5
clf.node_count #9
|
- children_left:当前节点的左子节点的索引列表 - children_right:当前节点的右子节点的索引列表 - feature: 特征索引,代表了当前节点用于分裂的特征索引列表 - threshold:分裂阈值列表,一般是≤该阈值时进入左子节点,否则进入右子节点 - n_node_samples:训练时落入到该节点的样本总数 children_left与children_right要结合起来看 - 数组长度为9,表示整棵树有9个节点 - 第i个节点的左子节点为children_left[i-1],其右子节点为children_right[i-1] - -1表示该节点为叶子节点 分裂举例 # 根节点按索引20,阈值16.79500008进行分裂 data = np.array(X) label = np.array(Y) label[data[:,20]<= clf.tree_.threshold[0]]
array([0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1,
0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1])
clf.feature_importances_
array([0. , 0.00181031, 0. , 0. , 0. ,
0. , 0. , 0.01660564, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.86161465, 0. , 0. , 0. , 0. ,
0. , 0. , 0.1199694 , 0. , 0. ])
分裂节点有4个,下面的特征重要性大于0的特征个数刚好为4
- 其余5个节点为叶子节点
clf.tree_.value
clf.tree_.value,clf.tree_.value.shape
(array([[[0.37258348, 0.62741652]],
[[0.08707124, 0.91292876]],
[[0.01519757, 0.98480243]],
[[0.00371747, 0.99628253]],
[[0.06666667, 0.93333333]],
[[0.56 , 0.44 ]],
[[0.94210526, 0.05789474]],
[[0.78 , 0.22 ]],
[[1. , 0. ]]]),
(9, 1, 2))
整棵树9个节点,用了9个节点
- 每个节点有2个元素,代表类别 [0,1]的概率
clf.tree_.n_features,clf.tree_.n_node_samples
(30, array([569, 379, 329, 269, 60, 50, 190, 50, 140], dtype=int64))
>>> round(569*0.37258348)
212
>>> round(329*0.01519757)
5
>>> round(269*0.00371747)
1
a = node_samples[:,np.newaxis,np.newaxis]
p_value = clf.tree_.value
value = np.round(a*p_value).astype(np.int64)
value
array([[[212, 357]],
[[ 33, 346]],
[[ 5, 324]],
[[ 1, 268]],
[[ 4, 56]],
[[ 28, 22]],
[[179, 11]],
[[ 39, 11]],
[[140, 0]]])
所有叶子节点的样本数之和,就是训练数据的个数 (clf.tree_.n_node_samples[clf.tree_.feature ==-2]).sum(),X.shape (569, (569, 30)) |
我现在需要帮用户解释sklearn决策树模型中clf.tree_各个属性和方法的含义,
并结合他们提供的具体数值进行说明。
用户给出了一段代码,训练了一个决策树分类器,
然后列出了clf.tree_的一些属性和对应的值,比如children_left、children_right、feature等,还有他们的具体数值示例。
首先,我需要回忆一下sklearn的决策树结构。
决策树在内部是用二叉树的结构存储的,每个节点都有左右子节点。
对于每个节点,feature属性表示分裂时使用的特征索引,threshold是分裂的阈值。
如果某个节点是叶子节点,那么它的左右子节点索引会是-1。
children_left和children_right数组分别存储每个节点的左右子节点索引。
接下来,用户提供的clf.tree_.children_left和children_right的值分别是
[1,2,3,-1,-1,-1,7,-1,-1]和
[6,5,4,-1,-1,-1,8,-1,-1]。
这说明根节点0的左子节点是1,右子节点是6。
而节点3、4、5、7、8是叶子节点,因为它们左右子节点都是-1。
node_count是9,说明总共有9个节点,n_leaves是5,对应5个叶子节点。
这里可能有些节点虽然只有一个子节点,但根据参数设置(如min_samples_leaf)可能被合并或处理过。
然后是feature数组,用户提供的例子中根节点0使用的特征索引是20,对应数据中的某个特征。
threshold数组中的值对应分裂的阈值。
比如根节点的阈值是16.795,可能表示当特征20的值小于等于这个阈值时进入左子节点,否则进入右子节点。
value数组的结构是三维的,每个节点有一个二维数组,可能对应每个类别的样本数量或比例。
用户例子中的value数组显示每个节点的样本分布,比如根节点有大约37.25%的样本属于类别0,62.75%属于类别1。
叶子节点的value可能更倾向于某一类别,比如最后一个节点的value是[1.0, 0.0],说明该叶子节点所有样本都属于类别0。
impurity数组显示每个节点的不纯度,根节点的不纯度最高,随着树的加深,不纯度降低。
叶子节点的不纯度应该是0,但用户例子中的最后一个节点的impurity为0,
而其他叶子节点可能由于参数设置(如min_samples_leaf=50)导致不纯度不为零,或者可能存在缺失值处理的情况。
n_node_samples数组显示每个节点的样本数量,根节点有569个样本,随着分裂逐渐分配到子节点。
比如节点1有379个样本,节点6有190个样本,这可能说明在根节点分裂后,大部分样本进入了左子树。
接下来,我需要将这些属性和方法逐一解释清楚,结合用户提供的数值示例。
比如children_left和children_right表示节点的左右子节点索引,
feature和threshold决定分裂条件,value表示节点的类别分布,impurity是节点的不纯度,
n_node_samples是节点中的样本数,n_leaves是叶子节点数量,node_count是总节点数。
而capacity可能是指树的总容量,即预分配的节点数量,但需要确认。
还有一些方法,如apply、decision_path、predict等,
这些方法用于样本的预测路径或应用树的结构进行预测。
需要解释这些方法的作用,比如apply返回每个样本所在的叶子节点索引,
decision_path返回样本经过的节点路径。
需要注意的是,用户提供的参考资料中并没有直接解释这些属性,所以主要依赖我已有的知识
。参考资料中的摘要主要涉及决策树的应用,但可能没有详细解释内部属性。
因此,我需要确保我的解释准确,特别是结合用户给出的具体数值来举例说明每个属性的意义,
比如用具体的数组元素来解释children_left和children_right如何构建树结构,
feature数组中的-2可能表示叶子节点,但sklearn中通常用-1或-2来标记。
需要确认这些索引的具体含义,可能用户代码中的feature数组中的-2代表该节点是叶子节点,
而根据sklearn文档,内部节点分裂特征为负数时表示该节点是叶子节点。
不过可能需要查阅sklearn的_tree.Tree的文档,但此时无法访问外部资源,只能依靠记忆。
最后,确保回答符合用户的要求:
使用专业语言,不直接引用参考资料,结合具体数值解释每个属性和方法,结构清晰,分点说明。
例如,每个属性单独列出,解释含义,然后结合用户给出的示例值进行说明,
如children_left数组中的元素对应每个节点的左子节点索引,-1表示无左子节点(即叶子节点)等。
以下是对决策树实例clf.tree_属性及方法的专业解释,结合具体数值分析其功能:
1. **children_left/children_right**
存储每个节点的左右子节点索引数组。示例中children_left=[1,2,3,-1,-1,-1,7,-1,-1]表示:
- 根节点0的左子节点为1,右子节点为6(children_right[0]=6)
- 索引为3/4/5/7/8的节点值为-1,说明这些节点为叶子节点
- 树结构为二叉树,总节点数由node_count=9定义
2. **feature**
记录每个非叶子节点用于分裂的特征索引。示例feature=[20,27,1,-2,...]显示:
- 根节点0使用第20号特征(对应数据集的'worst radius'特征)
- 索引为-2表示该节点为叶子节点(如索引3/4等)
3. **threshold**
存储每个节点的分裂阈值。示例threshold=[16.795,0.13265,...]说明:
- 根节点0的分裂条件为特征20 ≤ 16.795时进入左子节点1,否则进入右子节点6
- 叶子节点阈值固定为-2
4. **value**
三维数组存储每个节点的类别分布。示例value[0]=[[0.3725,0.6274]]表示:
- 根节点0包含37.25%阴性样本(类别0),62.75%阳性样本(类别1)
- 最终叶子节点8的value=[[1.0,0.0]]表明该节点样本全为阴性
5. **impurity**
节点不纯度指标(基尼系数)。示例impurity=[0.4675,0.1589,...]显示:
- 根节点不纯度最高(0.4675),随着分裂逐步降低
- 叶子节点不纯度应为0,但参数min_samples_leaf=50允许非纯叶子存在
6. **n_node_samples**
每个节点包含的样本数量。示例n_node_samples=[569,379,...]验证:
- 根节点包含全部569个样本
- 节点1分裂后包含379样本,节点6包含190样本(569-379=190)
7. **n_leaves/node_count**
n_leaves=5表示5个终端节点,node_count=9说明总节点数为9,符合二叉树节点数=2n_leaves-1的规律
8. **capacity**
预分配的树结构存储容量,本例capacity=9与node_count相等,说明内存已完全利用
9. **方法功能**
- `apply()`: 返回每个样本最终到达的叶子节点索引
- `decision_path()`: 生成样本决策路径的稀疏矩阵
- `predict()`: 基于树结构进行类别预测
- `compute_feature_importances()`: 计算特征重要性分数
该决策树通过max_depth=3限制树深,min_samples_leaf=50强制每个叶子至少包含50个样本,
最终生成包含9个节点(5个叶子)的分类模型。
特征重要性可通过特征索引与`clf.feature_importances_`关联分析。
clf.feature_importances_
array([0. , 0.00181031, 0. , 0. , 0. ,
0. , 0. , 0.01660564, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.86161465, 0. , 0. , 0. , 0. ,
0. , 0. , 0.1199694 , 0. , 0. ])
|
import numpy as np import pandas as pd from sklearn.datasets import load_breast_cancer # 加载乳腺癌数据集 data = load_breast_cancer() X = pd.DataFrame(data.data, columns=data.feature_names) y = pd.DataFrame(data.target,columns=['target']) from tpf.link.tree import Decision dcs = Decision() df = dcs.rules(X=X,y=y,max_depth=5) df 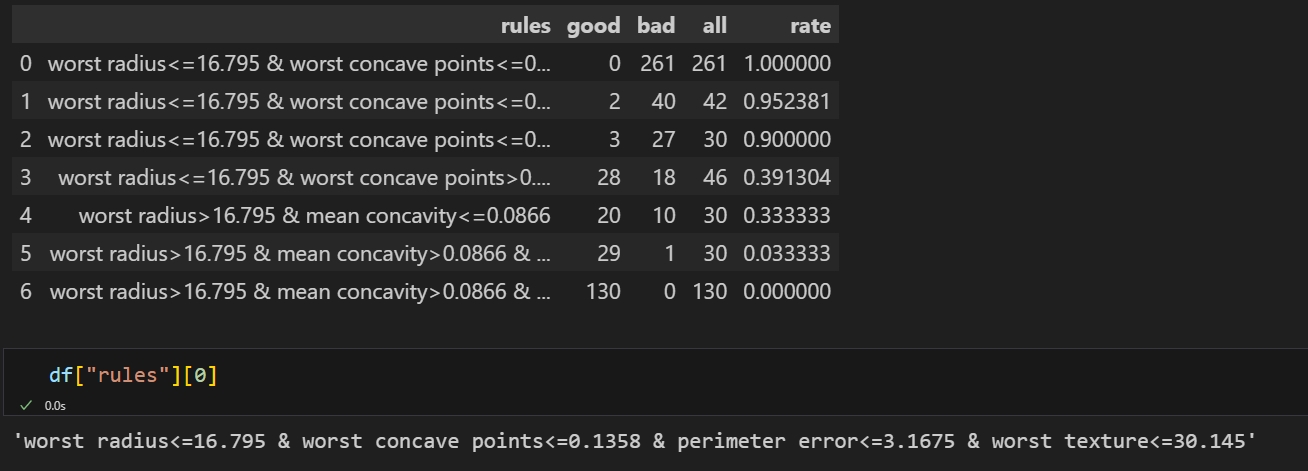
|
参考
sklearn2pmml github
PMML讲解及使用